El motor de ejecución de consultas de SQL Server tiene dos formas de implementar una operación lógica de 'unión de todos', utilizando los operadores físicos Concatenación y Merge Join Concatenation. Si bien la operación lógica es la misma, existen diferencias importantes entre los dos operadores físicos que pueden marcar una gran diferencia en la eficiencia de sus planes de ejecución.
El optimizador de consultas hace un trabajo razonable al elegir entre las dos opciones en muchos casos, pero está lejos de ser perfecto en esta área. Este artículo describe las oportunidades de optimización de consultas que presenta Merge Join Concatenation y detalla los comportamientos internos y las consideraciones que debe tener en cuenta para aprovecharlas al máximo.
Concatenación

El operador de concatenación es relativamente simple:su salida es el resultado de la lectura completa de cada una de sus entradas en secuencia. El operador de concatenación es un n-ario operador físico, lo que significa que puede tener '2…n' entradas. Para ilustrar, revisemos el ejemplo basado en AdventureWorks de mi artículo anterior, "Reescribir consultas para mejorar el rendimiento":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
La siguiente consulta enumera los ID de transacciones y productos para seis productos en particular:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Produce un plan de ejecución con un operador de concatenación con seis entradas, como se ve en SQL Sentry Plan Explorer:
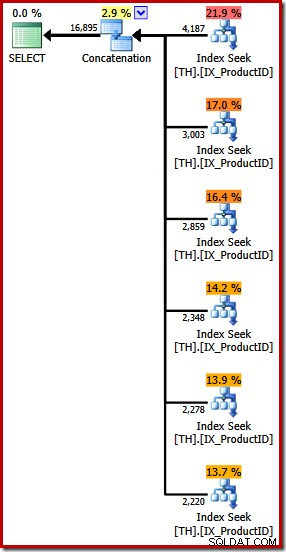
El plan anterior presenta una búsqueda de índice separada para cada ID de producto enumerado, en el mismo orden que se especifica en la consulta (leyendo de arriba hacia abajo). La búsqueda de índice más alta es para el producto 870, la siguiente hacia abajo es para el producto 873, luego la 921 y así sucesivamente. Por supuesto, nada de eso es un comportamiento garantizado, solo es algo interesante de observar.
Mencioné antes que el operador Concatenación forma su salida leyendo sus entradas en secuencia. Cuando se ejecuta este plan, existe una buena posibilidad de que el conjunto de resultados muestre filas para el producto 870 primero, luego 873, 921, 712, 707 y finalmente el producto 711. Nuevamente, esto no está garantizado porque no especificamos un PEDIDO cláusula BY, pero muestra cómo funciona la concatenación internamente.
Un "Plan de Ejecución" de SSIS
Por razones que tendrán sentido en un momento, considere cómo podríamos diseñar un paquete SSIS para realizar la misma tarea. Ciertamente, también podríamos escribir todo como una declaración T-SQL única en SSIS, pero la opción más interesante es crear una fuente de datos separada para cada producto y usar un componente SSIS "Union All" en lugar de la concatenación de SQL Server. operador:
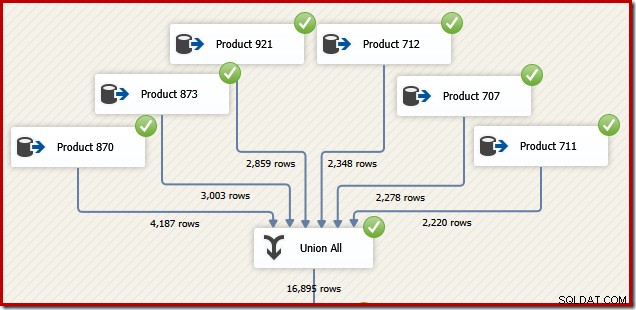
Ahora imagine que necesitamos el resultado final de ese flujo de datos en orden de ID de transacción. Una opción sería agregar un componente Ordenar explícito después de Unir todo:
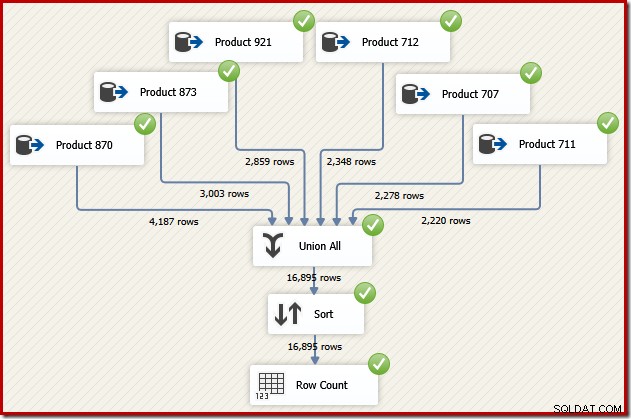
Eso ciertamente haría el trabajo, pero un diseñador de SSIS capacitado y experimentado se daría cuenta de que hay una mejor opción:lea los datos de origen para cada producto en el orden de ID de transacción (utilizando el índice), luego use una operación de conservación de orden para combinar los conjuntos .
En SSIS, el componente que combina filas de dos flujos de datos ordenados en un solo flujo de datos ordenados se denomina "Fusionar". A continuación se muestra un flujo de datos de SSIS rediseñado que usa Merge para devolver las filas deseadas en el orden de ID de transacción:
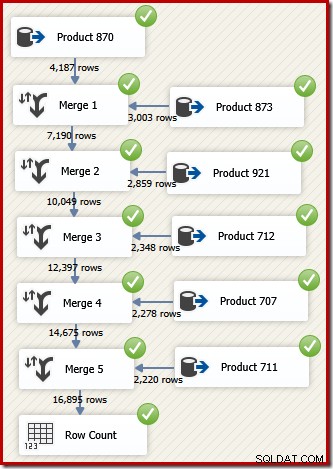
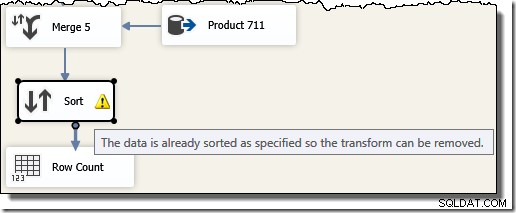
Tenga en cuenta que necesitamos cinco componentes Merge separados porque Merge es un componente binario, a diferencia del componente SSIS "Union All", que era n-ary . El nuevo flujo de combinación produce resultados en el orden de ID de transacción, sin necesidad de un componente de clasificación costoso (y bloqueador). De hecho, si intentamos agregar una ordenación en el ID de transacción después de la fusión final, SSIS muestra una advertencia para informarnos que la secuencia ya está ordenada de la manera deseada:
Ahora se puede revelar el punto del ejemplo de SSIS. Mire el plan de ejecución elegido por el optimizador de consultas de SQL Server cuando le pedimos que devuelva los resultados de la consulta T-SQL original en orden de ID de transacción (agregando una cláusula ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
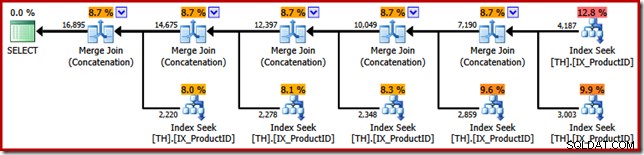
Las similitudes con el paquete SSIS Merge son sorprendentes; incluso hasta la necesidad de cinco operadores binarios de "Fusionar". La única diferencia importante es que SSIS tiene componentes separados para "Combinar combinación" y "Combinar", mientras que SQL Server usa el mismo operador central para ambos.
Para ser claros, los operadores Merge Join (Concatenación) en el plan de ejecución de SQL Server son no realizar una unión; el motor simplemente reutiliza el mismo operador físico para implementar la unión que preserva el orden.
Escribir planes de ejecución en SQL Server
SSIS no tiene un lenguaje de especificación de flujo de datos, ni un optimizador para convertir dicha especificación en una tarea de flujo de datos ejecutable. Depende del diseñador del paquete SSIS darse cuenta de que es posible una combinación que conserve el orden, establecer las propiedades de los componentes (como las claves de ordenación) de manera adecuada y luego comparar el rendimiento. Esto requiere más esfuerzo (y habilidad) por parte del diseñador, pero proporciona un grado de control muy fino.
La situación en SQL Server es la opuesta:escribimos una consulta especificación usando el lenguaje T-SQL, luego confíe en el optimizador de consultas para explorar las opciones de implementación y elegir una eficiente. No tenemos la opción de construir un plan de ejecución directamente. La mayoría de las veces, esto es muy deseable:SQL Server sin duda sería bastante menos popular si cada consulta requiriera que escribiésemos un paquete de estilo SSIS.
Sin embargo (como expliqué en mi publicación anterior), el plan elegido por el optimizador puede ser sensible al T-SQL utilizado para describir los resultados deseados. Repitiendo el ejemplo de ese artículo, podríamos haber escrito la consulta T-SQL original usando una sintaxis alternativa:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Esta consulta especifica exactamente el mismo conjunto de resultados que antes, pero el optimizador no tiene en cuenta un plan de preservación del orden (concatenación de fusión), sino que elige escanear el índice agrupado (una opción mucho menos eficiente):
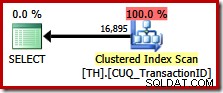
Aprovechamiento de la conservación de pedidos en SQL Server
Evitar la clasificación innecesaria puede conducir a ganancias de eficiencia significativas, ya sea que estemos hablando de SSIS o SQL Server. Lograr este objetivo puede ser más complicado y difícil en SQL Server porque no tenemos un control tan detallado sobre el plan de ejecución, pero aún hay cosas que podemos hacer.
Específicamente, comprender cómo funciona internamente el operador Merge Join Concatenation de SQL Server puede ayudarnos a continuar escribiendo T-SQL relacional y claro, al tiempo que alienta al optimizador de consultas a considerar las opciones de procesamiento de conservación del orden (fusión) cuando corresponda.
Cómo funciona la concatenación de combinación de combinación

Un Merge Join normal requiere que ambas entradas se clasifiquen en las claves de unión. Merge Join Concatenation, por otro lado, simplemente fusiona dos flujos ya ordenados en un solo flujo ordenado; no hay unión, como tal.
Esto plantea la pregunta:¿cuál es exactamente el 'orden' que se conserva?
En SSIS, tenemos que establecer propiedades de clave de clasificación en las entradas de combinación para definir el orden. SQL Server no tiene equivalente a esto. La respuesta a la pregunta anterior es un poco complicada, así que la daremos paso a paso.
Considere el siguiente ejemplo, que solicita una concatenación de fusión de dos tablas de almacenamiento dinámico sin indexar (el caso más simple):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Estas dos tablas no tienen índices y no hay una cláusula ORDER BY. ¿Qué orden 'preservará' la concatenación de combinación de fusión? Para darle un momento para pensar en eso, primero veamos el plan de ejecución producido para la consulta anterior en las versiones de SQL Server anteriores 2012:
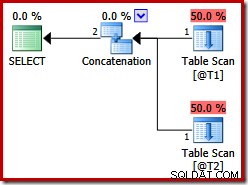
No hay concatenación de combinación de combinación, a pesar de la sugerencia de consulta:antes de SQL Server 2012, esta sugerencia solo funciona con UNION, no UNION ALL. Para obtener un plan con el operador de combinación deseado, debemos deshabilitar la implementación de una UNION ALL (UNIA) lógica usando el operador físico Concatenation (CON). Tenga en cuenta que lo siguiente no está documentado y no es compatible con el uso de producción:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Esa consulta produce el mismo plan que SQL Server 2012 y 2014 solo con la sugerencia de consulta MERGE UNION:
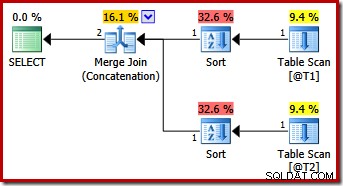
Tal vez inesperadamente, el plan de ejecución presenta clasificaciones explícitas en ambas entradas de la fusión. Las propiedades de clasificación son:
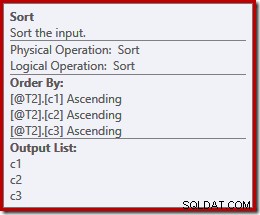
Tiene sentido que una combinación que preserve el orden requiera un orden de entrada consistente, pero ¿por qué eligió (c1, c2, c3) en lugar de, por ejemplo, (c3, c1, c2) o (c2, c3, c1)? Como punto de partida, las entradas de concatenación de fusión se ordenan en la lista de proyección de salida. La estrella de selección en la consulta se expande a (c1, c2, c3), por lo que ese es el orden elegido.
Ordenar por combinación de lista de proyecciones de salida
Para ilustrar mejor el punto, podemos expandir la estrella de selección nosotros mismos (¡como deberíamos!) eligiendo un orden diferente (c3, c2, c1) mientras estamos en eso:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Los tipos ahora cambian para coincidir (c3, c2, c1):
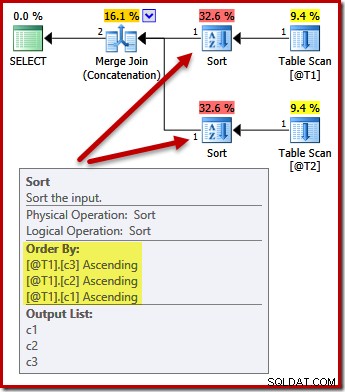
Nuevamente, la consulta salida No se garantiza que el orden (suponiendo que agreguemos algunos datos a las tablas) se clasifique como se muestra, porque no tenemos la cláusula ORDER BY. Estos ejemplos pretenden simplemente mostrar cómo el optimizador selecciona un orden de clasificación de entrada inicial, en ausencia de cualquier otra razón para ordenar.
Órdenes de clasificación en conflicto
Ahora considere lo que sucede si dejamos la lista de proyección como (c3, c2, c1) y agregamos un requisito para ordenar los resultados de la consulta por (c1, c2, c3). ¿Se seguirán clasificando las entradas de la fusión en (c3, c2, c1) con una clasificación posterior a la fusión en (c1, c2, c3) para satisfacer ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
No. El optimizador es lo suficientemente inteligente como para evitar ordenar dos veces:
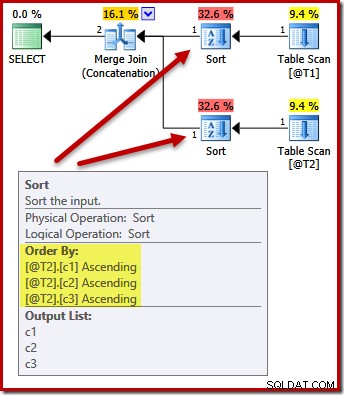
Ordenar ambas entradas en (c1, c2, c3) es perfectamente aceptable para la concatenación de fusión, por lo que no se requiere doble ordenación.
Tenga en cuenta que este plan sí garantizar que el orden de los resultados será (c1, c2, c3). El plan tiene el mismo aspecto que los planes anteriores sin ORDER BY, pero no todos los detalles internos se presentan en los planes de ejecución visibles para el usuario.
El efecto de la singularidad
Al elegir un orden de clasificación para las entradas de combinación, el optimizador también se ve afectado por las garantías de exclusividad que existen. Considere el siguiente ejemplo, con cinco columnas, pero tenga en cuenta los diferentes órdenes de columnas en la operación UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
El plan de ejecución incluye ordenaciones en (c5, c1, c2, c4, c3) para la tabla @T1 y (c5, c4, c3, c2, c1) para la tabla @T2:
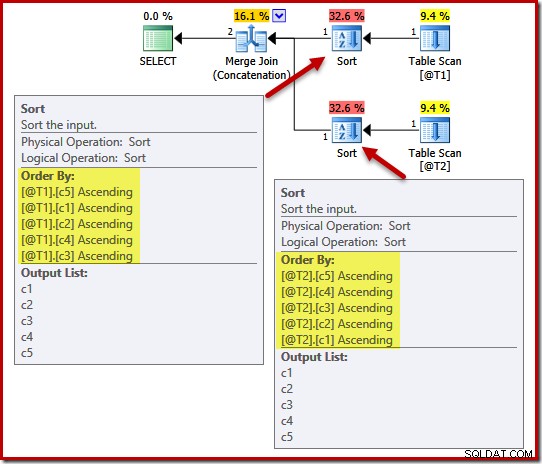
Para demostrar el efecto de la unicidad en estos tipos, agregaremos una restricción ÚNICA a la columna c1 en la tabla T1 y a la columna c4 en la tabla T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
El punto sobre la unicidad es que el optimizador sabe que puede dejar de ordenar tan pronto como encuentre una columna que esté garantizada como única. Ordenar por columnas adicionales después de encontrar una clave única no afectará el orden de clasificación final, por definición.
Con las restricciones ÚNICAS implementadas, el optimizador puede simplificar la lista de clasificación (c5, c1, c2, c4, c3) para T1 a (c5, c1) porque c1 es único. De manera similar, la lista de clasificación (c5, c4, c3, c2, c1) para T2 se simplifica a (c5, c4) porque c4 es una clave:
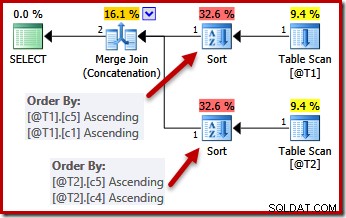
Paralelismo
La simplificación debida a una clave única no está perfectamente implementada. En un plan paralelo, los flujos se dividen para que todas las filas de la misma instancia de la combinación terminen en el mismo subproceso. Esta partición del conjunto de datos se basa en las columnas de combinación y no se simplifica por la presencia de una clave.
La siguiente secuencia de comandos utiliza el indicador de rastreo no admitido 8649 para generar un plan paralelo para la consulta anterior (que no cambia de lo contrario):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
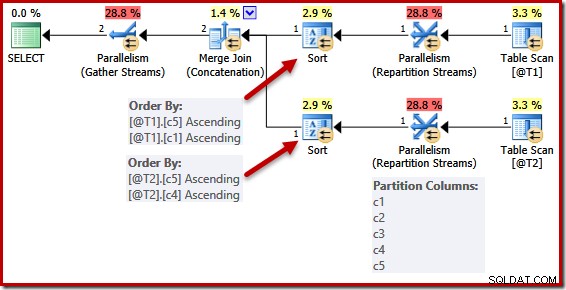
Las listas de clasificación se simplifican como antes, pero los operadores de Repartition Streams todavía dividen todas las columnas. Si esta simplificación se implementara de manera consistente, los operadores de partición también operarían solo en (c5, c1) y (c5, c4).
Problemas con índices no únicos
La forma en que el optimizador razona sobre los requisitos de clasificación para la concatenación de fusión puede generar problemas de clasificación innecesarios, como muestra el siguiente ejemplo:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Mirando la consulta y los índices disponibles, esperaríamos un plan de ejecución que realice un escaneo ordenado de los índices agrupados, utilizando la concatenación de combinación de combinación para evitar la necesidad de ordenar. Esta expectativa está totalmente justificada, porque los índices agrupados proporcionan el orden especificado en la cláusula ORDER BY. Desafortunadamente, el plan que realmente tenemos incluye dos tipos:
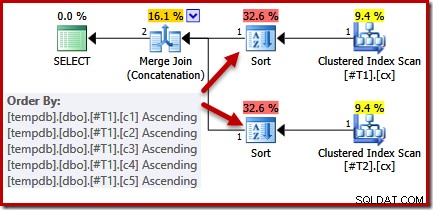
No hay una buena razón para este tipo, solo aparecen porque la lógica del optimizador de consultas es imperfecta. La lista de columnas de salida de combinación (c1, c2, c3, c4, c5) es un superconjunto de ORDER BY, pero no hay único clave para simplificar esa lista. Como resultado de esta brecha en el razonamiento del optimizador, concluye que la fusión requiere que su entrada esté ordenada en (c1, c2, c3, c4, c5).
Podemos verificar este análisis modificando el script para que uno de los índices agrupados sea único:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
El plan de ejecución ahora solo tiene una clasificación sobre la tabla con el índice no único:
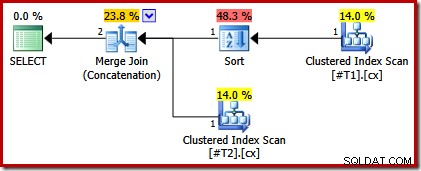
Si ahora hacemos ambos índices agrupados únicos, no aparecen clasificaciones:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Con ambos índices únicos, las listas de clasificación de entrada de combinación inicial se pueden simplificar a la columna c1 sola. La lista simplificada coincide exactamente con la cláusula ORDER BY, por lo que no se necesitan ordenaciones en el plan final:
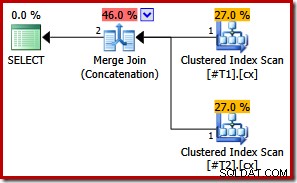
Tenga en cuenta que ni siquiera necesitamos la sugerencia de consulta en este último ejemplo para obtener el plan de ejecución óptimo.
Reflexiones finales
Eliminar clasificaciones en un plan de ejecución puede ser complicado. En algunos casos, puede ser tan simple como modificar un índice existente (o proporcionar uno nuevo) para entregar las filas en el orden requerido. El optimizador de consultas hace un trabajo razonable en general cuando los índices apropiados están disponibles.
Sin embargo, en (muchos) otros casos, evitar las clasificaciones puede requerir una comprensión mucho más profunda del motor de ejecución, el optimizador de consultas y los propios operadores del plan. Evitar las ordenaciones es, sin duda, un tema avanzado de ajuste de consultas, pero también increíblemente gratificante cuando todo sale bien.