Azure SQL Database es la oferta de base de datos como servicio de Microsoft que proporciona una gran flexibilidad. Está construido como parte del entorno de plataforma como servicio que brinda a los clientes monitoreo y seguridad adicionales para el producto.
Azure SQL Database es la oferta de base de datos como servicio de Microsoft que proporciona una gran flexibilidad. Está construido como parte del entorno de plataforma como servicio que brinda a los clientes monitoreo y seguridad adicionales para el producto.
Microsoft trabaja continuamente para mejorar sus productos y Azure SQL Database no es diferente. Muchas de las características más nuevas que tenemos en SQL Server se lanzaron inicialmente en Azure SQL Database, incluidas (pero no limitadas a) Always Encrypted, Dynamic Data Masking, Row Level Security y Query Store.
Nivel de precios de DTU
Cuando se lanzó por primera vez Azure SQL Database, había una sola opción de precio conocida como "DTU" o Unidades de transacción de base de datos. (Andy Mallon, @AMtwo, explica las DTU en "¿Qué diablos es una DTU?") El modelo DTU proporciona tres niveles de servicio, básico, estándar y premium. El nivel básico proporciona hasta 5 DTU con almacenamiento estándar. El nivel estándar admite de 10 a 3000 DTU con almacenamiento estándar y el nivel premium admite de 125 a 4000 DTU con almacenamiento premium, que es muchísimo más rápido que el almacenamiento estándar.
Nivel de precios de vCore
Avance rápido unos años después del lanzamiento de Azure SQL Database cuando Azure SQL Managed Instance estaba en versión preliminar pública y se anunciaron "vCores" (núcleos virtuales) para Azure SQL Database. Estos introdujeron los niveles críticos para el negocio y de uso general con procesadores Gen 4 y Gen 5. Gen 5 es la opción de hardware principal ahora para la mayoría de las regiones, ya que Gen 4 está obsoleto.
Gen 5 admite tan solo 2 núcleos virtuales y hasta 80 núcleos virtuales con RAM asignada a 5,1 GB por núcleo virtual. El nivel de uso general proporciona almacenamiento remoto con un máximo de IOPS de datos que van desde 640 para una base de datos de 2 núcleos virtuales hasta 25 600 para una base de datos de 80 núcleos virtuales. El nivel crítico para la empresa tiene SSD local que proporciona un rendimiento de E/S mucho mejor con un máximo de IOPS de datos que van desde 8000 para una base de datos de 2 núcleos virtuales hasta 204 800 para una base de datos de 80 núcleos virtuales. Tanto los niveles de uso general como los críticos para la empresa tienen un máximo de 4096 GB para el almacenamiento, y esto se convirtió en una limitación para muchos clientes.
Base de datos de hiperescala
Para solucionar el límite de 4 TB de Azure SQL Database, Microsoft creó el nivel de hiperescala. Hiperescala permite a los clientes escalar hasta 100 TB de tamaño de base de datos, además de proporcionar una escalabilidad horizontal rápida para nodos de solo lectura. También puede escalar hacia arriba y hacia abajo fácilmente dentro del modelo vCore. Las bases de datos de hiperescala se aprovisionan mediante núcleos virtuales. Con Gen 5, una base de datos Hiperescala puede usar entre 2 y 80 núcleos virtuales y entre 500 y 204 800 IOPS. Hiperescala logra un alto rendimiento de cada nodo de cómputo que tiene cachés basados en SSD, lo que ayuda a minimizar los viajes de ida y vuelta de la red para obtener datos. Hay una gran cantidad de tecnología increíble involucrada con Hiperescala en la forma en que está diseñada para usar servidores de páginas y cachés basados en SSD. Le recomiendo que eche un vistazo al diagrama que desglosa la arquitectura y cómo funciona todo en este artículo.
Base de datos sin servidor
Otra solicitud muy común de los clientes fue la capacidad de aumentar y reducir automáticamente su base de datos SQL de Azure a medida que aumentan y disminuyen las cargas de trabajo. Tradicionalmente, los clientes han tenido la capacidad de escalar hacia arriba y hacia abajo mediante programación mediante PowerShell, Azure Automation y otros métodos. Microsoft tomó esa idea y creó un nuevo nivel de cómputo llamado Azure SQL Database sin servidor, que estuvo disponible para el público en general en noviembre de 2019. Permiten al cliente establecer cantidades mínimas y máximas de núcleos virtuales. De esta manera, pueden saber que siempre hay un nivel de cómputo mínimo disponible y siempre pueden escalar automáticamente a un nivel de cómputo designado. También existe la posibilidad de configurar un retraso de pausa automática. Esta configuración le permite pausar automáticamente la base de datos después de una cantidad específica de tiempo que la base de datos ha estado inactiva. Cuando una base de datos ingresa a la etapa de pausa automática, los costos de cómputo se reducen a cero y solo se incurre en costos de almacenamiento. El costo total de serverless es la suma del costo de cómputo y el costo de almacenamiento. Cuando el uso de cómputo se encuentra entre los límites mínimo y máximo, el costo de cómputo se basa en los núcleos virtuales y la memoria utilizada. Si el uso real está por debajo del valor mínimo, el costo de cómputo se basa en los núcleos virtuales mínimos y la memoria mínima configurada.
El nivel sin servidor tiene el potencial de ahorrar a los clientes una gran cantidad de dinero y, al mismo tiempo, les brinda la capacidad de proporcionar una experiencia de usuario de base de datos consistente con la base de datos que puede ampliarse según lo requiera la demanda.
Piscinas Elásticas
Azure SQL Database tiene un modelo de recursos compartidos que permite a los clientes tener una mayor utilización de recursos. Un cliente puede crear un grupo elástico y mover bases de datos a ese grupo. Luego, cada base de datos puede comenzar a compartir recursos predefinidos dentro de ese grupo. Los grupos elásticos se pueden configurar mediante el modelo de precios de DTU o el modelo de núcleo virtual. Los clientes determinan la cantidad de recursos que el grupo elástico necesita para manejar la carga de trabajo de todas sus bases de datos. Los límites de recursos se pueden configurar por base de datos para que una base de datos no pueda consumir todo el grupo. Los grupos elásticos son excelentes para los clientes que tienen que administrar una gran cantidad de bases de datos o escenarios de múltiples inquilinos.
Nueva configuración de hardware para el nivel informático aprovisionado
Las configuraciones de hardware Gen4/Gen5 se consideran "memoria y cómputo equilibrados". Esto funciona bien para muchas cargas de trabajo de SQL Server; sin embargo, ha habido casos de uso para una latencia de CPU más baja y una velocidad de reloj más alta para cargas de trabajo con uso intensivo de CPU y una necesidad de memoria más alta por núcleo virtual. Microsoft una vez más entregó y creó una configuración de hardware optimizada para cómputo y memoria. Estos están actualmente en versión preliminar y solo están disponibles en ciertas regiones.
En el nivel aprovisionado de uso general, puede seleccionar la serie Fsv2, que puede ofrecer más rendimiento de CPU por núcleo virtual que el hardware Gen 5. En general, el tamaño de 72 núcleos virtuales puede proporcionar más rendimiento de la CPU que el de 80 núcleos virtuales de 5.ª generación al proporcionar una latencia de CPU más baja y velocidades de reloj más altas. La serie Fsv2 tiene menos memoria y tempdb por vCore que Gen 5, por lo que habrá que tenerlo en cuenta.
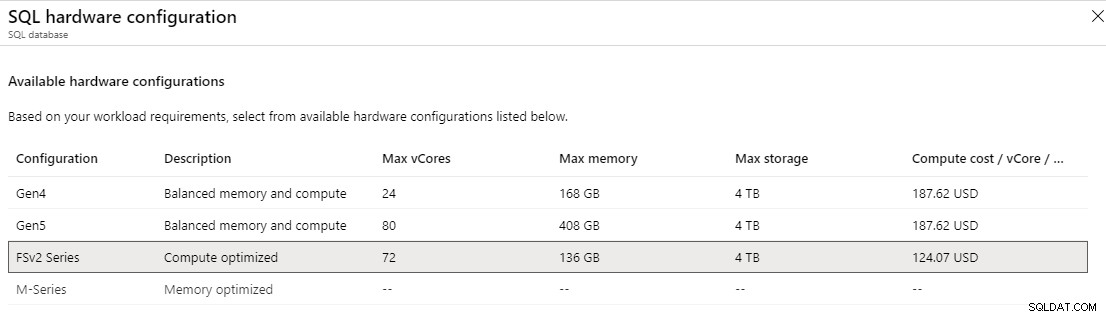
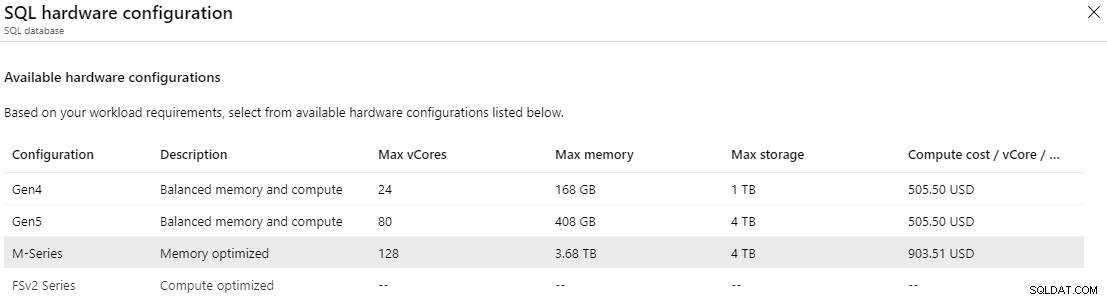
En el nivel aprovisionado crítico para la empresa, puede acceder a la serie M, que está optimizada para memoria. La serie M ofrece 29 GB por núcleo virtual en comparación con los 5,1 GB por núcleo virtual en la configuración de "equilibrio de memoria y cómputo". Con la serie M, puede escalar vCore hasta 128, lo que proporcionaría hasta 3,7 TB de memoria. Para habilitar la serie M, debe tener un contrato de pago por uso o Enterprise y abrir una solicitud de soporte. Incluso entonces, la serie M actualmente solo está disponible en el este de EE. UU., el norte de Europa, el oeste de Europa y el oeste de EE. UU. 2, y también puede tener una disponibilidad limitada en otras regiones.
Conclusión
Azure SQL Database es una plataforma de base de datos rica en características que ofrece una amplia gama de opciones para computación y escala. Los clientes pueden configurar el proceso para una base de datos única o un grupo elástico mediante DTU o núcleos virtuales. Para bases de datos con un gran requisito de almacenamiento o lectura escalable, se puede utilizar Hiperescala. Para los clientes con diferentes requisitos de carga de trabajo, la tecnología sin servidor se puede usar para escalar automáticamente hacia arriba y hacia abajo a medida que cambian las demandas de su carga de trabajo. Una de las novedades de Azure SQL Database es la característica de vista previa de una configuración de hardware optimizada para computación y memoria para aquellos clientes que necesitan una CPU de menor latencia o aquellos con un alto requisito de memoria a CPU.
Para obtener más información sobre los recursos de Azure, consulte mis artículos anteriores:
- Opciones de ajuste del rendimiento de Azure SQL Database
- Consideraciones sobre el rendimiento de Azure SQL Managed Instance
- Nuevos tamaños de nivel estándar de Azure SQL Database
- Cerrar la brecha de Azure:Instancias administradas
- Migración de bases de datos a Azure SQL Database