El seguro de vida es algo que todos esperamos no necesitar, pero como sabemos, la vida es impredecible. En este artículo, nos centraremos en formular un modelo de datos que una compañía de seguros de vida puede usar para almacenar su información.
El seguro de vida como concepto
Antes de comenzar a discutir el modelo de datos real para una compañía de seguros de vida, recordaremos brevemente qué es un seguro y cómo funciona para que tengamos una mejor idea de con qué estamos trabajando.
El seguro es un concepto bastante antiguo que se remonta incluso antes de la Edad Media, cuando muchos gremios ofrecían pólizas para proteger a sus miembros en situaciones inesperadas. Incluso el famoso astrónomo, matemático, científico e inventor Edmund Halley incursionó en los seguros, trabajando en estadísticas y tasas de mortalidad que formaron la columna vertebral de los modelos de seguros modernos.
¿Por qué debería pagar un seguro? La idea es bastante simple:usted paga una cierta cantidad (la prima) a cambio de la garantía de la compañía de seguros de que usted o su familia serán compensados financieramente si le sucede algo inesperado a usted o a su propiedad. En el caso de una póliza de seguro de vida, usted designa un beneficiario que recibirá una suma de dinero (el beneficio) en caso de su muerte. La idea es que este dinero les ayude a recuperarse de su pérdida, especialmente si su muerte crea algún problema financiero.
Por supuesto, las compañías de seguros generalmente pagan mucho menos en beneficios de lo que ganan con las primas y con la inversión de su dinero, por ejemplo, en el mercado de valores. ¡De lo contrario, irían a la quiebra y todo el sistema se vendría abajo!
Eso es más o menos la esencia de esto. Ahora que lo hemos solucionado, sigamos adelante y echemos un vistazo al modelo de datos de una compañía de seguros de vida típica.
El modelo de datos:descripción general
El modelo de datos con el que trabajaremos consta de cinco áreas temáticas:
- Empleados
- Productos
- Clientes
- Ofertas
- Pagos
Cubriremos cada una de estas secciones con mayor detalle, en el orden en que aparecen arriba.
Área Temática #1:Empleados
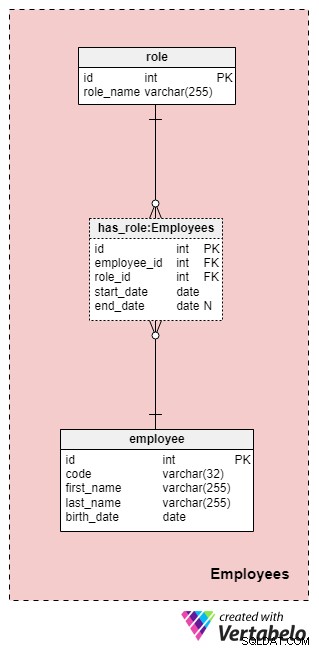
Esta área no es necesariamente específica para este modelo de datos, pero sigue siendo muy importante porque las tablas contenidas aquí serán referenciadas por otras áreas temáticas. A los efectos de nuestro modelo de datos de la compañía de seguros, por supuesto, necesitaremos saber quién realizó qué acción (por ejemplo, quién representó a nuestra empresa cuando trabajó con el cliente, quién firmó la póliza, etc.).
La lista de todos los empleados de la empresa se almacena en el employee mesa. Para cada empleado, almacenaremos la siguiente información:
code— una clave única que identifica a un solo empleado. Dado que el código se utilizará como atributo en otras tablas, servirá como clave alternativa en esta tabla.first_nameylast_name— el nombre y apellido del empleado, respectivamente.birth_date— la fecha de nacimiento del empleado.
Por supuesto, ciertamente podríamos incluir muchos otros atributos relacionados con los empleados en esta tabla, pero estos cuatro son más que suficientes por ahora. Seguiremos este patrón a lo largo del artículo e intentaremos mantener las cosas lo más simples posible, pero tenga en cuenta que definitivamente puede expandir este modelo de datos para incluir información adicional.
Dado que los empleados pueden cambiar sus roles en nuestra empresa en cualquier momento, necesitaremos una tabla de diccionario para representar los roles de la empresa y una tabla para almacenar valores. La lista de todos los roles posibles que los empleados pueden asumir en nuestra compañía de seguros de vida se almacena en el role diccionario. Solo tiene un atributo llamado role_name que contiene valores de identificación únicos.
Relacionaremos empleados y roles usando el has_role mesa. Además de las claves foráneas employee_id y role_id , almacenaremos dos valores:start_date y end_date . Estos dos valores denotan el rango en el que este rol de empresa estuvo activo para un empleado en particular. La end_date contendrá un valor de nulo hasta que se haya determinado una fecha de finalización para el rol de este empleado. La clave alternativa para esta tabla es la combinación de employee_id , role_id y start_date . Para evitar duplicar el mismo rol para el mismo empleado, tendremos que verificar programáticamente si hay superposiciones cada vez que agreguemos un nuevo registro a la tabla o actualicemos uno existente.
Área temática n.° 2:Productos
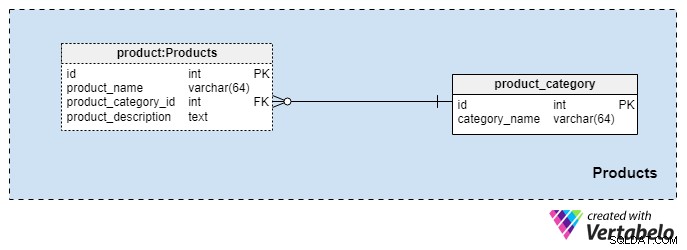
Esta área temática es bastante pequeña y solo contiene dos tablas. Los valores de estas tablas son requisitos previos para nuestras otras áreas temáticas, por lo que los analizaremos brevemente.
La product_category El diccionario almacena las categorías más generales de productos que planeamos ofrecer a nuestros clientes. El único valor que almacenaremos en esta tabla es el único category_name para indicar el tipo de seguro que ofrecemos, que podría ser un seguro de vida personal, un seguro de vida familiar, etc.
Clasificaremos nuestros productos aún más usando el product mesa. Esta tabla representa los productos reales que vendemos y no sus categorías. Como puedes imaginar, podemos agrupar productos por duración (por ejemplo, 10 o 20 años, o incluso toda la vida). Si elegimos hacerlo, es probable que tengamos productos con el mismo product_category_id pero diferentes nombres y descripciones. Para cada producto, almacenaremos la siguiente información básica:
product_name— el nombre de este producto. Se utiliza como clave alternativa para esta tabla en combinación con elproduct_category_idatributo. Es poco probable que tengamos dos productos con el mismo nombre que pertenezcan a diferentes categorías, pero es una posibilidad.product_category_id— identifica la categoría a la que pertenece este producto.product_description— descripción textual de este producto.
Área temática n.° 3:Clientes
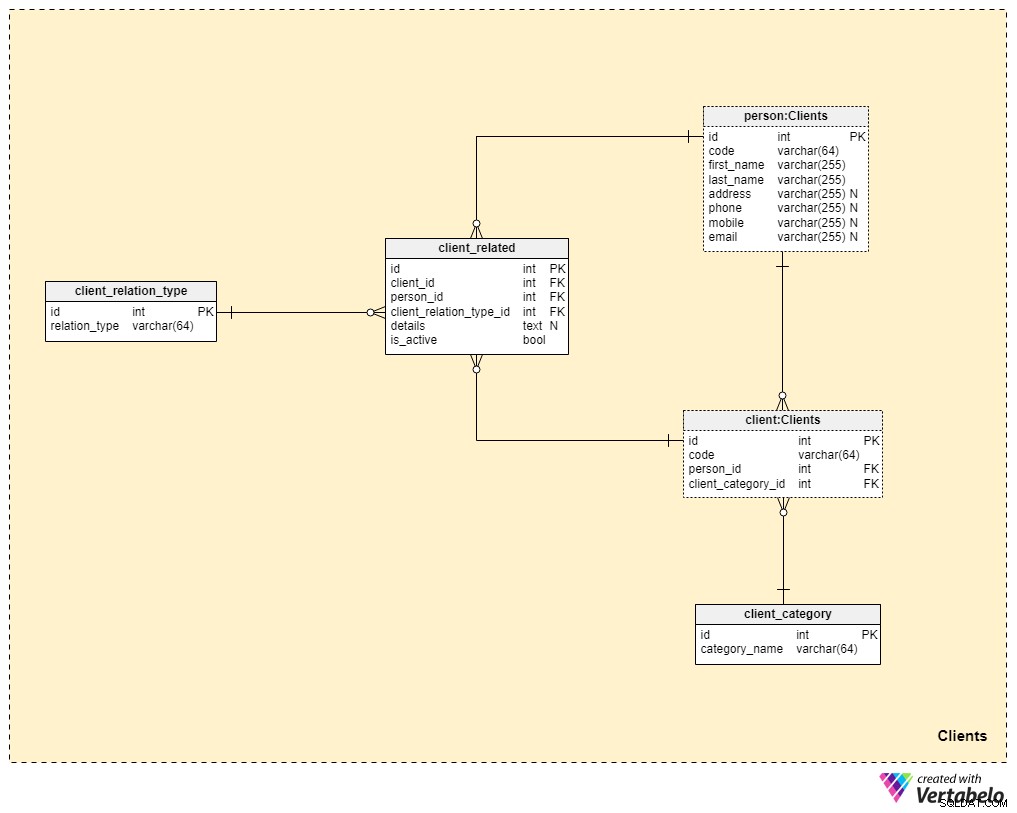
Ahora nos estamos acercando mucho más al núcleo de nuestro modelo de datos, pero aún no hemos llegado allí. El seguro de vida es único porque una póliza se puede transferir a un miembro de la familia o a otra persona, mientras que las pólizas para otras formas de seguro (como el seguro de salud o el seguro de automóvil) pertenecen a un solo cliente y no se pueden transferir. Por este motivo, necesitaremos almacenar no solo información sobre el cliente al que pertenece la póliza, sino también información sobre cualquier persona relacionada y su relación con el cliente.
Comenzaremos con el client mesa. Para cada cliente, almacenaremos el código único generado o insertado manualmente para ese cliente, así como las claves externas que referencian la tabla con sus datos personales (person_id ) y la tabla que contiene nuestra categorización interna (client_category_id ).
La client_category El diccionario nos permite agrupar a los clientes en función de sus datos demográficos y financieros. Las categorías de clientes se utilizarán para determinar la póliza de seguro que estamos listos para ofrecer a un cliente en particular. Aquí, solo almacenaremos una lista de valores únicos que luego asignaremos a los clientes.
Dado que estamos hablando de un seguro de vida, supondremos que un cliente es un solo individuo. Sin embargo, como mencionamos anteriormente, puede haber otras personas relacionadas con el cliente a quienes se les puede transferir la póliza o que pueden recibir el beneficio de la póliza al fallecer el cliente. Por este motivo, hemos creado una person mesa. Para cada registro de esta tabla, almacenaremos la siguiente información:
code— un valor generado automáticamente o insertado manualmente que se utiliza para identificar de forma única a la persona relacionada.first_nameylast_name— el nombre y apellido de la persona, respectivamente.address,phone,mobileyemail— detalles de contacto de esta persona, todos los cuales contienen valores arbitrarios.
Las dos tablas restantes en esta área temática son necesarias para describir la naturaleza de la relación entre los clientes y otras personas.
La lista de todos los tipos de relaciones posibles se almacena en el client_relation_type diccionario. Al igual que con otros diccionarios, este contendrá una lista de nombres únicos que luego usaremos al describir la relación entre un cliente en particular y otra persona.
Los datos reales de la relación se almacenan en el client_related mesa. Para cada registro de esta tabla, almacenaremos referencias al cliente (client_id ), la persona relacionada (person_id ), la naturaleza de esa relación (client_relation_type_id ), todos los detalles adicionales (details ), si existe, y una bandera que indica si la relación está actualmente activa (is_active ). La clave alternativa en esta tabla está definida por la combinación de client_id , person_id y client_relation_type_id .
Área temática n.° 4:Ofertas
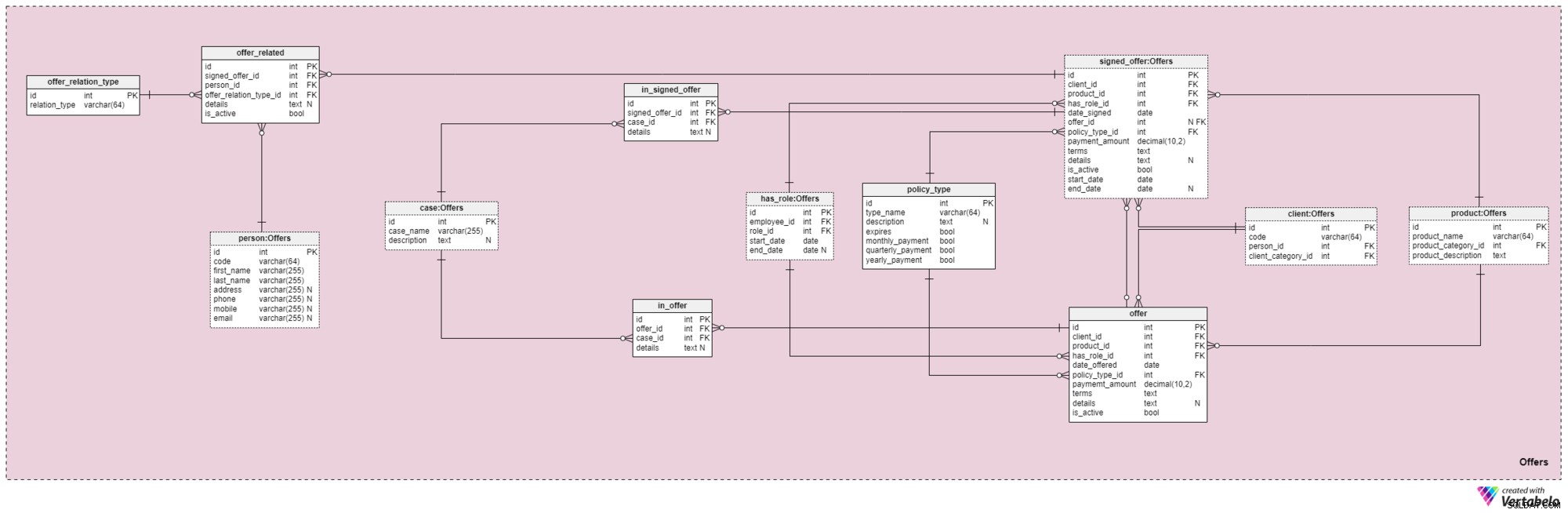
Esta área temática y la que sigue están en el corazón de este modelo de datos. Cubren ofertas y pólizas firmadas, así como pagos relacionados con ofertas. Primero, describiremos el área temática Ofertas. Puede parecer complejo porque contiene 12 tablas. Sin embargo, cuatro de estos 12 (has_role , product , client y person ) se describieron en áreas temáticas anteriores, por lo que no repetiremos nuestra discusión aquí.
La offer y signed_offer las tablas tienen estructuras similares porque se utilizarán para almacenar datos muy similares en nuestro modelo. Sin embargo, mientras offer se usará principalmente para almacenar cualquier póliza (y sus detalles) que hayamos ofrecido a nuestros clientes, la signed_offer La tabla se utilizará estrictamente para almacenar información sobre los clientes que efectivamente han firmado pólizas con nuestra empresa. Cubriremos estas tablas juntas, observando las diferencias donde aparecen. Los atributos en estas dos tablas son los siguientes:
client_id— referencia al identificador único del cliente que firmó una oferta en particular.product_id— referencia al identificador único del producto que se incluyó en la oferta firmada.has_role_id— referencia a la identificación del empleado y la función que desempeñaba en el momento en que se presentó/firmó la oferta.date_offeredydate_signed— fechas reales que indican cuándo se presentó esta oferta al cliente y cuándo se firmó, respectivamente.offer_id— una referencia a la oferta anterior para este cliente. Esto puede contener un valor de nulo porque el cliente podría haber firmado una póliza sin tener ninguna oferta previa de la compañía, como si se acercara a nosotros por su cuenta. Este atributo pertenece estrictamente asigned_offermesa.policy_type_id— referencia al diccionario de tipo de póliza que indica el tipo de póliza que le ofrecemos al cliente o que firmamos.payment_amount— la cantidad que el cliente debe pagar por la póliza de manera regular.terms— todos los términos del acuerdo, en formato textual (XML). La idea es almacenar todos los detalles importantes relacionados con la parte financiera de la póliza en este atributo. Ejemplos de texto que podríamos almacenar son el monto total de la póliza, la cantidad de pagos que el cliente debe realizar, etc.details— cualquier detalle adicional, en formato de texto.is_active— indicador que indica si el registro aún está activo.start_dateyend_date— indicar el intervalo de tiempo en el que esta política está/estuvo activa. Si la política se firmó para toda la vida, end_date contendrá un valor nulo.
También está el policy_type diccionario que mencionamos brevemente antes. Necesitamos cierto grado de flexibilidad en la forma en que ofrecemos el mismo producto a diferentes clientes, en función de factores como la edad, la salud, el estado civil, el riesgo crediticio, etc. Para cada tipo de política, almacenaremos un type_name identificador, una description textual adicional , un indicador llamado expira que indica si la póliza puede vencer y otro indicador que indica si las primas de este tipo de póliza deben pagarse mensual, trimestral o anualmente. Algunos tipos de póliza esperados son:vida a término, vida entera, vida universal, vida universal garantizada, vida variable, vida universal variable y seguro de vida después de la jubilación.
Continuando, ahora necesitamos definir todos los casos y situaciones que puede cubrir una póliza en particular. Necesitamos relacionar estos casos con ofertas específicas y ofertas firmadas.
La lista de todos los casos posibles que cubren nuestras pólizas se almacena en el case diccionario. Cada registro en esta tabla se puede identificar de forma única por su case_name y tiene una description adicional , si es necesario.
El in_offer y in_signed_offer las tablas comparten la misma estructura porque almacenan los mismos datos. La única diferencia entre los dos es que el primero almacena casos cubiertos en la póliza que simplemente se ofreció al cliente, mientras que el segundo almacena casos en la póliza firmada por el cliente. Para cada registro en estas dos tablas, almacenaremos el par único de offer_id /signed_offer_id y case_id , el último de los cuales denota el caso o siniestro cubierto por la póliza. Todos los demás detalles se almacenarán en un atributo textual, si es necesario.
Como mencionamos anteriormente, las pólizas de seguro de vida casi siempre están relacionadas no solo con los clientes sino también con sus familiares o parientes. Necesitamos almacenar estas relaciones en esta área también. Se definirán en el momento en que se firme una póliza, pero también podrían modificarse a lo largo de la vigencia de la póliza.
Lo primero que debemos hacer es crear un diccionario que contenga todos los valores posibles que se pueden asignar a una relación. En nuestro modelo, este es el offer_relation_type diccionario. Aparte de la clave principal, esta tabla solo contiene un atributo:el relation_type – que solo puede contener valores únicos.
¡Casi estámos allí! La última tabla de esta área temática se titula offer_related . Relaciona una oferta firmada a cualquier persona que tenga relación con el cliente. Por lo tanto, necesitaremos almacenar referencias a la política firmada (signed_offer_id ) y la persona relacionada (person_id ) y también especificar la naturaleza de esa relación (offer_relation_type_id ). Además, necesitaremos almacenar details relacionado con este registro y crear una bandera para verificar si todavía es válido en nuestro sistema.
Área temática n.º 5:Pagos
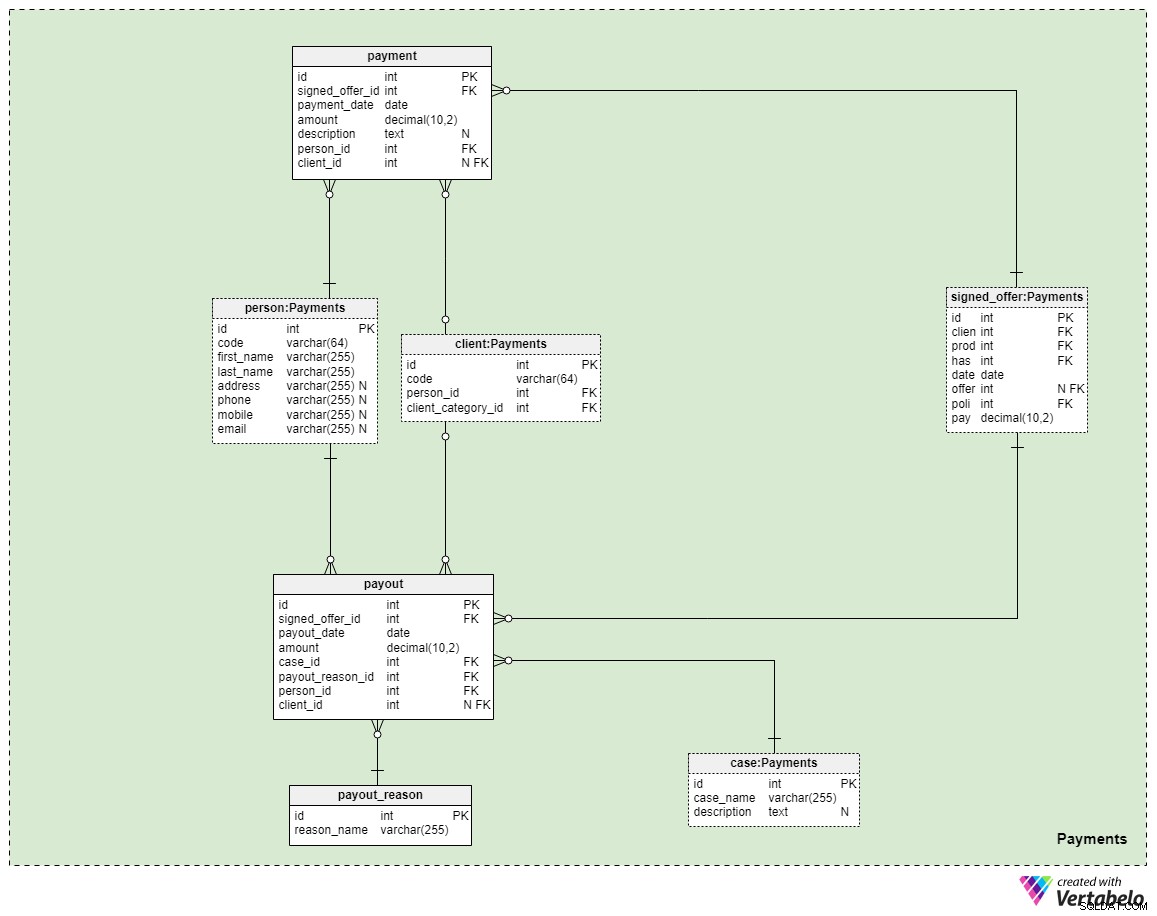
La última área temática de nuestro modelo se refiere a los pagos. Aquí, solo presentamos tres tablas nuevas:payment , payout_reason y payment .
Todos los pagos relacionados con las pólizas se almacenan en el payment mesa. Aquí solo incluimos los atributos más importantes:
signed_offer_id— referencia al identificador único de la oferta firmada (póliza).payment_date— la fecha en que se realizó este pago.amount— el monto real que se pagó.description— una descripción opcional del pago, en formato de texto.person_id— referencia al identificador único de la persona que realizó el pago. Tenga en cuenta que el cliente que firmó la oferta no es necesariamente la única persona que puede realizar un pago.client_id— referencia al identificador único del cliente que realizó el pago. Este atributo contendrá un valor solo si el cliente realizó el pago.
Las dos tablas restantes representan quizás la razón más importante por la que pagamos un seguro de vida:en caso de que algo nos suceda, los pagos se realizarán a nuestros familiares o socios comerciales o de vida. Cómo sucede esto depende de su situación y de los términos de la póliza específica que firmó. Usaremos dos tablas simples para cubrir estos casos.
El primero es un diccionario titulado payout_reason y presenta una estructura de diccionario clásica. Aparte del atributo de la clave principal, solo tenemos un atributo:el reason_name – que almacenará una lista de valores únicos que indican por qué se realizó este pago.
La última tabla del modelo es el payment mesa. Es muy similar al payment tabla, pero las diferencias más importantes se indican a continuación:
payout_date— la fecha en que se realizó el pago.case_id— referencia al identificador único del caso o incidente relacionado que desencadenó el pago. Esto debe coincidir con uno de los identificadores incluidos en la política.payout_reason_id— referencia al diccionario que describe el motivo del pago con mayor detalle. Si bien el caso de pago es más corto y más general, el motivo del pago ofrecerá detalles más específicos sobre lo que sucedió.person_idyclient_id— hace referencia a la persona y al cliente relacionados con el pago, respectivamente.
Resumen
¡Impresionante! Hemos construido con éxito nuestro modelo de datos de seguros de vida. Antes de concluir nuestra discusión, vale la pena señalar que hay mucho más que se puede cubrir en este modelo. En este artículo, principalmente queríamos cubrir los conceptos básicos del modelo para darle una idea de cómo se ve y funciona. Aquí hay algunos detalles más que se podrían incorporar en dicho modelo de datos:
- Las actualizaciones de pólizas adicionales no están cubiertas en nuestro modelo actual (por ejemplo, si desea hacer ofertas anuales para pólizas existentes, no podrá hacerlo con esta estructura). Deberíamos agregar algunas tablas más para almacenar todos los cambios de política para las ofertas presentadas/firmadas.
- Todo el papeleo se omite intencionalmente. Por supuesto, habrá mucho papeleo asociado con una póliza de seguro de vida en particular, especialmente para el proceso de firma y los pagos. Podríamos adjuntar documentos que describan el estado del cliente en el momento en que se firmó la póliza y cualquier cambio en el camino, así como cualquier documento relacionado con los pagos.
- Este modelo no incorpora la estructura necesaria para el cálculo del riesgo de la póliza. Deberíamos tener todos los parámetros que necesitamos probar y cualquier rango que determine cómo el valor de un cliente afecta el cálculo general. Los resultados de estos cálculos deberían almacenarse para cada oferta y política firmada.
- La estructura de la factura en realidad es mucho más compleja que lo que cubrimos en el área temática de pagos. Ni siquiera mencionamos cuentas financieras en ninguna parte de nuestro modelo.
Claramente, el negocio de los seguros es bastante complejo. Solo discutimos un modelo de datos para seguros de vida en este artículo. ¿Puedes imaginar cómo evolucionaría este modelo de datos si fuéramos a dirigir una empresa que ofrece varios tipos de seguros diferentes? Sin duda, se necesitaría mucha planificación y pensamiento para presentar un modelo de datos organizado para una empresa de este tipo.
Si tiene alguna sugerencia o idea para mejorar nuestro modelo de datos, ¡no dude en hacérnosla saber en los comentarios a continuación!