Este artículo muestra cómo SQL Server combina la información de densidad de varias estadísticas de una sola columna para producir una estimación de cardinalidad para una agregación en varias columnas. Se espera que los detalles sean interesantes en sí mismos. También brindan información sobre algunos de los enfoques y algoritmos generales utilizados por el estimador de cardinalidad.
Considere la siguiente consulta de base de datos de muestra de AdventureWorks, que enumera la cantidad de artículos de inventario de productos en cada contenedor en cada estante del almacén:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
El plan de ejecución estimado muestra 1069 filas que se leen de la tabla, ordenadas en Shelf y Bin orden, luego agregado usando un operador Stream Aggregate:
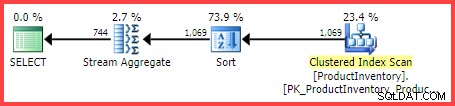
Plan de ejecución estimado
La pregunta es, ¿cómo llegó el optimizador de consultas de SQL Server a la estimación final de 744 filas?
Estadísticas disponibles
Al compilar la consulta anterior, el optimizador de consultas creará estadísticas de una sola columna en el Shelf y Bin columnas, si aún no existen estadísticas adecuadas. Entre otras cosas, estas estadísticas proporcionan información sobre el número de valores de columna distintos (en el vector de densidad):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Los resultados se resumen en la siguiente tabla (la tercera columna se calcula a partir de la densidad):
| Columna | Densidad | 1 / Densidad |
|---|---|---|
| Estante | 0,04761905 | 21 |
| Papelera | 0,01612903 | 62 |
Información de vector de densidad de estantes y contenedores
Como señala la documentación, el recíproco de la densidad es el número de valores distintos en la columna. A partir de la información de estadísticas que se muestra arriba, SQL Server sabe que había 21 Shelf distintos valores y 62 Bin distintos valores en la tabla, cuando se recopilaron las estadísticas.
La tarea de estimar el número de filas producidas por un GROUP BY La cláusula es trivial cuando solo está involucrada una sola columna (suponiendo que no haya otros predicados). Por ejemplo, es fácil ver que GROUP BY Shelf producirá 21 filas; GROUP BY Bin producirá 62.
Sin embargo, no está claro de inmediato cómo SQL Server puede estimar la cantidad de (Shelf, Bin) distintos combinaciones para nuestro GROUP BY Shelf, Bin consulta. Para plantear la pregunta de una manera ligeramente diferente:dados 21 estantes y 62 recipientes, ¿cuántas combinaciones únicas de estantes y recipientes habrá? Dejando a un lado los aspectos físicos y otros conocimientos humanos del dominio del problema, la respuesta podría estar entre max(21, 62) =62 y (21 * 62) =1302. Sin más información, no hay una manera obvia de saber dónde lanzar una estimación en ese rango.
Sin embargo, para nuestra consulta de ejemplo, SQL Server estima 744.312 filas (redondeadas a 744 en la vista Plan Explorer), pero ¿sobre qué base?
Evento extendido de estimación de cardinalidad
La forma documentada de analizar el proceso de estimación de cardinalidad es usar el Evento extendido query_optimizer_estimate_cardinality (a pesar de estar en el canal de "depuración"). Mientras se ejecuta una sesión que recopila este evento, los operadores del plan de ejecución obtienen una propiedad adicional StatsCollectionId que vincula las estimaciones de los operadores individuales con los cálculos que las produjeron. Para nuestra consulta de ejemplo, el ID de colección de estadísticas 2 está vinculado a la estimación de cardinalidad para el grupo por operador agregado.
El resultado relevante del evento extendido para nuestra consulta de prueba es:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Seguro que hay información útil allí.
Podemos ver que la clase de calculadora de valores distintos de la hoja del plan (CDVCPlanLeaf ), usando estadísticas de una sola columna en Shelf y Bin como entradas. El elemento de recopilación de estadísticas hace coincidir este fragmento con el id (2) que se muestra en el plan de ejecución, que muestra la cardinalidad estimada de 744,31 , y también más información sobre los ID de objetos de estadísticas utilizados.
Desafortunadamente, no hay nada en la salida del evento que diga exactamente cómo la calculadora llegó a la cifra final, que es lo que realmente nos interesa.
Combinar recuentos distintos
Yendo por una ruta menos documentada, podemos solicitar un plan estimado para la consulta con indicadores de seguimiento 2363 y 3604 habilitado:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Esto devuelve información de depuración a la pestaña Mensajes en SQL Server Management Studio. La parte interesante se reproduce a continuación:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Esto muestra la misma información que el evento extendido en un formato (posiblemente) más fácil de consumir:
- El operador relacional de entrada para calcular una estimación de cardinalidad para (
LogOp_GbAgg– grupo lógico por agregado) - La calculadora utilizada (
CDVCPlanLeaf) y estadísticas de entrada - Los detalles de la recopilación de estadísticas resultante
La nueva información interesante es la parte sobre el uso de la cardinalidad ambiental para combinar recuentos distintos .
Esto muestra claramente que se usaron los valores 21, 62 y 1069, pero (frustrantemente) aún no se sabe exactamente qué cálculos se realizaron para llegar a 744.312 resultado.
¡Al depurador!
Adjuntar un depurador y usar símbolos públicos nos permite explorar en detalle la ruta del código que se siguió al compilar la consulta de ejemplo.
La siguiente instantánea muestra la parte superior de la pila de llamadas en un punto representativo del proceso:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Hay algunos detalles interesantes aquí. Trabajando de abajo hacia arriba, vemos que la cardinalidad se deriva utilizando el CE actualizado (CCardFrameworkSQL12 ) disponible en SQL Server 2014 y versiones posteriores (el CE original es CCardFrameworkSQL7 ), para el grupo por operador lógico agregado (CLogOp_GbAgg ).
Calcular la cardinalidad distinta implica combinar (mungear) múltiples entradas, usando muestreo sin reemplazo.
La referencia a H y un logaritmo (natural) en el segundo método desde arriba muestra el uso de la entropía de Shannon en el cálculo:
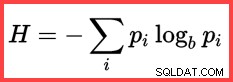
Entropía de Shannon
La entropía se puede utilizar para estimar la correlación informativa (información mutua) entre dos estadísticas:
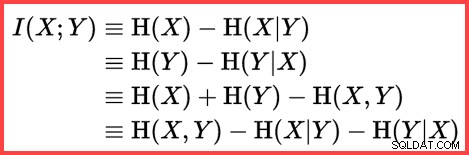
Información mutua
Juntando todo esto, podemos construir un script de cálculo T-SQL que coincida con la forma en que SQL Server usa el muestreo sin reemplazo, la entropía de Shannon y la información mutua. para producir la estimación de cardinalidad final.
Comenzamos con los números de entrada (cardinalidad ambiental y el número de valores distintos en cada columna):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; La frecuencia de cada columna es el número promedio de filas por valor distinto:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; El muestreo sin reemplazo (SWR) es una simple cuestión de restar el número promedio de filas por valor distinto (frecuencia) del número total de filas:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Calcule las entropías (N log N) y la información mutua:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Ahora que hemos estimado cuán correlacionados están los dos conjuntos de estadísticas, podemos calcular la estimación final:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
El resultado del cálculo es 744,311823994677, que es 744,312 redondeado a tres decimales.
Para mayor comodidad, aquí está el código completo en un bloque:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Reflexiones finales
La estimación final es imperfecta en este caso:la consulta de ejemplo devuelve 441 filas.
Para obtener una estimación mejorada, podríamos proporcionar al optimizador mejor información sobre la densidad del Bin y Shelf columnas utilizando una estadística multicolumna. Por ejemplo:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Con esa estadística en su lugar (ya sea como se indica o como un efecto secundario de agregar un índice de varias columnas similar), la estimación de cardinalidad para la consulta de ejemplo es exactamente correcta. Sin embargo, es raro calcular una agregación tan simple. Con predicados adicionales, la estadística de varias columnas puede ser menos eficaz. Sin embargo, es importante recordar que la información de densidad adicional proporcionada por las estadísticas de varias columnas puede ser útil para agregaciones (así como comparaciones de igualdad).
Sin una estadística de varias columnas, una consulta agregada con predicados adicionales aún puede usar la lógica esencial que se muestra en este artículo. Por ejemplo, en lugar de aplicar la fórmula a la cardinalidad de la tabla, se puede aplicar a los histogramas de entrada paso a paso.
Contenido relacionado:Estimación de cardinalidad para un predicado en una expresión COUNT