Los administradores de bases de datos antiguos tienen historias sobre Oracle que proporciona un "SQL*Loader" sin ningún "SQL*Unloader" porque Larry Ellison no quería que sus clientes se mudaran. Esto ha cambiado:hay una manera fácil de exportar a CSV con un simple set sqlformat csv en SQLcl. Siga el blog de Jeff Smith para saber más al respecto.
Aquí hay un ejemplo. Quería mover algunos datos de muestra de Oracle a YugabyteDB para comparar el tamaño. Tengo una base de datos autónoma siempre gratuita, que incluye el esquema de muestra de SSB. Hay una tabla LINEORDER que tiene unos cientos de GB. Obtendré el DDL con dbms_metadata . El único cambio que tuve que hacer fue sub(" NUMBER,"," NUMERIC,") y deshabilité las restricciones y las cláusulas de colación.
Por supuesto, existen herramientas profesionales para convertir un esquema de Oracle a PostgreSQL. El buen viejo ora2pg, o AWS SCT, que también es excelente para evaluar el nivel de cambios que requiere una migración. Pero para algo rápido, soy bueno con awk 😉
Entonces la exportación es fácil con set sqlformat csv y las pocas configuraciones para generar solo datos como feedback off pagesize 0 long 999999999 verify off . Canalizo todo eso a awk que construye el \copy comando que toma estas líneas CSV tal cual. Me gusta hacer pequeños pasos y luego crear comandos COPY de 10000 líneas con (NR-data)%10000 , data se establece al principio del comando COPY. Enviarlos en paralelo sería fácil, pero es posible que no lo necesite porque YugabyteDB es multiproceso.
Aquí está el script que uso:tengo mi billetera de Autonomous Database en TNS_ADMIN, SQLcl instalado en mi casa (un ARM de nivel gratuito de Oracle en el que también ejecuto mi laboratorio YugabyteDB).
{
TNS_ADMIN=/home/opc/wallet_oci_fra ~/sqlcl/bin/sql -s demo/",,P455w0rd,,"@o21c_tp @ /dev/stdin SSB LINEORDER <<SQL
set feedback off pagesize 0 long 999999999 verify off
whenever sqlerror exit failure
begin
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'SEGMENT_ATTRIBUTES', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'STORAGE', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'CONSTRAINTS', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'REF_CONSTRAINTS', false);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'SQLTERMINATOR', true);
dbms_metadata.set_transform_param(dbms_metadata.session_transform, 'COLLATION_CLAUSE', 'NEVER');
end;
/
set sqlformat default
select dbms_metadata.get_ddl('TABLE','&2','&1') from dual ;
set sqlformat csv
select * from "&1"."&2" ;
SQL
} | awk '
/^ *CREATE TABLE /{
table=$0 ; sub(/^ *CREATE TABLE/,"",table)
print "drop table if exists "table";"
schema=table ; sub(/\"[.]\".*/,"\"",schema)
print "create schema if not exists "schema";"
}
/^"/{
data=NR-1
print "\\copy "table" from stdin with csv header"
}
data<1{
sub(" NUMBER,"," numeric,")
}
{print}
data>0 && (NR-data)%1000000==0{
print "\\."
print "\\copy "table" from stdin with csv"
}
END{
print "\\."
}
'
La salida se puede canalizar directamente a psql 😎
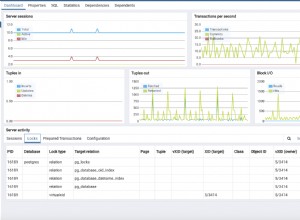
Aquí está mi pantalla al iniciar la carga:

Es un laboratorio, medir el tiempo transcurrido no tiene sentido, pero miré rows_inserted estadísticas para verificar que todo se distribuye a los 3 nodos de mi base de datos SQL distribuida. Incluso con una sola sesión de cliente, la carga se distribuye en todo el clúster.
Esto funciona igual para PostgreSQL porque es la misma API:YugabyteDB usa PostgreSQL además del almacenamiento distribuido.
Todos los componentes de esta prueba son gratuitos y fáciles de usar:
- La máquina virtual está en Oracle Cloud Free tier (ARM), Oracle Database es una base de datos autónoma gratuita 👉 https://www.oracle.com/cloud/free/
- PostgreSQL es de código abierto y gratuito 👉 https://www.postgresql.org
- YugabyteDB es de código abierto y gratuito 👉 https://www.yugabyte.com