Un evento recurrente, por definición, es un evento que se repite en un intervalo; también se llama un evento periódico. Hay muchas aplicaciones que permiten a sus usuarios configurar eventos recurrentes. ¿Cómo gestiona un sistema de base de datos los eventos recurrentes? En este artículo, exploraremos una forma en que se manejan.
La recurrencia no es fácil de manejar para las aplicaciones. Puede convertirse en una tarea difícil, especialmente cuando se trata de cubrir todos los escenarios recurrentes posibles, incluida la creación de eventos quincenales o trimestrales o la reprogramación de todas las instancias de eventos futuros.
Dos formas de administrar eventos recurrentes
Puedo pensar en al menos dos formas de manejar tareas periódicas en un modelo de datos. Antes de discutirlos, repasemos rápidamente los requisitos de esta tarea. En pocas palabras, una gestión eficaz significa:
- Los usuarios pueden crear eventos regulares y recurrentes.
- Se pueden crear eventos diarios, semanales, quincenales, mensuales, trimestrales, semestrales y anuales sin restricciones de fecha de finalización.
- Los usuarios pueden reprogramar o cancelar una instancia de un evento o todas las futuras instancias de un evento.
Teniendo en cuenta estos parámetros, se me ocurren dos formas de administrar eventos recurrentes en el modelo de datos. Los llamaremos la forma ingenua y la forma experta.
La manera ingenua: Almacenar todas las posibles instancias recurrentes de un evento como filas separadas en una tabla. En esta solución, solo necesitamos una tabla, a saber, event . Esta tabla tiene columnas como event_title , start_date , end_date , is_full_day_event , etc. La start_date y end_date las columnas son tipos de datos de marca de tiempo; de esta manera pueden acomodar eventos que no duran todo el día.
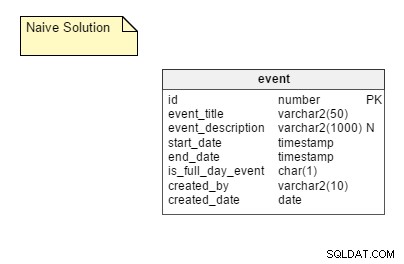
Los profesionales: Este es un enfoque bastante sencillo y el más simple de implementar.
Los contras: La forma ingenua tiene algunas desventajas significativas, que incluyen:
- La necesidad de almacenar todas las instancias posibles de un evento. Si tiene en cuenta las necesidades de una gran base de usuarios, se requiere una gran cantidad de espacio. Sin embargo, el espacio es bastante barato, por lo que este punto no tiene mayor impacto.
- Un proceso de actualización muy complicado. Supongamos que se reprograma un evento. En ese caso, alguien tiene que actualizar todas las instancias del mismo. Es necesario realizar una gran cantidad de operaciones DML al reprogramar, lo que crea un impacto negativo en el rendimiento de la aplicación.
- Manejo de excepciones. Todas las excepciones deben manejarse correctamente, especialmente si tiene que regresar y editar la cita original después de hacer una excepción. Por ejemplo, suponga que adelanta un día la tercera instancia de un evento recurrente. ¿Qué sucede si posteriormente edita la hora del evento original? ¿Vuelves a insertar otro evento en el día original y dejas el que adelantaste? ¿Desvincular la excepción? ¿Tratar de cambiarlo apropiadamente?
Event_id– Esta columna se refiere desde eleventtabla, y actúa como la clave principal en esta tabla. Muestra la relación de identificación entreeventyrecurring_patternmesas. Esta columna también garantizará que exista un máximo de un patrón recurrente para cada evento.Recurring_type_id– Esta columna indica el tipo de recurrencia, ya sea diaria, semanal, mensual o anual.Max_num_of_occurrances– Hay ocasiones en las que no sabemos la fecha exacta de finalización de un evento pero sabemos cuántas ocurrencias (reuniones) se necesitan para completarlo. Esta columna almacena un número arbitrario que define el final lógico de un evento.Separation_count– Puede que se pregunte cómo se puede configurar un evento quincenal o semestral si solo hay cuatro valores de tipo de recurrencia posibles (diario, semanal, mensual, anual). La respuesta es elseparation_countcolumna. Esta columna indica el intervalo (en días, semanas o meses) antes de que se permita la siguiente instancia de evento. Por ejemplo, si es necesario configurar un evento para cada dos semanas, entonces separation_count =“1” para cumplir con este requisito. El valor predeterminado para esta columna es "0".- El
recurring_type_idsería "semanal". - El
separation_countsería "1". - El
day_of_weeksería "2". Week_of_month– Esta columna es para eventos programados para una determinada semana del mes, es decir, el primero, el segundo, el último, el penúltimo, etc. Podemos almacenar estos valores como 1,2,3, 4,.. (contando desde el comienzo del mes) o -1,-2,-3,... (contando desde el final del mes).Day_of_month– Hay casos en que un evento está programado en un día particular del mes, digamos el 25. Esta columna cumple con este requisito. Me gustaweek_of_month, se puede completar con números positivos ("7" para el séptimo día desde el comienzo del mes) o números negativos ("-7" para el séptimo día desde el final del mes).- El
recurring_type_idsería "mensual". - El
separation_countsería "2". - El
day_of_monthsería "11". - Todas las columnas restantes serían nulas.
- Eventos que ocurren en días festivos. Cuando una instancia particular de un evento ocurre en un día festivo, ¿debe trasladarse automáticamente al día hábil inmediatamente posterior al día festivo? ¿O debería cancelarse automáticamente? ¿En qué circunstancias se aplicaría cualquiera de estos?
- Conflictos entre eventos. ¿Qué pasa si ciertos eventos (que son mutuamente excluyentes) caen el mismo día?
La Manera Experta: Almacenar un patrón recurrente y generar instancias de eventos pasados y futuros mediante programación. Esta solución aborda las desventajas de la solución ingenua. Explicaremos la solución experta en detalle en este artículo.
El modelo propuesto
Creación de eventos
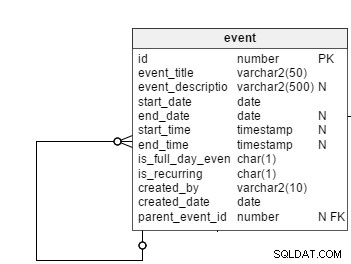
Todos los eventos programados, independientemente de su naturaleza regular o recurrente, se registran en el event mesa. No todos los eventos son eventos recurrentes, por lo que necesitaremos una columna indicadora, is_recurring , en esta tabla para especificar explícitamente eventos recurrentes. El event_title y event_description las columnas almacenan el tema y un breve resumen de los eventos. Las descripciones de eventos son opcionales, por lo que esta columna admite valores NULL.
Como sugieren sus nombres, el start_date y end_date las columnas mantienen las fechas de inicio y fin de los eventos. En el caso de eventos regulares, estas columnas almacenan las fechas reales de inicio y finalización. Sin embargo, también almacenan las fechas de las primeras y últimas ocurrencias de eventos periódicos. Mantendremos la end_date columna como anulable, ya que los usuarios pueden configurar eventos recurrentes sin fecha de finalización. En este caso, las ocurrencias futuras hasta una fecha de finalización hipotética (por ejemplo, durante un año) se mostrarían en la interfaz de usuario.
El is_full_date_event columna indica si un evento es un evento de día completo. En el caso de un evento de día completo, la start_time y end_time las columnas serían nulas; esa es la razón para mantener ambas columnas anulables.
El created_by y created_date las columnas almacenan qué usuario creó un evento y la fecha en que se creó.
A continuación está el parent_event_id columna. Esto juega un papel importante en nuestro modelo de datos. Más adelante explicaré su significado.
Administración de recurrencias
Ahora llegamos directamente al enunciado del problema principal:¿Qué sucede si se crea un evento recurrente en el event tabla – es decir, el is_recurring bandera para el evento es "Y"?
Como se explicó anteriormente, almacenaremos un patrón recurrente para eventos para que podamos construir todas sus ocurrencias futuras. Comencemos por crear el recurring_pattern mesa. Esta tabla tiene las siguientes columnas:
Consideremos la importancia de las columnas restantes en términos de los diferentes tipos de recurrencias.
Recurrencia diaria
¿Realmente necesitamos capturar un patrón para un evento recurrente diario? No, porque todos los detalles necesarios para generar un patrón de recurrencia diaria ya están registrados en el event mesa.
El único escenario que requiere un patrón es cuando los eventos están programados para días alternos o cada X número de días. En este caso, el separation_count nos ayudará a comprender el patrón de recurrencia y derivar más instancias.
Recurrencia semanal
Solo requerimos una columna adicional, day_of_week , para almacenar qué día de la semana tendrá lugar este evento. Suponiendo que el lunes sea el primer día de la semana y el domingo el último, los valores posibles serían 1, 2, 3, 4, 5, 6 y 7. Se deben realizar los cambios apropiados en el código que genera ocurrencias de eventos individuales según sea necesario. Todas las columnas restantes serían nulas para los eventos semanales.
Tomemos un tipo clásico de evento semanal:la ocurrencia quincenal. En este caso, diremos que ocurre cada semana alterna un martes, el segundo día de la semana. Entonces:

Recurrencia mensual
Además de day_of_week , necesitamos dos columnas más para cumplir con cualquier escenario de recurrencia mensual. En resumen, estas columnas son:
Consideremos ahora un ejemplo más complicado:un evento trimestral. Suponga que una empresa programa un evento de proyección de resultados trimestrales para el día 11 del primer mes de cada trimestre (generalmente enero, abril, julio y octubre). Así que en este caso:
En el ejemplo anterior, asumimos que el usuario está creando la proyección de resultados trimestrales en enero. Tenga en cuenta que esta lógica de separación comenzará a contar desde el mes, la semana o el día en que se crea el evento.
De manera similar, los eventos semestrales se pueden registrar como eventos mensuales con un
La recurrencia anual es bastante sencilla. Tenemos columnas para días particulares de la semana y el mes, por lo que solo requerimos una columna adicional para el mes del año. Hemos llamado a esta columna
Ahora pasemos a las excepciones. ¿Qué sucede si se cancela o reprograma una instancia particular de un evento recurrente? Todas estas instancias se registran por separado en
Echemos un vistazo a dos columnas,
Aparte de estas dos columnas, todas las columnas restantes actúan igual que en el
Existen aplicaciones que permiten a los usuarios reprogramar todas las instancias futuras de un evento recurrente. En tales casos, tenemos dos opciones. Podemos almacenar todas las instancias futuras en
Con esta solución, podemos obtener todas las ocurrencias pasadas de un evento, incluso cuando se haya cambiado su patrón de recurrencia.
Hay algunas áreas más complejas en torno a eventos recurrentes que no hemos discutido. Aquí hay dos:
¿Qué cambios necesitamos hacer para incorporar estas capacidades? Cuéntenos sus opiniones en la sección de comentarios.separation_count de “5”.
Recurrencia anual
month_of_year .
Manejo de excepciones de eventos recurrentes
event_instance_exception mesa. Is_rescheduled y is_cancelled . Estas columnas indican si esta instancia se reprograma para una fecha/hora posterior o si se cancela por completo. ¿Por qué tengo dos columnas separadas para esto? Bueno, solo piense en los eventos que primero se reprogramaron y luego se cancelaron por completo. Esto sucede, y tenemos una forma de registrarlo con estas columnas. event mesa.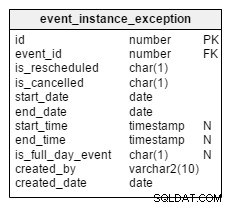
¿Por qué vincular dos eventos mediante
parent_event_id? ?event_instance_exception (pista:no es una solución aceptable). O podemos crear un nuevo evento con nuevos parámetros de fecha/hora en el event tabla y vincularlo con su evento anterior (el evento padre) por medio del id_parent_event columna. ¿Cómo mejorar el manejo de eventos recurrentes?