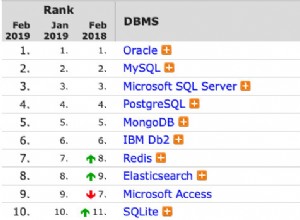
Durante los últimos años, las herramientas de base de datos NoSQL o no relacionales han ganado mucha popularidad en términos de almacenar una gran cantidad de datos y escalarlos fácilmente. Hay debates sobre si las bases de datos no relacionales reemplazarán a las bases de datos relacionales en el futuro. Con el creciente número de datos sociales y otros datos no estructurados, las siguientes son algunas de las preguntas que surgen en las bases de datos relacionales.
¿Son las bases de datos relacionales capaces de manejar big data?
¿Son las bases de datos relacionales capaces de escalar horizontalmente una cantidad masiva de cantidad de datos?
¿Son adecuadas las bases de datos relacionales para los datos de la era moderna?
Antes de responder a estas preguntas, conozcamos algunos conceptos básicos de las bases de datos relacionales y no relacionales.
Fundamentos de bases de datos relacionales y no relacionales
Bases de datos relacionales: El concepto de base de datos relacional se desarrolló en la década de 1970. La característica más importante de todas las bases de datos relacionales es su compatibilidad con las propiedades ACID (Automicidad, Consistencia, Aislamiento y Durabilidad) que asegura que todas las transacciones se procesen de manera confiable.
Automaticidad: Cada transacción es única y se asegura de que si una parte lógica de una transacción falla, todo se revierte para que los datos no cambien.
Coherencia: Todos los datos escritos en la base de datos están sujetos a las reglas definidas (restricciones, disparadores, etc.)
Aislamiento: Los cambios realizados en una transacción no son visibles para otras transacciones hasta que se confirman.
Durabilidad: Los cambios realizados en una transacción se almacenan y están disponibles en la base de datos incluso si se produce un corte de energía o si la base de datos se desconecta repentinamente.
Estrictamente estructurado: Los objetos en las bases de datos relacionales están estrictamente estructurados. Todos los datos de la tabla se almacenan en filas y columnas. Cada columna tiene un tipo de datos. Está mayormente normalizado. El lenguaje de consulta estructurado (SQL) es adecuado para que las bases de datos relacionales almacenen y recuperen datos de forma estructurada. Las consultas son comandos en inglés sencillo. Siempre hay un número fijo de columnas, aunque más adelante se pueden agregar columnas adicionales. La mayoría de las tablas están relacionadas entre sí con claves primarias y externas, lo que proporciona "integridad referencial" entre los objetos. Los principales proveedores son ORACLE, SQL Server, MySQL, PostgreSQL, etc.
Bases de datos no relacionales: El concepto de bases de datos no relacionales entró en escena para manejar el rápido crecimiento de los datos no estructurados y escalarlos fácilmente. Esto proporciona un esquema flexible, por lo que no existe tal cosa llamada "integridad referencial" como vemos en las bases de datos relacionales. Los datos están altamente desnormalizados y no requieren JOIN entre objetos. Esto relaja la propiedad ACID de las bases de datos relacionales y admite CAP (consistencia, disponibilidad y partición). Pero de estos tres, solo dos están garantizados en cualquier momento. Entonces, a diferencia de ACID, solo admitirá BASE (estado suave básicamente disponible, consistencia eventual). Las bases de datos iniciales creadas en base a estos conceptos son BigTable de Google, HBase de Yahoo, Cassandra de Facebook, etc.
Categorías de bases de datos no relacionales: Las bases de datos no relacionales se pueden clasificar en cuatro categorías principales, como la base de datos de valores clave, la base de datos de columnas, la base de datos de documentos y la base de datos de gráficos.
Base de datos de valores clave: Esta es la forma más simple de base de datos NoSQL donde cada valor está asociado con la clave única (por ejemplo, Redis)
Base de datos de columnas: Esta base de datos es capaz de almacenar y procesar una gran cantidad de datos utilizando un puntero que apunta a muchas columnas que se distribuyen en un clúster. (ex HBase)
Base de datos de documentos: Esta base de datos puede contener muchos documentos de clave-valor con muchos niveles anidados. La consulta eficiente es posible con esta base de datos. Los documentos se almacenan en formato JSON. (ex MongoDB)
Base de datos de gráficos: En lugar de filas y columnas tradicionales, esta base de datos utiliza nodos y bordes para representar estructuras gráficas y almacenar datos. (antes Neo4J)