Un modelo de datos de nómina le permite calcular fácilmente el salario de sus empleados. ¿Cómo funciona este modelo?
No importa si dirige una empresa pequeña o grande, necesita algún tipo de solución de nómina. Ahí es donde una aplicación de nómina es útil. Además, cuanto más grande es la empresa, más difícil se vuelve manejar los cálculos salariales de los empleados; aquí, una aplicación de nómina se convierte en una necesidad. Para ayudarlo a comprender todos los datos necesarios para dicha aplicación, lo guiaremos a través de un modelo de datos relacionado.
¡Veamos cómo funciona nuestro modelo de datos de nómina!
Modelo de datos
Con la creación de este modelo de datos, traté de crear un modelo que sea generalmente aplicable para cada negocio. Por supuesto, siempre habrá diferencias en la normativa, políticas de empresa, etc. que requerirán personalizar el modelo para cubrir las necesidades de una nómina concreta. Sin embargo, los principios establecidos en este modelo deberían ser relevantes para la mayoría de las organizaciones.
Cabe señalar que este modelo se creó con varios supuestos:
- Los salarios acordados por contrato de trabajo son por año.
- Los salarios netos (es decir, con ciertas cantidades deducidas de impuestos, etc.) se pagan a los empleados.
- Los salarios se pagan mensualmente.
El modelo de datos consta de catorce tablas y se divide en dos áreas temáticas:
EmployeesSalaries
Para comprender mejor el modelo, es necesario analizar minuciosamente cada área temática.
Empleados
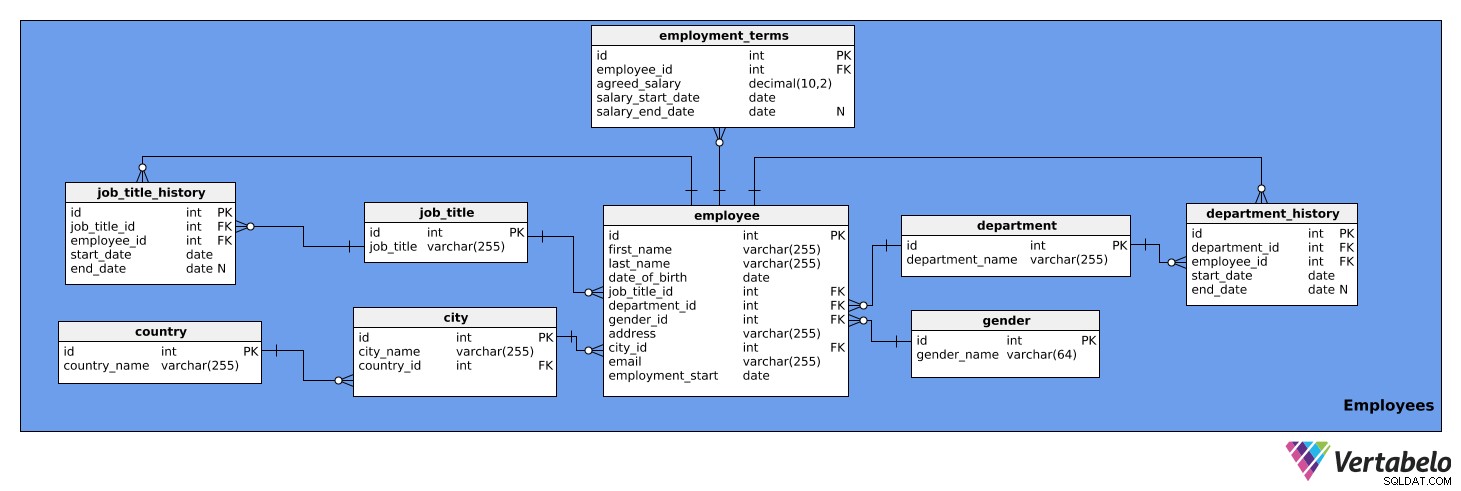
Esta área temática contiene información detallada sobre los empleados. Consta de nueve tablas:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
La primera tabla que veremos es el employee mesa. Contiene una lista de todos los empleados y sus detalles relevantes. Los atributos de la tabla son:
id– Una identificación única para cada empleado.first_name– El primer nombre del empleado.last_name– El apellido del empleado.job_title_id– Hace referencia aljob_titlemesa.department_id– Hace referencia aldepartmentmesa.gender_id– Hace referencia algendermesa.address– La dirección del empleado.city_id– Hace referencia a lacitymesa.email– El correo electrónico del empleado.employment_start– La fecha en que comenzó el empleo de esta persona.
Observe que las columnas job_title_id y department_id son redundantes, ya que se puede acceder a la información sobre los cargos y departamentos actuales desde el job_title_history y department_history mesas. Sin embargo, mantendremos estas dos columnas en esta tabla para un acceso más rápido a la información.
Los siguientes son los employment_terms mesa. Almacena datos sobre el salario de cada empleado, según lo acordado en el contrato de trabajo, y cómo ha cambiado con el tiempo. Los atributos de la tabla son:
id– Una identificación única para cada conjunto de términos de empleo.employee_id– Hace referencia alemployeemesa.agreed_salary– El salario establecido en el contrato de trabajo.salary_start_date– La fecha de inicio del salario pactado.salary_end_date– La fecha de finalización del salario pactado. Esto puede ser NULL porque un salario puede no tener un cambio planificado.
El job_title La tabla es una lista de los títulos de trabajo que se pueden asignar a varios empleados de la empresa, p. analista, chofer, secretaria, directora, etc. La mesa tiene los siguientes atributos:
id– Una identificación única para cada título de trabajo.job_title– El nombre del puesto de trabajo. Esta es la clave alternativa.
También necesitamos una tabla para almacenar el historial de títulos de trabajo de cada empleado. Necesitamos esto porque los empleados pueden ser promovidos, degradados o reasignados dentro de la empresa. El job_title_history table administrará esta información y constará de los siguientes atributos:
id– Una identificación única para la entrada histórica del puesto de trabajo.job_title_id– Hace referencia aljob_titlemesa.employee_id– Hace referencia alemployeemesa.start_date– La fecha en que el empleado ocupó por primera vez ese cargo.end_date– Cuando el empleado dejó de tener ese cargo. Esto puede ser NULL porque el empleado puede tener actualmente ese título de trabajo.
La combinación de job_title_id , employee_id y start_date es la clave alternativa para la tabla anterior. Un empleado solo puede tener asignado un puesto de trabajo en una fecha determinada.
La siguiente tabla es el department mesa. Esto simplemente enumerará todos los departamentos de la empresa, como TI, Contabilidad, Legal, etc. Contiene dos atributos:
id– Una identificación única para cada departamento.department_name– El nombre de cada departamento. Esta es la clave alternativa.
Los empleados también pueden cambiar de departamento dentro de la empresa. Por lo tanto, necesitamos tener un department_history mesa. Esta tabla almacenará lo siguiente:
id– Una identificación única para la entrada histórica de ese departamento.department_id– Hace referencia aldepartmentmesa.employee_id– Hace referencia alemployeemesa.start_date– La fecha en que un empleado comenzó a trabajar en un departamento.end_date- La fecha en que un empleado dejó de trabajar en ese departamento. Esto puede ser NULL porque el empleado aún puede trabajar allí.
La combinación de department_id , employee_id y start_date es la clave alternativa. Un empleado puede trabajar en un solo departamento a la vez.
La siguiente tabla de la que hablaremos es la city mesa. Esta es una lista de todas las ciudades relevantes. Tiene los siguientes atributos:
id– Una identificación única para cada ciudad.city_name– El nombre de la ciudad.country_id– Hace referencia alcountrymesa.
El country la mesa es la siguiente en nuestro modelo. Es simplemente una lista de países y contiene la siguiente información:
id– Una identificación única para cada país.country_name– El nombre del país. Esta es la clave alternativa.
La última tabla en esta área temática es el gender mesa. Esta tabla enumera todos los géneros. Contiene los siguientes atributos:
id– Una identificación única para cada género.gender_name– El nombre del género.
Analicemos ahora la segunda área temática.
Salarios
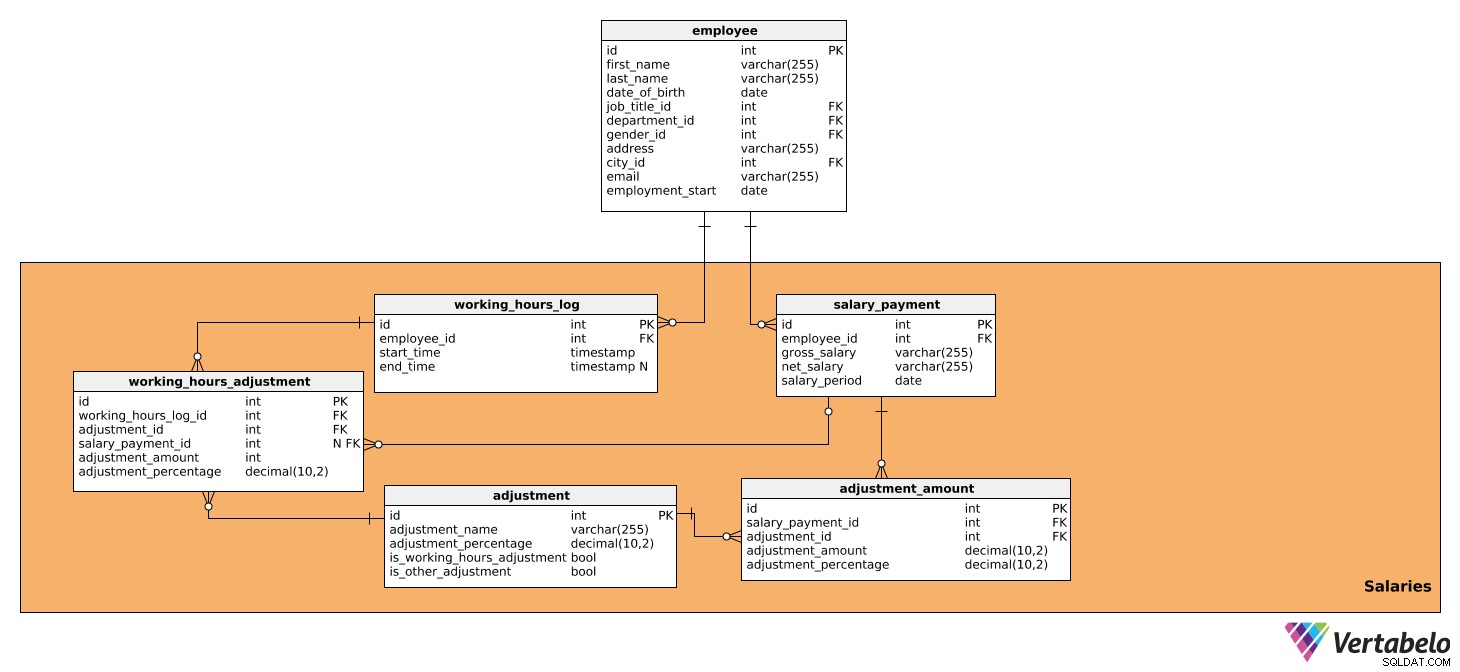
Esta área temática consta de tablas que contienen todos los datos que influyen directamente en los cálculos de salario para cada período, así como el monto a pagar. Se compone de cinco tablas:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Ahora veamos cada tabla.
La primera tabla es salary_payment . Contiene todos los detalles relevantes sobre el salario pagado a cada empleado y tiene los siguientes atributos:
id– Una identificación única para cada salario.employee_id– Hace referencia alemployeemesa.gross_salary– El salario bruto, que será la base para posteriores ajustes.net_salary– El salario neto (es decir, la cantidad que recibe el empleado después de realizar varias deducciones).salary_period– El período para el cual se calcula y paga el salario.
El segundo es el working_hours_log mesa. Contiene datos sobre el número de horas trabajadas por cada empleado, lo que puede influir en ciertos ajustes salariales. Esta tabla tiene los siguientes atributos:
id– Una identificación única para cada entrada de registro.employee_id– Hace referencia alemployeemesa.start_time– La hora en que el empleado inició sesión, es decir, comenzó a trabajar ese día.end_time– Cuando el empleado se desconectó. Puede ser NULL porque no sabremos la hora exacta hasta que el empleado cierre la sesión.
La siguiente tabla que analizaremos es working_hours_adjustment . Esta tabla solo se utilizará en el cálculo de ajustes en función de las horas trabajadas, es decir, aquellas que tengan un valor VERDADERO en is_working_hours_adjustment en el adjustment mesa. Los atributos son los siguientes:
id– Una identificación única para cada ajuste.working_hours_log_id– Hace referencia alworking_hours_logmesa.adjustment_id- Hace referencia aladjustmentmesa.salary_payment_id– Hace referencia alsalary_paymentmesa. Este valor puede ser NULL porquesalary_payment_idse usará solo una vez al mes, cuando iniciemos un cálculo de salario.adjustment_amount– El monto del ajuste.adjustment_percentage– El importe porcentual del ajuste. Esto se usará con fines históricos, ya que el porcentaje puede cambiar con el tiempo.
La siguiente tabla de la que hablaremos es el adjustment mesa. Contiene información sobre todos los ajustes utilizados para el cálculo del salario, es decir, todos los impuestos y contribuciones que tienen un impacto en el monto del salario. Asimismo, contendrá todos los ajustes que dependan de las horas trabajadas y no trabajadas, tales como aguinaldos, horas extraordinarias, licencias por enfermedad y licencias por maternidad/paternidad. Para eso, necesitamos los siguientes datos:
id– Una identificación única para cada ajuste.adjustment_name– Un nombre que describa ese ajuste.adjustment_percentage– La cantidad porcentual del ajuste particular.is_working_hours_adjustment– Esta es una marca de bandera si un ajuste depende directamente de las horas de trabajo, p. horas extras, licencia por enfermedad, etc.is_other_adjustment– Esta es una bandera que marca los ajustes que no dependen directamente de las horas trabajadas, como deducciones fiscales, contribuciones a la seguridad social, contribuciones del empleador, etc.
Después de eso, necesitamos el adjustment_amount mesa. Se utilizará para calcular todos los ajustes salariales excepto los que ya se encuentran en el working_hours_adjustment , es decir, aquellos que tienen un valor VERDADERO en is_other_adjustment en el adjustment mesa. La tabla contiene los siguientes atributos:
id– Una identificación única para cada entrada de monto de ajuste.salary_payment_id– Hace referencia alsalary_paymentmesa.adjustment_id– Hace referencia aladjustmentmesa.adjustment_amount– La cantidad de cada ajuste calculado.adjustment_percentage- El importe porcentual del ajuste. Se usará con fines históricos, ya que el porcentaje puede cambiar con el tiempo.
Déjame darte un ejemplo de cómo las tablas working_hours_log , working_hours_adjustment , adjustment y adjustment_amount trabajar juntos para calcular un salario. Todos los días, el empleado registra cuándo llega al trabajo y cuándo se va. Estos datos se pueden ver en el working_hours_log mesa. Digamos que nuestro empleado ha trabajado 10 horas extra durante un mes y, de acuerdo con la política de la empresa, se le pagará un 20% más por hora por cada hora extra. Haciendo referencia al adjustment tabla, podremos encontrar el ajuste requerido, es decir, las horas extras, que tendrán un cierto porcentaje (20%). También tendremos is_working_hours_adjustment establecido en VERDADERO. Al usar los datos de esas dos tablas, podremos calcular el ajuste y almacenarlo en el working_hours_adjustment mesa.
Ahora podemos calcular todos los demás ajustes que no dependiendo de las horas trabajadas. Esto se hará en el adjustment_amount mesa. Tal como hicimos anteriormente, haremos referencia al adjustment tabla y encuentre los ajustes que necesitamos, p. la deducción fiscal, la contribución a la seguridad social o la contribución del empleador, y sus porcentajes correspondientes. El is_other_adjustment bandera en el adjustment la tabla se establecerá en TRUE para estos ajustes.
Con base en esos cálculos, podemos almacenar los datos del salario bruto y del salario neto en el salary_payment mesa.
Al repasar este ejemplo, ¡hemos cubierto todo en nuestro modelo de datos!
¿Le gustó el modelo de datos de nómina?
Traté de crear un modelo que pudiera usarse en casi todas las situaciones. Sin embargo, es imposible incluir todos los parámetros específicos que influyen en el cálculo del salario en un artículo de esta extensión. Al cubrir los principios generales, he tratado de hacer que este modelo sea útil como base sólida para su modelo de datos de nómina.
¿Qué opinas sobre el modelo de datos de nómina? ¿Es aplicable como solución a sus necesidades de nómina? ¿Se te ocurrió algo diferente? ¿Hay problemas específicos que haya encontrado que cambiarían significativamente el modelo de datos? Dé su opinión en la sección de comentarios.