De vez en cuando, puede notar que una o más uniones en un plan de ejecución se anotan con un StarJoinInfo estructura. El esquema del plan de presentación oficial dice lo siguiente sobre este elemento del plan (haga clic para ampliar):
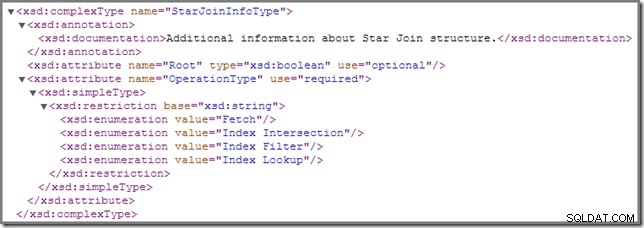
La documentación en línea que se muestra allí ("información adicional sobre la estructura Star Join ") no es tan esclarecedor, aunque los otros detalles son bastante intrigantes; los veremos en detalle.
Si consulta su motor de búsqueda favorito para obtener más información utilizando términos como "optimización de unión en estrella de SQL Server", es probable que vea resultados que describen filtros de mapa de bits optimizados. Esta es una función separada solo para empresas que se introdujo en SQL Server 2008 y no está relacionada con StarJoinInfo estructura en absoluto.
Optimizaciones para consultas selectivas de estrellas
La presencia de StarJoinInfo indica que SQL Server aplicó una de un conjunto de optimizaciones dirigidas a consultas selectivas de esquema en estrella. Estas optimizaciones están disponibles desde SQL Server 2005, en todas las ediciones (no solo Enterprise). Tenga en cuenta que selectivo aquí se refiere al número de filas extraídas de la tabla de hechos. La combinación de predicados dimensionales en una consulta aún puede ser selectiva incluso cuando sus predicados individuales califiquen una gran cantidad de filas.
Intersección de índice ordinario
El optimizador de consultas puede considerar combinar varios índices no agrupados cuando no existe un único índice adecuado, como demuestra la siguiente consulta de AdventureWorks:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
El optimizador determina que la combinación de dos índices no agrupados (uno en SalesPersonID y el otro en CustomerID ) es la forma más económica de satisfacer esta consulta (no hay índice en ambas columnas):
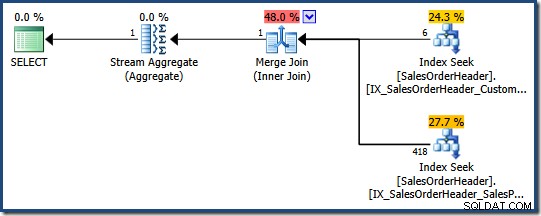
Cada búsqueda de índice devuelve la clave de índice agrupado para las filas que pasan el predicado. La combinación coincide con las claves devueltas para garantizar que solo las filas coincidan con ambas los predicados se transmiten.
Si la tabla fuera un montón, cada búsqueda devolvería identificadores de fila de montón (RID) en lugar de claves de índice agrupadas, pero la estrategia general es la misma:encontrar identificadores de fila para cada predicado y luego unirlos.
Intersección de índice de unión en estrella manual
La misma idea se puede extender a consultas que seleccionan filas de una tabla de hechos usando predicados aplicados a tablas de dimensiones. Para ver cómo funciona, considere la siguiente consulta (usando la base de datos de muestra de Contoso BI) para encontrar el monto total de ventas de reproductores MP3 vendidos en tiendas de Contoso con exactamente 50 empleados:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Para comparar con esfuerzos posteriores, esta consulta (muy selectiva) produce un plan de consulta como el siguiente (haga clic para ampliar):
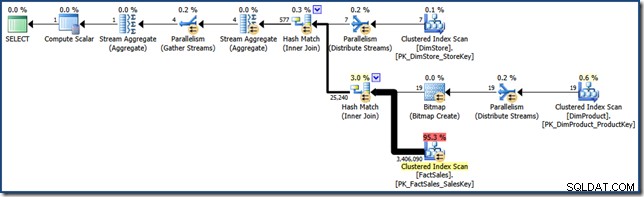
Ese plan de ejecución tiene un coste estimado de algo más de 15,6 unidades . Cuenta con ejecución paralela con un escaneo completo de la tabla de hechos (aunque con un filtro de mapa de bits aplicado).
Las tablas de hechos en esta base de datos de muestra no incluyen índices no agrupados en las claves foráneas de la tabla de hechos de forma predeterminada, por lo que debemos agregar un par:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Con estos índices implementados, podemos comenzar a ver cómo se puede usar la intersección de índices para mejorar la eficiencia. El primer paso es encontrar los identificadores de fila de la tabla de hechos para cada predicado por separado. Las siguientes consultas aplican un predicado de una sola dimensión, luego se unen a la tabla de hechos para encontrar identificadores de fila (claves de índice agrupado de la tabla de hechos):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Los planes de consulta muestran un escaneo de la tabla de dimensiones pequeñas, seguido de búsquedas utilizando el índice no agrupado de la tabla de hechos para encontrar identificadores de fila (recuerde que los índices no agrupados siempre incluyen la clave de agrupación en clústeres de la tabla base o el RID del montón):
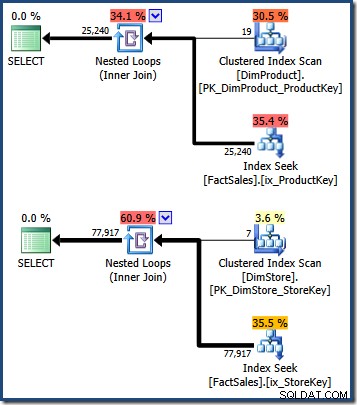
La intersección de estos dos conjuntos de claves de índice agrupado de tablas de hechos identifica las filas que debe devolver la consulta original. Una vez que tengamos estos identificadores de fila, solo tenemos que buscar el Monto de ventas en cada fila de la tabla de hechos y calcular la suma.
Consulta de intersección de índice manual
Poner todo eso junto en una consulta da lo siguiente:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
El FORCESEEK hay una pista para garantizar que obtengamos búsquedas de puntos en la tabla de hechos. Sin esto, el optimizador elige escanear la tabla de hechos, que es exactamente lo que buscamos evitar. El MAXDOP 1 la sugerencia solo ayuda a mantener el plan final en un tamaño bastante razonable para fines de visualización (haga clic para verlo en tamaño completo):
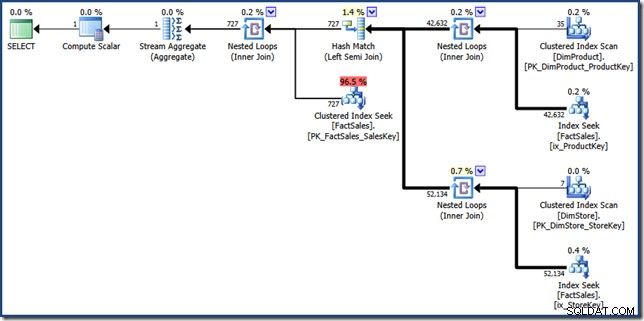
Las partes componentes del plano de intersección de índice manual son bastante fáciles de identificar. Las dos búsquedas de índices no agrupados de la tabla de hechos en el lado derecho producen los dos conjuntos de identificadores de fila de la tabla de hechos. La unión hash encuentra la intersección de estos dos conjuntos. La búsqueda de índice agrupado en la tabla de hechos encuentra los montos de ventas para estos identificadores de fila. Finalmente, Stream Aggregate calcula la cantidad total.
Este plan de consulta realiza relativamente pocas búsquedas en los índices agrupados y no agrupados de la tabla de hechos. Si la consulta es lo suficientemente selectiva, esta podría ser una estrategia de ejecución más barata que escanear la tabla de hechos por completo. La base de datos de muestra de Contoso BI es relativamente pequeña, con solo 3,4 millones de filas en la tabla de hechos de ventas. Para tablas de hechos más grandes, la diferencia entre un escaneo completo y unos pocos cientos de búsquedas podría ser muy significativa. Lamentablemente, la reescritura manual introduce algunos errores graves de cardinalidad, lo que da como resultado un plan con un costo estimado de 46,5 unidades. .
Intersección automática del índice de unión en estrella con búsquedas
Afortunadamente, no tenemos que decidir si la consulta que estamos escribiendo es lo suficientemente selectiva como para justificar esta reescritura manual. Las optimizaciones de unión en estrella para consultas selectivas significan que el optimizador de consultas puede explorar esta opción por nosotros, utilizando la sintaxis de consulta original más fácil de usar:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; El optimizador produce el siguiente plan de ejecución con un costo estimado de 1.64 unidades (haga clic para ampliar):
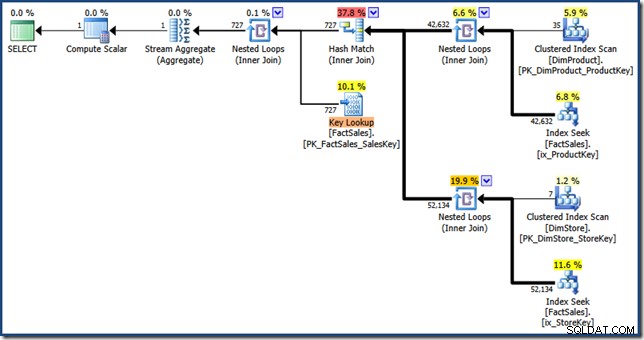
Las diferencias entre este plan y la versión manual son:la intersección del índice es una unión interna en lugar de una semiunión; y la búsqueda de índice agrupado se muestra como una búsqueda clave en lugar de una búsqueda de índice agrupado. A riesgo de insistir en el punto, si la tabla de hechos fuera un montón, la búsqueda de claves sería una búsqueda de RID.
Propiedades de StarJoinInfo
Todas las uniones en este plan tienen un StarJoinInfo estructura. Para verlo, haga clic en un iterador de combinación y busque en la ventana Propiedades de SSMS. Haga clic en la flecha a la izquierda de StarJoinInfo elemento para expandir el nodo.
Las uniones de tablas de hechos no agrupadas a la derecha del plan son búsquedas de índice creadas por el optimizador:
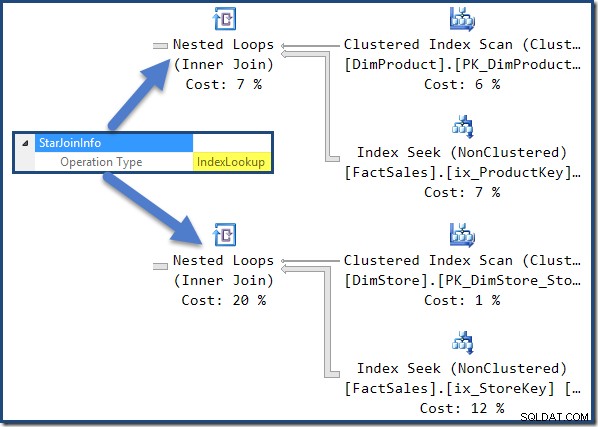
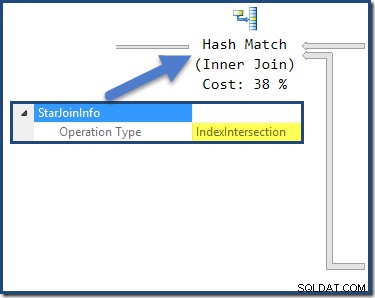
La unión hash tiene un StarJoinInfo estructura que muestra que está realizando una intersección de índice (nuevamente, fabricada por el optimizador):
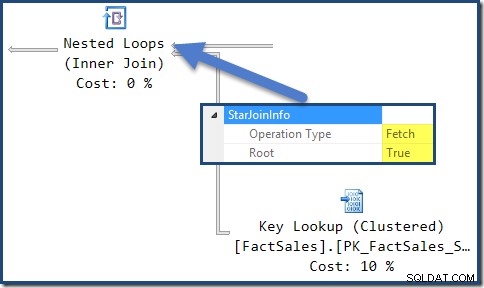
El StarJoinInfo porque la combinación de bucles anidados más a la izquierda muestra que se generó para obtener filas de tablas de hechos por identificador de fila. Está en la raíz del subárbol de unión en estrella generado por el optimizador:
Productos cartesianos y búsqueda de índice de varias columnas
Los planes de intersección de índices considerados como parte de las optimizaciones de unión en estrella son útiles para consultas selectivas de tablas de hechos donde existen índices no agrupados de una sola columna en claves foráneas de tablas de hechos (una práctica de diseño común).
A veces también tiene sentido crear índices de varias columnas en las claves externas de la tabla de hechos, para las combinaciones consultadas con frecuencia. Las optimizaciones de consulta de estrellas selectivas integradas también contienen una reescritura para este escenario. Para ver cómo funciona esto, agregue el siguiente índice de varias columnas a la tabla de hechos:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Vuelva a compilar la consulta de prueba:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; El plan de consulta ya no incluye la intersección del índice (haga clic para ampliar):
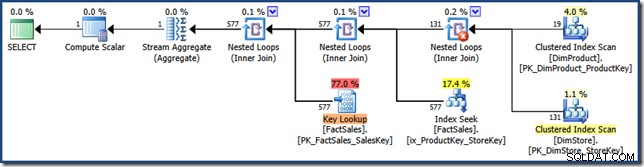
La estrategia elegida aquí es aplicar cada predicado a las tablas de dimensiones, tomar el producto cartesiano de los resultados y usarlo para buscar ambas claves del índice de varias columnas. Luego, el plan de consulta realiza una búsqueda de clave en la tabla de hechos utilizando identificadores de fila exactamente como se vio anteriormente.
El plan de consulta es particularmente interesante porque combina tres funciones que a menudo se consideran malas (escaneos completos, productos cartesianos y búsquedas clave) en una optimización del rendimiento. . Esta es una estrategia válida cuando se espera que el producto de las dos dimensiones sea muy pequeño.
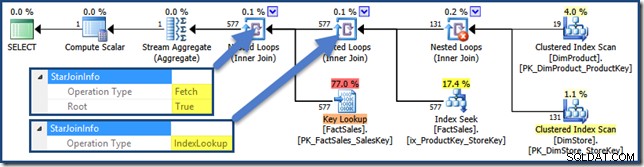
No hay StarJoinInfo para el producto cartesiano, pero las otras uniones tienen información (haga clic para ampliar):
Filtro de índice
Volviendo al esquema del plan de presentación, hay otro StarJoinInfo operación que necesitamos cubrir:
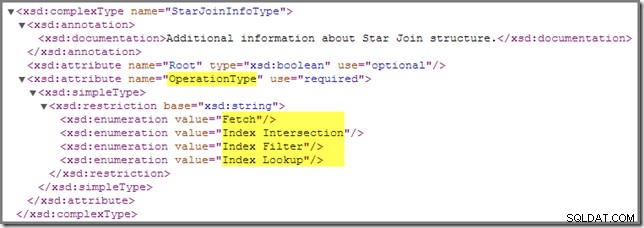
El Index Filter El valor se ve con uniones que se consideran lo suficientemente selectivas como para que valga la pena realizarlas antes de la recuperación de la tabla de hechos. Las uniones que no sean lo suficientemente selectivas se realizarán después de la recuperación y no tendrán un StarJoinInfo estructura.
Para ver un filtro de índice utilizando nuestra consulta de prueba, debemos agregar una tercera tabla de unión a la mezcla, eliminar los índices de tabla de hechos no agrupados creados hasta ahora y agregar uno nuevo:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; El plan de consulta es ahora (haga clic para ampliar):
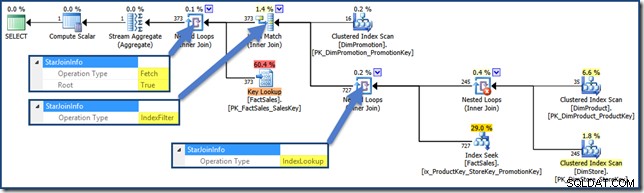
Un plan de consulta de intersección de índice de heap
Para completar, aquí hay una secuencia de comandos para crear una copia en montón de la tabla de hechos con los dos índices no agrupados necesarios para habilitar la reescritura del optimizador de intersección de índices:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; El plan de ejecución para esta consulta tiene las mismas funciones que antes, pero la intersección del índice se realiza mediante RID en lugar de claves de índice agrupadas de tablas de hechos, y la búsqueda final es una búsqueda de RID (haga clic para ampliar):
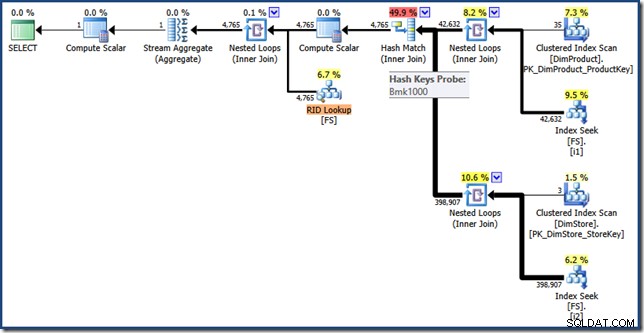
Reflexiones finales
Las reescrituras del optimizador que se muestran aquí están dirigidas a consultas que devuelven un número relativamente pequeño de filas de un grande tabla de hechos Estas reescrituras han estado disponibles en todas las ediciones de SQL Server desde 2005.
Aunque está destinado a acelerar las consultas selectivas de esquemas de estrella (y copos de nieve) en el almacenamiento de datos, el optimizador puede aplicar estas técnicas siempre que detecte un conjunto adecuado de tablas y uniones. Las heurísticas utilizadas para detectar consultas de estrellas son bastante amplias, por lo que puede encontrar formas de planes con StarJoinInfo estructuras en casi cualquier tipo de base de datos. Cualquier tabla de un tamaño razonable (por ejemplo, 100 páginas o más) con referencias a tablas más pequeñas (similares a dimensiones) es una candidata potencial para estas optimizaciones (tenga en cuenta que las claves externas explícitas no obligatorio).
Para aquellos de ustedes que disfrutan de estas cosas, la regla del optimizador responsable de generar patrones selectivos de unión en estrella a partir de una unión lógica de n tablas se llama StarJoinToIdxStrategy (estrella unirse a la estrategia de indexación).