La primera publicación de blog en este sitio, allá por julio de 2012, hablaba sobre los mejores enfoques para los totales acumulados. Desde entonces, me han preguntado en varias ocasiones cómo abordaría el problema si los totales acumulados fueran más complejos, específicamente, si necesitara calcular los totales acumulados para varias entidades, por ejemplo, los pedidos de cada cliente.
El ejemplo original utilizaba un caso ficticio de una ciudad que emitía multas por exceso de velocidad; el total acumulado simplemente agregaba y mantenía un conteo continuo de la cantidad de multas por exceso de velocidad por día (independientemente de a quién se le emitió la multa o por cuánto era). Un ejemplo más complejo (pero práctico) podría ser agregar el valor total acumulado de las multas por exceso de velocidad, agrupadas por licencia de conducir, por día. Imaginemos la siguiente tabla:
CREATE TABLE dbo.SpeedingTickets ( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL ); CREATE UNIQUE INDEX x ON dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Puedes preguntar, DECIMAL(7,2) , ¿De Verdad? ¿Qué tan rápido van estas personas? Bueno, en Canadá, por ejemplo, no es tan difícil obtener una multa por exceso de velocidad de $10,000.
Ahora, completemos la tabla con algunos datos de muestra. No entraré en todos los detalles aquí, pero esto debería generar alrededor de 6000 filas que representan a varios conductores y varios montos de boletos durante un período de un mes:
;WITH TicketAmounts(ID,Value) AS
(
-- 10 arbitrary ticket amounts
SELECT i,p FROM
(
VALUES(1,32.75),(2,75), (3,109),(4,175),(5,295),
(6,68.50),(7,125),(8,145),(9,199),(10,250)
) AS v(i,p)
),
LicenseNumbers(LicenseNumber,[newid]) AS
(
-- 1000 random license numbers
SELECT TOP (1000) 7000000 + number, n = NEWID()
FROM [master].dbo.spt_values
WHERE number BETWEEN 1 AND 999999
ORDER BY n
),
JanuaryDates([day]) AS
(
-- every day in January 2014
SELECT TOP (31) DATEADD(DAY, number, '20140101')
FROM [master].dbo.spt_values
WHERE [type] = N'P'
ORDER BY number
),
Tickets(LicenseNumber,[day],s) AS
(
-- match *some* licenses to days they got tickets
SELECT DISTINCT l.LicenseNumber, d.[day], s = RTRIM(l.LicenseNumber)
FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d
WHERE CHECKSUM(NEWID()) % 100 = l.LicenseNumber % 100
AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
OR (RTRIM(l.LicenseNumber+1) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
)
INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)
SELECT t.LicenseNumber, t.[day], ta.Value
FROM Tickets AS t
INNER JOIN TicketAmounts AS ta
ON ta.ID = CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1))
ORDER BY t.[day], t.LicenseNumber; Esto puede parecer un poco complicado, pero uno de los mayores desafíos que a menudo tengo al redactar estas publicaciones de blog es construir una cantidad adecuada de datos "aleatorios"/arbitrarios realistas. Si tiene un método mejor para la población de datos arbitrarios, por supuesto, no use mis murmullos como ejemplo:son periféricos al punto de esta publicación.
Enfoques
Hay varias formas de resolver este problema en T-SQL. Aquí hay siete enfoques, junto con sus planes asociados. He dejado de lado técnicas como cursores (porque serán innegablemente más lentos) y CTE recursivos basados en fechas (porque dependen de días contiguos).
Subconsulta #1
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND s.IncidentDate < o.IncidentDate
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
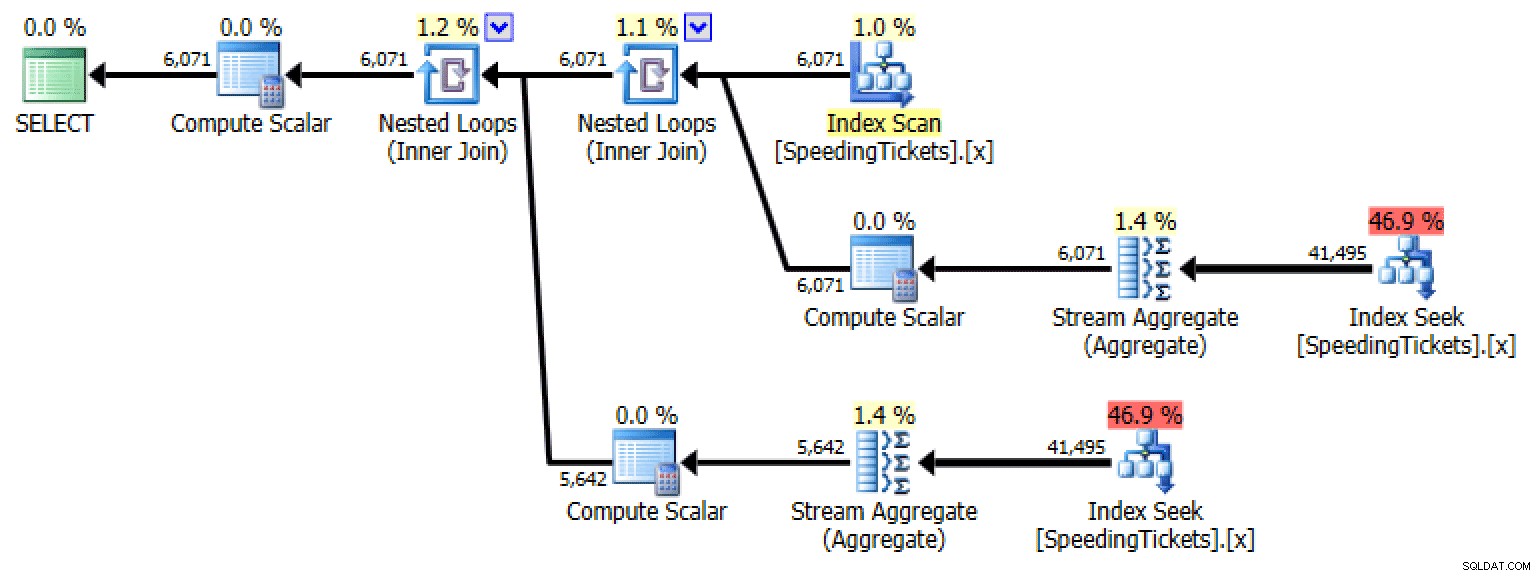
Plan para la subconsulta #1
Subconsulta #2
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
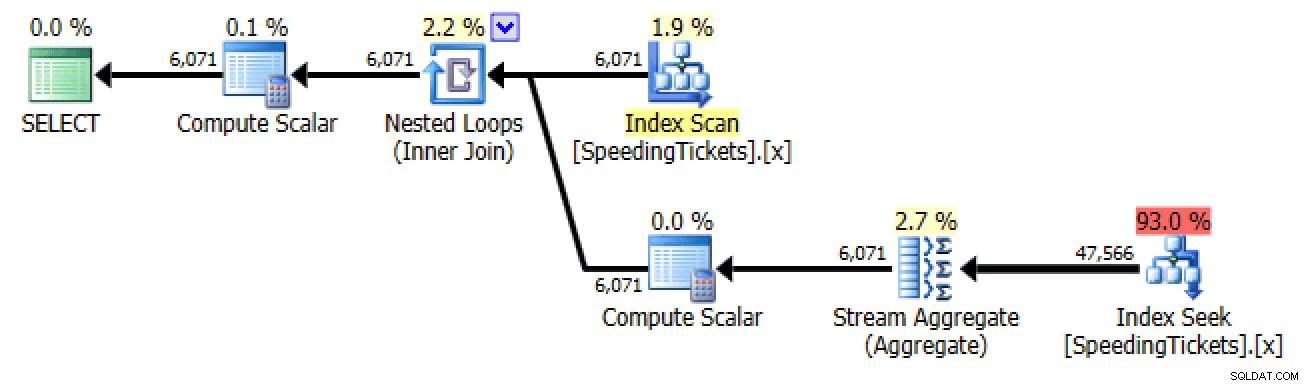
Plan para la subconsulta #2
Auto-unión
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal = SUM(t2.TicketAmount) FROM dbo.SpeedingTickets AS t1 INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNumber = t2.LicenseNumber AND t1.IncidentDate >= t2.IncidentDate GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount ORDER BY t1.LicenseNumber, t1.IncidentDate;
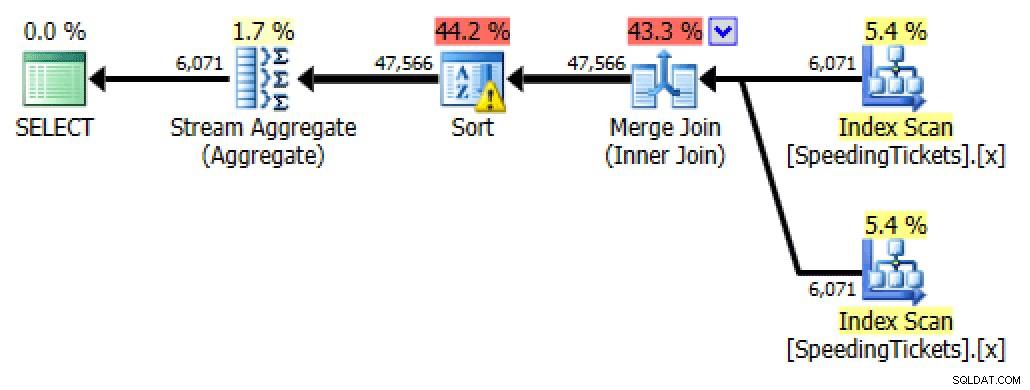
Plan para la autounión
Aplicación exterior
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
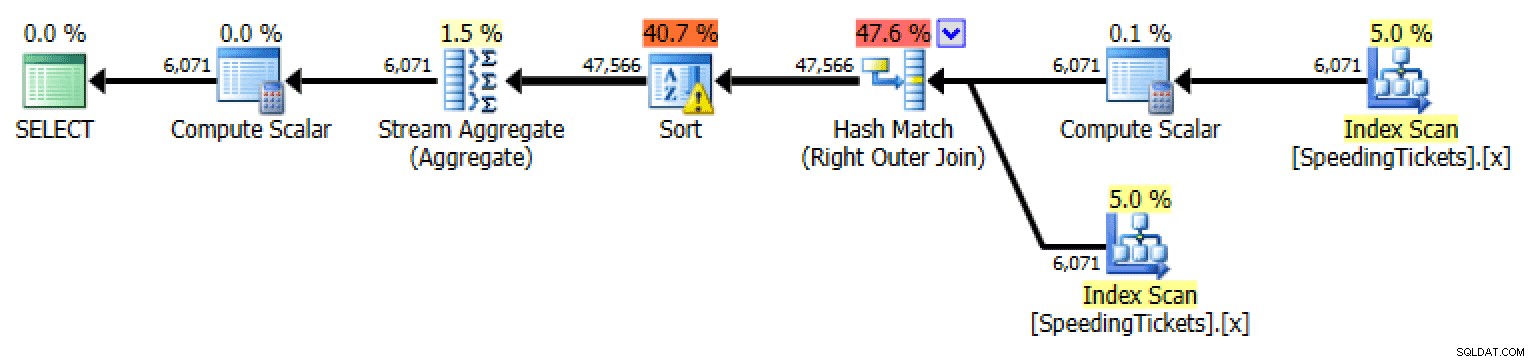
Plan para aplicación externa
SUM OVER() usando RANGE (solo 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Planifique SUM OVER() usando RANGE
SUM OVER() usando FILAS (solo 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;

Plan para SUM OVER() usando ROWS
Iteración basada en conjuntos
Con crédito para Hugo Kornelis (@Hugo_Kornelis) por el capítulo n.° 4 en SQL Server MVP Deep Dives Volumen n.° 1, este enfoque combina un enfoque basado en conjuntos y un enfoque de cursor.
DECLARE @x TABLE
(
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL,
PRIMARY KEY(LicenseNumber, IncidentDate)
);
INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate)
FROM dbo.SpeedingTickets;
DECLARE @rn INT = 1, @rc INT = 1;
WHILE @rc > 0
BEGIN
SET @rn += 1;
UPDATE [current]
SET RunningTotal = [last].RunningTotal + [current].TicketAmount
FROM @x AS [current]
INNER JOIN @x AS [last]
ON [current].LicenseNumber = [last].LicenseNumber
AND [last].rn = @rn - 1
WHERE [current].rn = @rn;
SET @rc = @@ROWCOUNT;
END
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal
FROM @x
ORDER BY LicenseNumber, IncidentDate; Debido a su naturaleza, este enfoque produce muchos planes idénticos en el proceso de actualización de la variable de la tabla, todos los cuales son similares a los planes de autounión y aplicación externa, pero pueden usar una búsqueda:
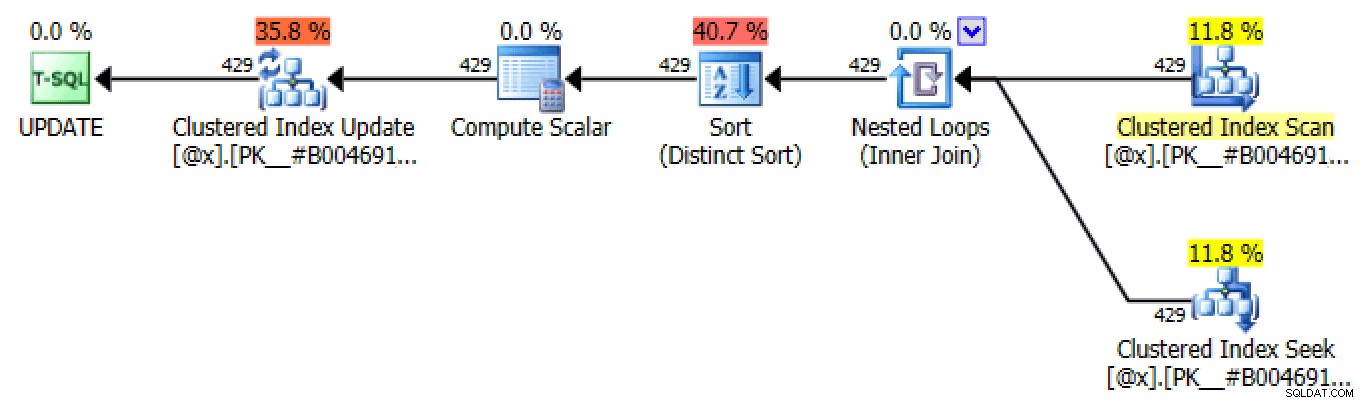
Uno de los muchos planes UPDATE producidos a través de la iteración basada en conjuntos
La única diferencia entre cada plan en cada iteración es el número de filas. A través de cada iteración sucesiva, el número de filas afectadas debería permanecer igual o disminuir, ya que el número de filas afectadas en cada iteración representa el número de conductores con boletos en ese número de días (o, más precisamente, el número de días en ese "rango").
Resultados de rendimiento
Así es como se apilan los enfoques, como lo muestra SQL Sentry Plan Explorer, con la excepción del enfoque de iteración basado en conjuntos que, debido a que consta de muchas declaraciones individuales, no se representa bien en comparación con el resto.
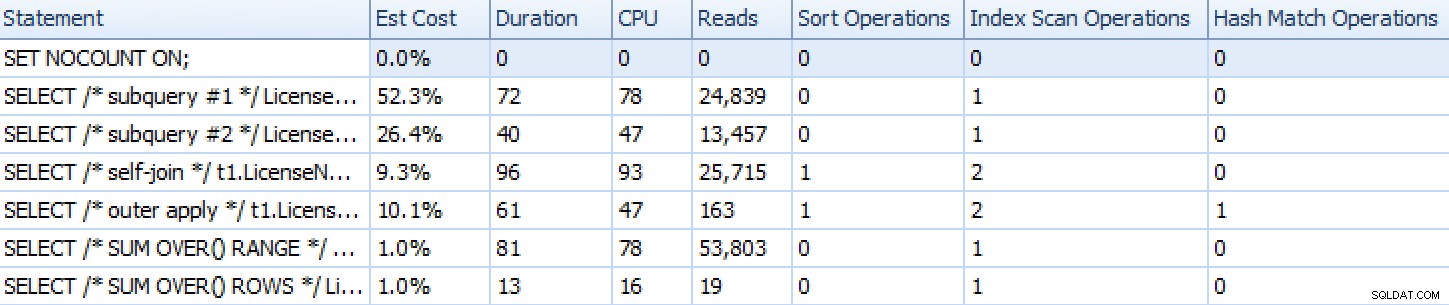
Métricas de tiempo de ejecución de Plan Explorer para seis de los siete enfoques
Además de revisar los planes y comparar las métricas de tiempo de ejecución en Plan Explorer, también medí el tiempo de ejecución sin procesar en Management Studio. Estos son los resultados de ejecutar cada consulta 10 veces, teniendo en cuenta que esto también incluye el tiempo de procesamiento en SSMS:
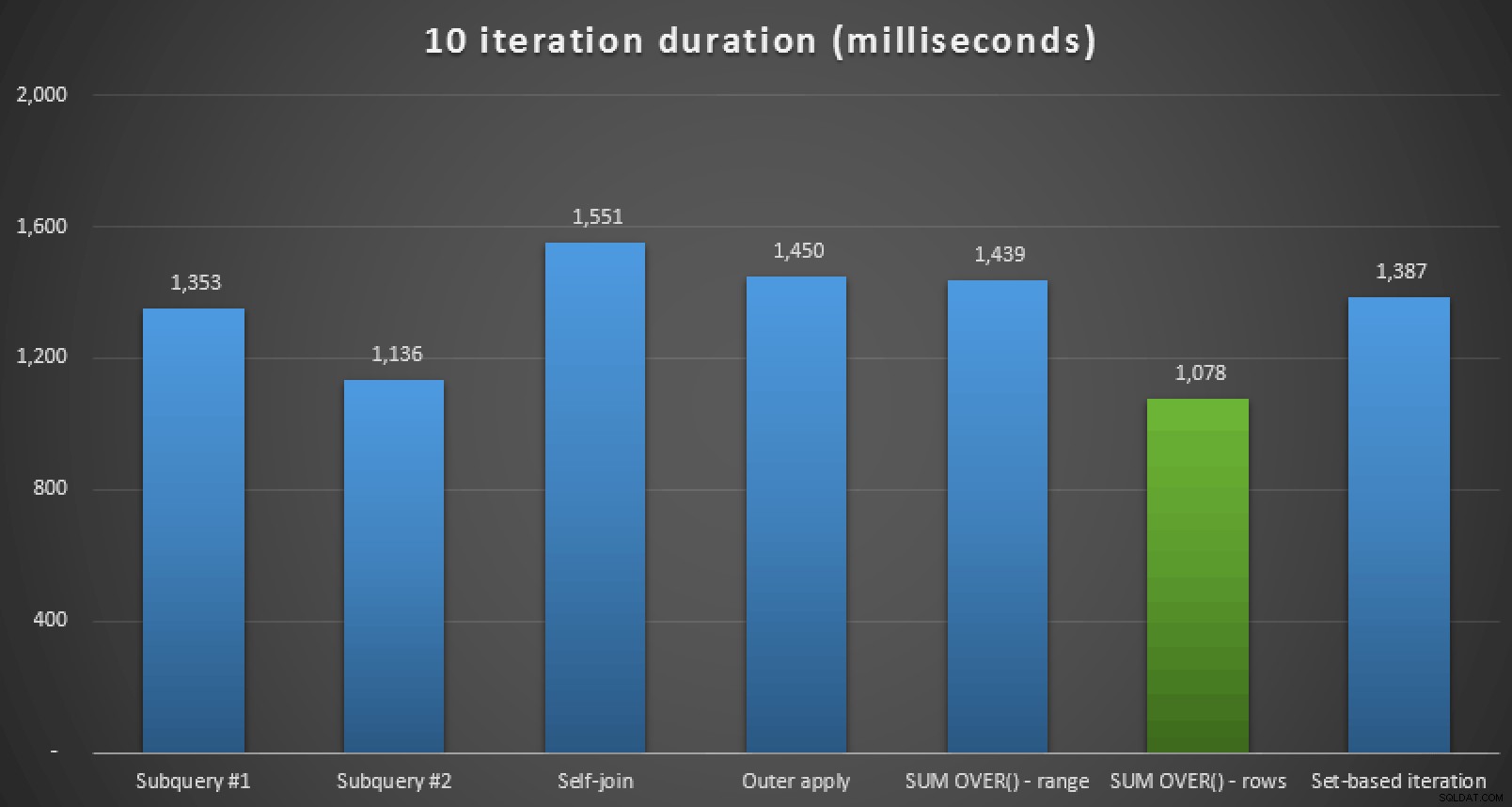
Duración del tiempo de ejecución, en milisegundos, para los siete enfoques (10 iteraciones )
Entonces, si está en SQL Server 2012 o superior, el mejor enfoque parece ser SUM OVER() usando ROWS UNBOUNDED PRECEDING . Si no está en SQL Server 2012, el segundo enfoque de subconsulta parecía ser óptimo en términos de tiempo de ejecución, a pesar de la gran cantidad de lecturas en comparación con, por ejemplo, OUTER APPLY consulta. En todos los casos, por supuesto, debe probar estos enfoques, adaptados a su esquema, contra su propio sistema. Sus datos, índices y otros factores pueden llevar a que una solución diferente sea la más óptima en su entorno.
Otras complejidades
Ahora, el índice único significa que cualquier combinación de LicenseNumber + IncidentDate contendrá un solo total acumulativo, en el caso de que un conductor específico obtenga múltiples boletos en un día determinado. Esta regla de negocios ayuda a simplificar un poco nuestra lógica, evitando la necesidad de un desempate para producir totales acumulados deterministas.
Si tiene casos en los que puede tener varias filas para cualquier combinación de LicenseNumber + IncidentDate, puede romper el empate usando otra columna que ayude a que la combinación sea única (obviamente, la tabla de origen ya no tendría una restricción única en esas dos columnas) . Tenga en cuenta que esto es posible incluso en los casos en que DATE la columna es en realidad DATETIME – mucha gente asume que los valores de fecha/hora son únicos, pero ciertamente esto no siempre está garantizado, independientemente de la granularidad.
En mi caso, podría usar la IDENTITY columna, IncidentID; así es como ajustaría cada solución (reconociendo que puede haber mejores formas; simplemente descartando ideas):
/* --------- subquery #1 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND (s.IncidentDate < o.IncidentDate
-- added this line:
OR (s.IncidentDate = o.IncidentDate AND s.IncidentID < o.IncidentID))
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
/* --------- subquery #2 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
-- added this line:
AND IncidentID <= t.IncidentID
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
/* --------- self-join --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
-- added this line:
AND t1.IncidentID >= t2.IncidentID
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- outer apply --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
-- added this line:
AND IncidentID <= t1.IncidentID
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- SUM() OVER using RANGE --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID RANGE UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- SUM() OVER using ROWS --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- set-based iteration --------- */
DECLARE @x TABLE
(
-- added this column, and made it the PK:
IncidentID INT PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL
);
-- added the additional column to the INSERT/SELECT:
INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID)
-- and added this tie-breaker column ------------------------------^^^^^^^^^^^^
FROM dbo.SpeedingTickets;
-- the rest of the set-based iteration solution remained unchanged
Otra complicación con la que te puedes encontrar es cuando no buscas toda la tabla, sino un subconjunto (digamos, en este caso, la primera semana de enero). Tendrás que hacer ajustes agregando WHERE y tenga en cuenta esos predicados cuando también tenga subconsultas correlacionadas.



