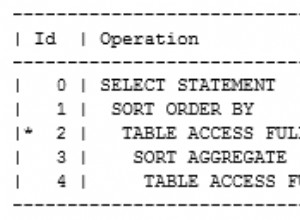
Al observar el rendimiento de las consultas, hay muchas fuentes excelentes de información dentro de SQL Server, y una de mis favoritas es el plan de consulta en sí. En las últimas versiones, especialmente a partir de SQL Server 2012, cada nueva versión ha incluido más detalles en los planes de ejecución. Si bien la lista de mejoras continúa creciendo, aquí hay algunos atributos que he encontrado valiosos:
- Motivo del plan no paralelo (SQL Server 2012)
- Diagnóstico de inserción de predicado residual (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- diagnóstico de derrames de tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Indicadores de seguimiento habilitados (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Estadísticas de ejecución de consultas del operador (SQL Server 2014 SP2, SQL Server 2016)
- Memoria máxima habilitada para una sola consulta (SQL Server 2014 SP2, SQL Server 2016 SP1)
Para ver lo que existe para cada versión de SQL Server, visite la página Showplan Schema, donde puede encontrar el esquema para cada versión desde SQL Server 2005.
Por mucho que me encanten todos estos datos adicionales, es importante tener en cuenta que cierta información es más relevante para un plan de ejecución real, en comparación con uno estimado (por ejemplo, información de derrame de tempdb). Algunos días podemos capturar y usar el plan real para solucionar problemas, otras veces tenemos que usar el plan estimado. Muy a menudo obtenemos ese plan estimado, el plan que se ha utilizado para ejecuciones potencialmente problemáticas, de la memoria caché del plan de SQL Server. Y extraer planes individuales es apropiado cuando se ajusta una consulta específica o un conjunto de consultas. Pero, ¿qué pasa cuando quieres ideas sobre dónde centrar tus esfuerzos de ajuste en términos de patrones?
La caché del plan de SQL Server es una fuente prodigiosa de información cuando se trata de ajustar el rendimiento, y no me refiero simplemente a solucionar problemas y tratar de comprender lo que se ha estado ejecutando en un sistema. En este caso, estoy hablando de extraer información de los propios planes, que se encuentran en sys.dm_exec_query_plan, almacenados como XML en la columna query_plan.
Cuando combina estos datos con información de sys.dm_exec_sql_text (para que pueda ver fácilmente el texto de la consulta) y sys.dm_exec_query_stats (estadísticas de ejecución), de repente puede comenzar a buscar no solo aquellas consultas que son las más importantes o ejecutan con más frecuencia, pero aquellos planes que contienen un tipo de unión en particular, o escaneo de índice, o aquellos que tienen el costo más alto. Esto se conoce comúnmente como minar el caché del plan, y hay varias publicaciones de blog que hablan sobre cómo hacerlo. Mi colega, Jonathan Kehayias, dice que odia escribir XML pero tiene varias publicaciones con consultas para minar el caché del plan:
- Ajuste del 'umbral de costo para el paralelismo' desde Plan Cache
- Búsqueda de conversiones de columna implícitas en la caché del plan
- Encontrar qué consultas en el caché del plan usan un índice específico
- Excavando en la caché del plan SQL:encontrando índices que faltan
- Encontrar búsquedas clave dentro de la caché del plan
Si nunca ha explorado lo que hay en el caché de su plan, las consultas en estas publicaciones son un buen comienzo. Sin embargo, el caché del plan tiene sus limitaciones. Por ejemplo, es posible ejecutar una consulta y que el plan no vaya a la memoria caché. Si tiene habilitada la opción optimizar para cargas de trabajo ad hoc, por ejemplo, en la primera ejecución, el código auxiliar del plan compilado se almacena en la memoria caché del plan, no el plan compilado completo. Pero el mayor desafío es que el caché del plan es temporal. Hay muchos eventos en SQL Server que pueden borrar el caché del plan por completo o borrarlo para una base de datos, y los planes pueden quedar fuera del caché si no se usan o eliminarse después de una recompilación. Para combatir esto, normalmente debe consultar la memoria caché del plan con regularidad o tomar una instantánea del contenido en una tabla de forma programada.
Esto cambia en SQL Server 2016 con Query Store.
Cuando una base de datos de usuario tiene habilitado el Almacén de consultas, el texto y los planes para las consultas ejecutadas en esa base de datos se capturan y conservan en tablas internas. En lugar de una vista temporal de lo que se está ejecutando actualmente, tenemos una imagen a largo plazo de lo que se ejecutó anteriormente. La cantidad de datos retenidos está determinada por la configuración de CLEANUP_POLICY, que por defecto es de 30 días. En comparación con un caché de planes que puede representar solo unas pocas horas de ejecución de consultas, los datos del Almacén de consultas cambian las reglas del juego.
Considere un escenario en el que está realizando un análisis de índice:tiene algunos índices que no se utilizan y tiene algunas recomendaciones de los DMV de índices que faltan. Los DMV de índice faltante no brindan ningún detalle sobre qué consulta generó la recomendación de índice faltante. Puede consultar el caché del plan, utilizando la consulta de la publicación Finding Missing Indexes de Jonathan. Si ejecuto eso en mi instancia local de SQL Server, obtengo un par de filas de resultados relacionados con algunas consultas que ejecuté anteriormente.

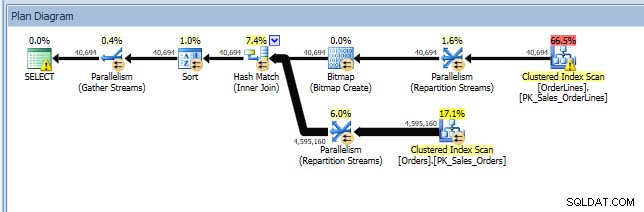
Puedo abrir el plan en Plan Explorer y veo que hay una advertencia en el operador SELECCIONAR, que es para el índice faltante:
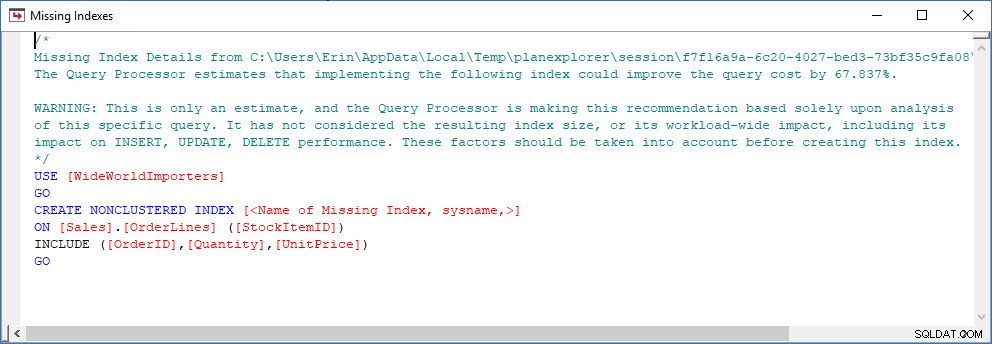
Este es un gran comienzo, pero nuevamente, mi resultado depende de lo que esté en el caché. Puedo tomar la consulta de Jonathan y modificarla para Query Store, luego ejecutarla en mi base de datos de demostración de WideWorldImporters:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
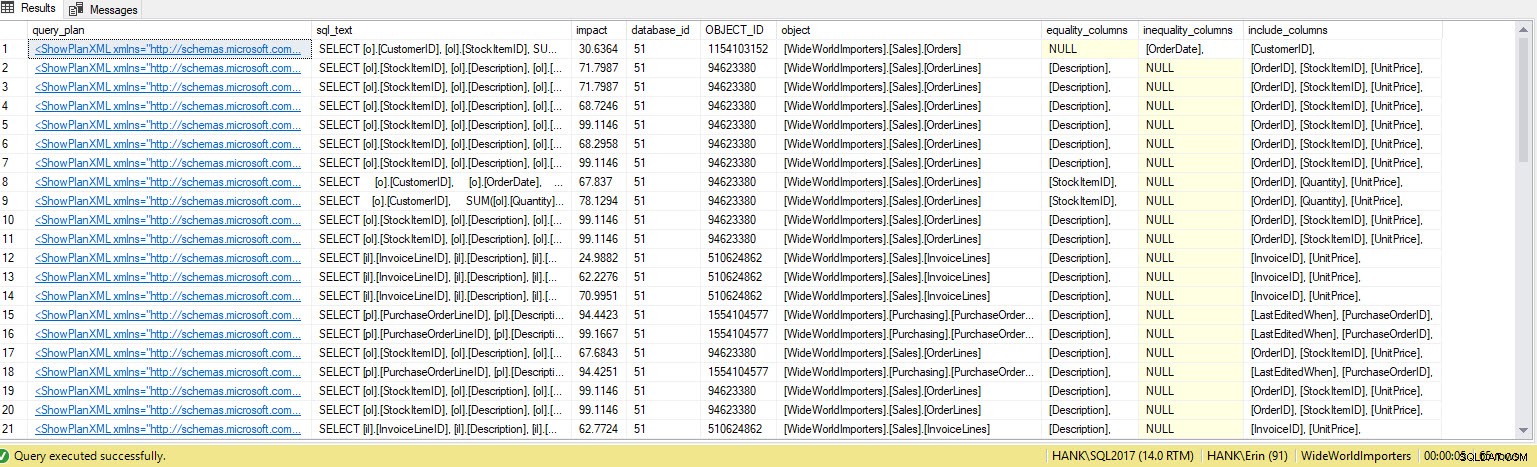
Obtengo muchas más filas en la salida. Una vez más, los datos del Almacén de consultas representan una vista más amplia de las consultas ejecutadas en el sistema, y el uso de estos datos nos brinda un método integral para determinar no solo qué índices faltan, sino también qué consultas admitirían esos índices. A partir de aquí, podemos profundizar en Query Store y observar las métricas de rendimiento y la frecuencia de ejecución para comprender el impacto de crear el índice y decidir si la consulta se ejecuta con la frecuencia suficiente para justificar el índice.
Si no está utilizando Query Store, pero está utilizando SentryOne, puede extraer esta misma información de la base de datos de SentryOne. El plan de consulta se almacena en la tabla dbo.PerformanceAnalysisPlan en un formato comprimido, por lo que la consulta que usamos es una variación similar a la anterior, pero notará que también se usa la función DESCOMPRIMIR:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; En un sistema SentryOne obtuve el siguiente resultado (y, por supuesto, al hacer clic en cualquiera de los valores de query_plan se abrirá el plan gráfico):

Un par de ventajas que ofrece SentryOne sobre Query Store es que no tiene que habilitar este tipo de recopilación por base de datos, y la base de datos monitoreada no tiene que admitir los requisitos de almacenamiento, ya que todos los datos se almacenan en el repositorio. También puede capturar esta información en todas las versiones compatibles de SQL Server, no solo en aquellas que admiten Query Store. Sin embargo, tenga en cuenta que SentryOne solo recopila consultas que superan los umbrales, como la duración y las lecturas. Puede modificar estos umbrales predeterminados, pero es un elemento a tener en cuenta al extraer la base de datos de SentryOne:es posible que no se recopilen todas las consultas. Además, la función DESCOMPRIMIR no está disponible hasta SQL Server 2016; para versiones anteriores de SQL Server, querrá:
- Haga una copia de seguridad de la base de datos de SentryOne y restáurela en SQL Server 2016 o superior para ejecutar las consultas;
- bcp los datos de la tabla dbo.PerformanceAnalysisPlan e importarlos a una nueva tabla en una instancia de SQL Server 2016;
- Consulte la base de datos de SentryOne a través de un servidor vinculado desde una instancia de SQL Server 2016; o,
- Consulte la base de datos desde el código de la aplicación que puede analizar cosas específicas después de la descompresión.
Con SentryOne, tiene la capacidad de extraer no solo el caché del plan, sino también los datos retenidos dentro del repositorio de SentryOne. Si está ejecutando SQL Server 2016 o superior y tiene habilitado el Almacén de consultas, también puede encontrar esta información en sys.query_store_plan . No está limitado solo a este ejemplo de búsqueda de índices faltantes; todas las consultas de las otras publicaciones de caché del plan de Jonathan se pueden modificar para usarlas para extraer datos de SentryOne o de Query Store. Además, si está lo suficientemente familiarizado con XQuery (o está dispuesto a aprender), puede usar el esquema del plan de presentación para descubrir cómo analizar el plan para encontrar la información que desea. Esto le brinda la capacidad de encontrar patrones y antipatrones en sus planes de consulta que su equipo puede corregir antes de que se conviertan en un problema.