En esta publicación, discutiremos el mecanismo de bloqueo de SQL Server y cómo monitorear el bloqueo de SQL Server con las vistas de administración dinámica estándar de SQL Server. Antes de comenzar a explicar la arquitectura de bloqueo de SQL Server, tomemos un momento para describir qué es la base de datos ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad). La base de datos ACID se puede explicar como teoría de bases de datos. Si una base de datos se llama base de datos relacional, debe cumplir con los requisitos de Atomicidad, Consistencia, Aislamiento y Durabilidad. Ahora, explicaremos estos requisitos brevemente.
Atomicidad :Refleja el principio de indivisibilidad que describimos como la característica principal del proceso de transacción. Un bloque de transacción no se puede dejar desatendido. La mitad del bloque de transacciones restante provoca inconsistencias en los datos. O se realiza toda la transacción o la transacción vuelve al principio. Es decir, todos los cambios realizados por la transacción se deshacen y vuelven a su estado anterior.
Coherencia :Hay una regla que establece la subestructura de la regla de no divisibilidad. Los datos de transacciones deben proporcionar consistencia. Es decir, si la operación de actualización se realiza en una transacción, se deben realizar todas las transacciones restantes o se debe cancelar la operación de actualización. Estos datos son muy importantes en términos de consistencia.
Aislamiento :Este es un paquete de solicitud para cada base de datos de transacciones. Los cambios realizados por un paquete de solicitud deben ser visibles para otra transacción antes de que se complete. Cada transacción debe procesarse por separado. Todas las transacciones deben ser visibles para otra transacción después de que ocurran.
Durabilidad: Las transacciones pueden realizar operaciones complejas con datos. Para asegurar todas estas transacciones, deben ser resistentes a un error de transacción. Los problemas del sistema que puedan ocurrir en SQL Server deben estar preparados y resistentes frente a fallas de energía, sistema operativo u otros errores inducidos por el software.
Transacción: La transacción es la pila más pequeña del proceso que no se puede dividir en partes más pequeñas. Además, algunos grupos de procesos de transacciones se pueden realizar secuencialmente, pero como explicamos en el principio de atomicidad, si falla una de las transacciones, todos los bloques de transacciones fallarán.
Bloqueo: El bloqueo es un mecanismo para garantizar la coherencia de los datos. SQL Server bloquea los objetos cuando comienza la transacción. Cuando se completa la transacción, SQL Server libera el objeto bloqueado. Este modo de bloqueo se puede cambiar según el tipo de proceso de SQL Server y el nivel de aislamiento. Estos modos de bloqueo son:
Jerarquía de bloqueo: SQL Server tiene una jerarquía de bloqueo que adquiere objetos de bloqueo en esta jerarquía. Una base de datos se encuentra en la parte superior de la jerarquía y la fila se encuentra en la parte inferior. La siguiente imagen ilustra la jerarquía de bloqueo de SQL Server.

Bloqueos compartidos (S): Este tipo de bloqueo se produce cuando es necesario leer el objeto. Este tipo de bloqueo no causa muchos problemas.
Bloqueos exclusivos (X): Cuando se produce este tipo de bloqueo, se produce para evitar que otras transacciones modifiquen o accedan a un objeto bloqueado.
Actualizar (U) Bloqueos: Este tipo de candado es similar al candado exclusivo pero tiene algunas diferencias. Podemos dividir la operación de actualización en diferentes fases:fase de lectura y fase de escritura. Durante la fase de lectura, SQL Server no desea que otras transacciones tengan acceso a este objeto para modificarlo. Por esta razón, SQL Server usa el bloqueo de actualización.
Bloqueos por intención: El bloqueo de intención se produce cuando SQL Server desea adquirir el bloqueo compartido (S) o el bloqueo exclusivo (X) en algunos de los recursos inferiores en la jerarquía de bloqueo. En la práctica, cuando SQL Server adquiere un bloqueo en una página o fila, se requiere el bloqueo de intención en la tabla.
Después de todas estas breves explicaciones, intentaremos encontrar una respuesta a cómo identificar las cerraduras. SQL Server ofrece muchas vistas de administración dinámica para acceder a las métricas. Para identificar bloqueos de SQL Server, podemos usar sys.dm_tran_locks vista. En esta vista, podemos encontrar mucha información sobre los recursos del administrador de bloqueo actualmente activos.
En el primer ejemplo, crearemos una tabla de demostración que no incluye ningún índice e intentaremos actualizar esta tabla de demostración.
CREATE TABLE TestBlock (Id INT , Nm VARCHAR(100)) INSERT INTO TestBlock values(1,'CodingSight') In this step, we will create an open transaction and analyze the locked resources. BEGIN TRAN UPDATE TestBlock SET Nm='NewValue_CodingSight' where Id=1 select @@SPID
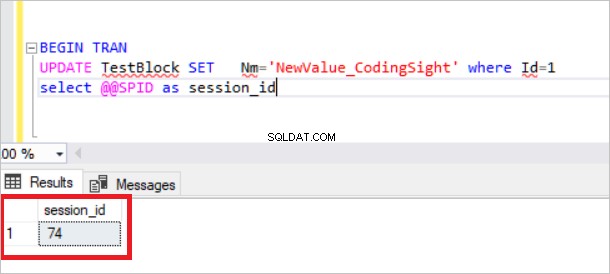
Ahora, revisaremos la vista sys.dm_tran_lock.
select * from sys.dm_tran_locks WHERE request_session_id=74
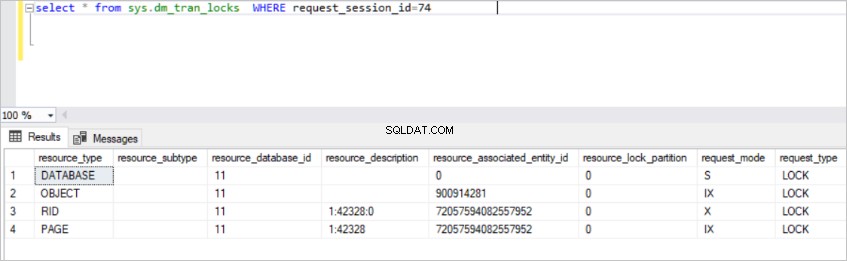
Esta vista devuelve mucha información sobre los recursos de bloqueo activos. Pero no es posible entender algunos de los datos en esta vista. Por esta razón, tenemos que unirnos a sys.dm_tran_locks ver a otras vistas.
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
and request_session_id=74
ORDER BY request_session_id, resource_associated_entity_id
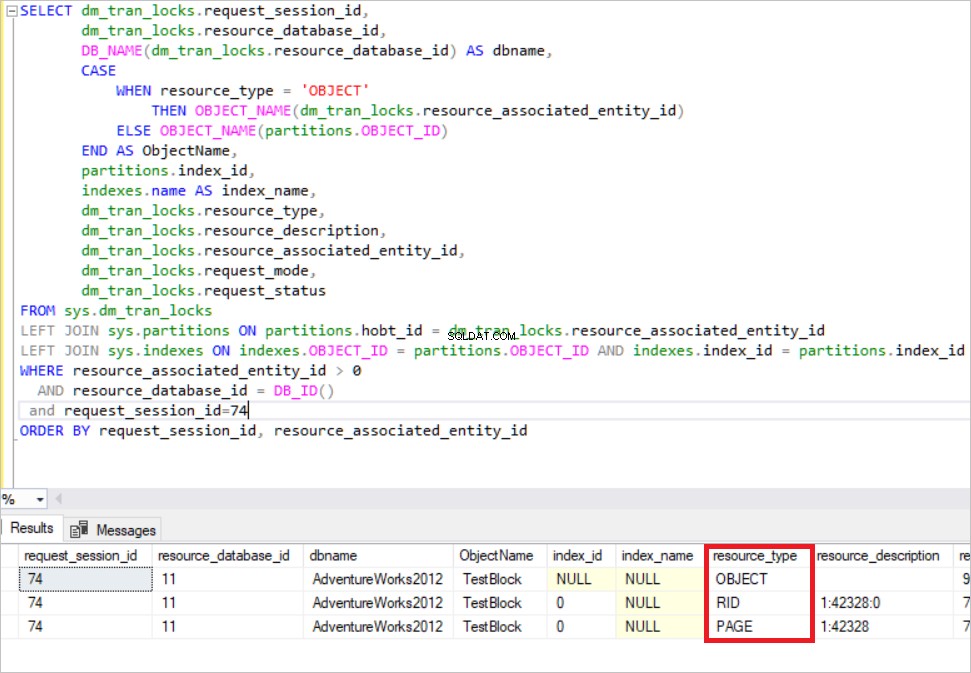
En la imagen de arriba, puede ver los recursos bloqueados. SQL Server adquiere el bloqueo exclusivo en esa fila. (RID :un identificador de fila utilizado para bloquear una sola fila dentro de un montón) Al mismo tiempo, SQL Server adquiere el bloqueo exclusivo de intención en la página y el TestBlock mesa. Significa que ningún otro proceso puede leer este recurso hasta que SQL Server libere los bloqueos. Este es el mecanismo de bloqueo básico en SQL Server.
Ahora, completaremos algunos datos sintéticos en nuestra tabla de prueba.
TRUNCATE TABLE TestBlock DECLARE @K AS INT=0 WHILE @K <8000 BEGIN INSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' ) SET @example@sqldat.com+1 END After completing this step, we will run two queries and check the sys.dm_tran_locks view. BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<5000
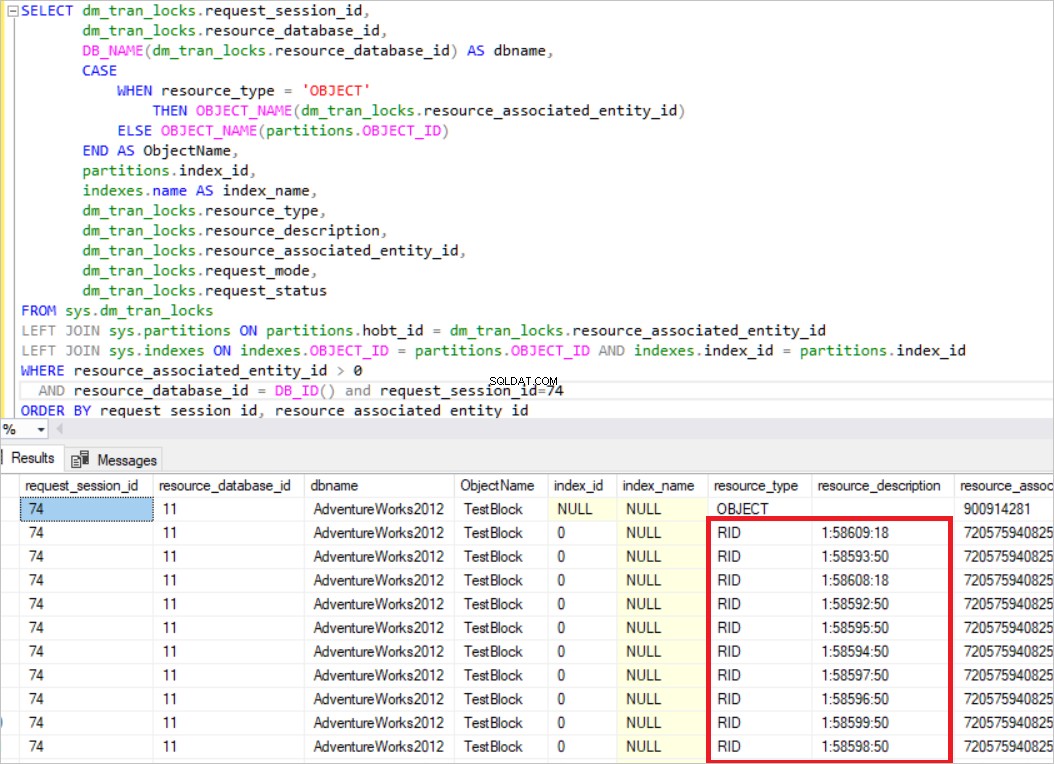
En la consulta anterior, SQL Server adquiere el bloqueo exclusivo en cada fila. Ahora, ejecutaremos otra consulta.
BEGIN TRAN UPDATE TestBlock set Nm ='New_Value' where Id<7000
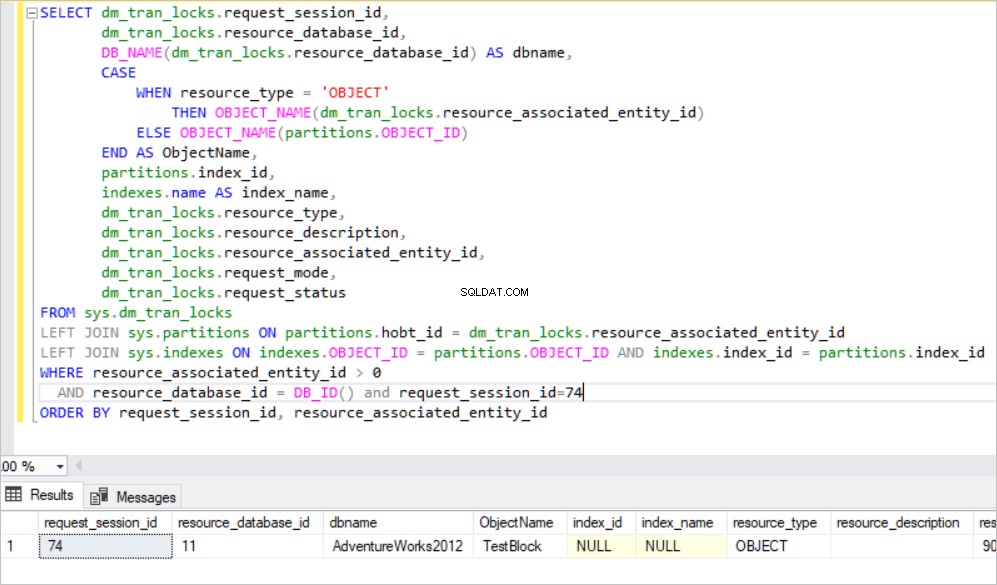
En la consulta anterior, SQL Server crea el bloqueo exclusivo en la tabla, porque SQL Server intenta adquirir muchos bloqueos RID para estas filas que se actualizarán. Este caso provoca un gran consumo de recursos en el motor de la base de datos. Por lo tanto, SQL Server mueve automáticamente este bloqueo exclusivo a un objeto de nivel superior que se encuentra en la jerarquía de bloqueo. Definimos este mecanismo como Lock Escalation. La escalada de bloqueo se puede cambiar en el nivel de la tabla.
ALTER TABLE XX_TableName SET ( LOCK_ESCALATION = AUTO -- or TABLE or DISABLE ) GO
Me gustaría agregar algunas notas sobre la escalada de bloqueo. Si tiene una tabla particionada, podemos configurar la escalada al nivel de partición.
En este paso, ejecutaremos una consulta que crea un bloqueo en la tabla AdventureWorks HumanResources. Esta tabla tiene índices agrupados y no agrupados.
BEGIN TRAN UPDATE [HumanResources].[Department] SET Name='NewName' where DepartmentID=1
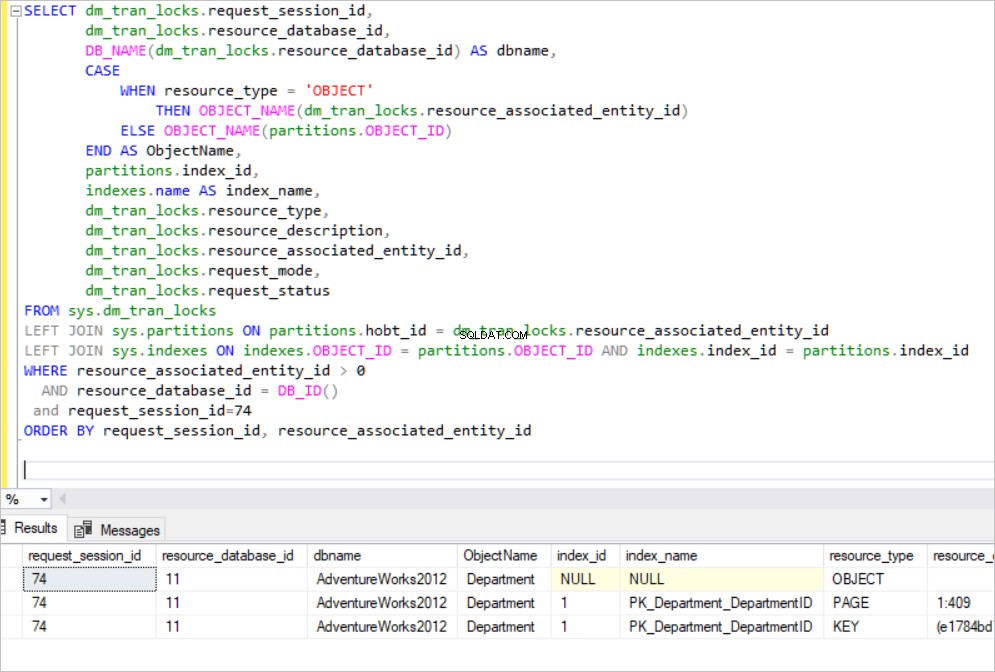
Como puede ver en el panel de resultados a continuación, nuestra transacción adquiere bloqueos exclusivos en la clave de índice de clúster PK_Department_DepartmentID y también adquiere bloqueos exclusivos en la clave de índice no agrupada AK_Department_Name. Ahora, podemos hacer esta pregunta "¿Por qué SQL Server bloquea un índice no agrupado?"
El Nombre la columna está indexada en el índice no agrupado AK_Department_Name e intentamos cambiar el Nombre columna. En este caso, SQL Server necesita cambiar los índices no agrupados en esa columna. El nivel de hoja de índice no agrupado incluye todos los valores CLAVE ordenados.
Conclusiones
En este artículo, mencionamos las líneas principales del mecanismo de bloqueo de SQL Server y consideramos el uso de sys.dm_tran_locks. La vista sys.dm_tran_locks devuelve mucha información sobre los recursos de bloqueo actualmente activos. Si busca en Google, puede encontrar muchas consultas de muestra sobre esta vista.
Referencias
Guía de control de versiones de filas y bloqueo de transacciones de SQL Server
SQL Server, objeto de bloqueo