Según Wikipedia, "una inserción masiva es un proceso o método proporcionado por un sistema de gestión de base de datos para cargar varias filas de datos en una tabla de base de datos". Si ajustamos esta explicación de acuerdo con la instrucción BULK INSERT, la inserción masiva permite importar archivos de datos externos a SQL Server. Supongamos que nuestra organización tiene un archivo CSV de 1.500.000 filas y queremos importar este archivo a una tabla en particular en SQL Server, por lo que podemos usar fácilmente la instrucción BULK INSERT en SQL Server. Ciertamente, podemos encontrar varias metodologías de importación para manejar este proceso de importación de archivos CSV, p. podemos usar bcp (b ulk c opia p programa), asistente de importación y exportación de SQL Server o paquete de servicio de integración de SQL Server. Sin embargo, la declaración BULK INSERT es mucho más rápida y robusta que usar otras metodologías. Otra ventaja de la declaración de inserción masiva es que ofrece varios parámetros que ayudan a determinar la configuración del proceso de inserción masiva.
Al principio, comenzaremos con una muestra muy básica y luego pasaremos por varios escenarios sofisticados.
Preparación
Antes de comenzar con las muestras, necesitamos un archivo CSV de muestra. Por lo tanto, descargaremos un archivo CSV de muestra del sitio web E for Excel, donde puede encontrar varios archivos CSV de muestra con un número de fila diferente. Puedes encontrar el enlace al final del artículo. En nuestros escenarios, utilizaremos 1.500.000 registros de ventas. Descargue un archivo zip, luego descomprima el archivo CSV y colóquelo en su disco local.

Importar archivo CSV a la tabla de SQL Server
Escenario-1:el destino y el archivo CSV tienen el mismo número de columnas
En este primer escenario, importaremos el archivo CSV a la tabla de destino de la forma más simple. Coloqué mi archivo CSV de muestra en la unidad C:y ahora crearemos una tabla en la que importaremos datos del archivo CSV.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
La siguiente instrucción BULK INSERT importa el archivo CSV a la tabla Ventas.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
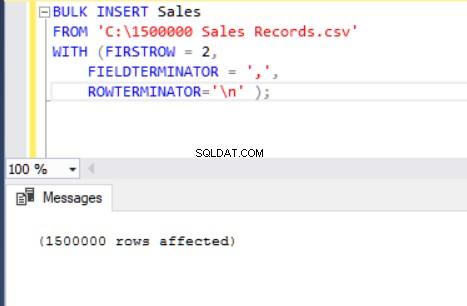
Ahora, explicaremos los parámetros de la instrucción de inserción masiva anterior.
El parámetro FIRSTROW especifica el punto de inicio de la declaración de inserción. En el siguiente ejemplo, queremos omitir los encabezados de las columnas, por lo que establecemos este parámetro en 2.

FIELDTERMINATOR define el carácter que separa los campos entre sí. SQL Server detecta cada campo de esa manera. ROWTERMINATOR no difiere mucho de FIELDTERMINATOR. Define el carácter de separación de filas. En el archivo CSV de muestra, fieldterminator es muy claro y es una coma (,). Pero, ¿cómo podemos detectar un terminador de campo? Abra el archivo CSV en el Bloc de notas++ y luego vaya a Ver->Mostrar símbolo->Mostrar todas las cartas, y luego encuentre los caracteres CRLF al final de cada campo.
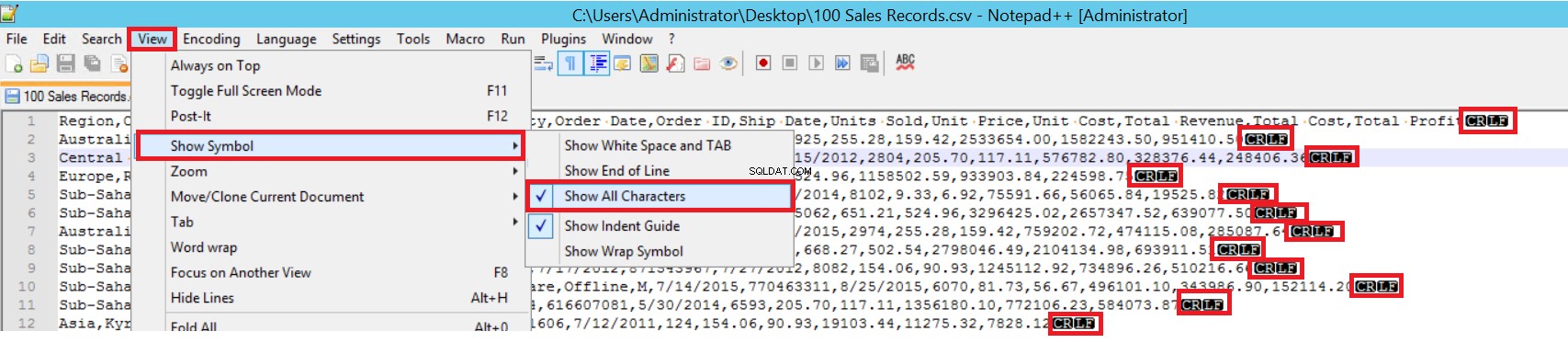
CR =Retorno de carro y LF =Avance de línea. Se utilizan para marcar un salto de línea en un archivo de texto y se indica con el carácter "\n" en la declaración de inserción masiva.
Otro método para importar un archivo CSV a una tabla con la ayuda de la inserción masiva es usar el parámetro FORMATO. Tenga en cuenta que el parámetro FORMAT solo está disponible en SQL Server 2017 y versiones posteriores.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
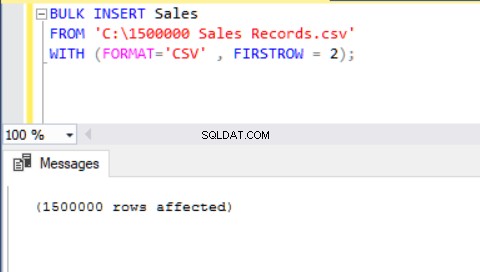
Ahora analizaremos otro escenario.
Escenario 2:la tabla de destino tiene más columnas que el archivo CSV
En este escenario, agregaremos una clave principal a la tabla Ventas y este caso rompe las asignaciones de columnas de igualdad. Ahora, crearemos la tabla Ventas con una clave principal, intentaremos importar el archivo CSV a través del comando de inserción masiva y luego obtendremos un error.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
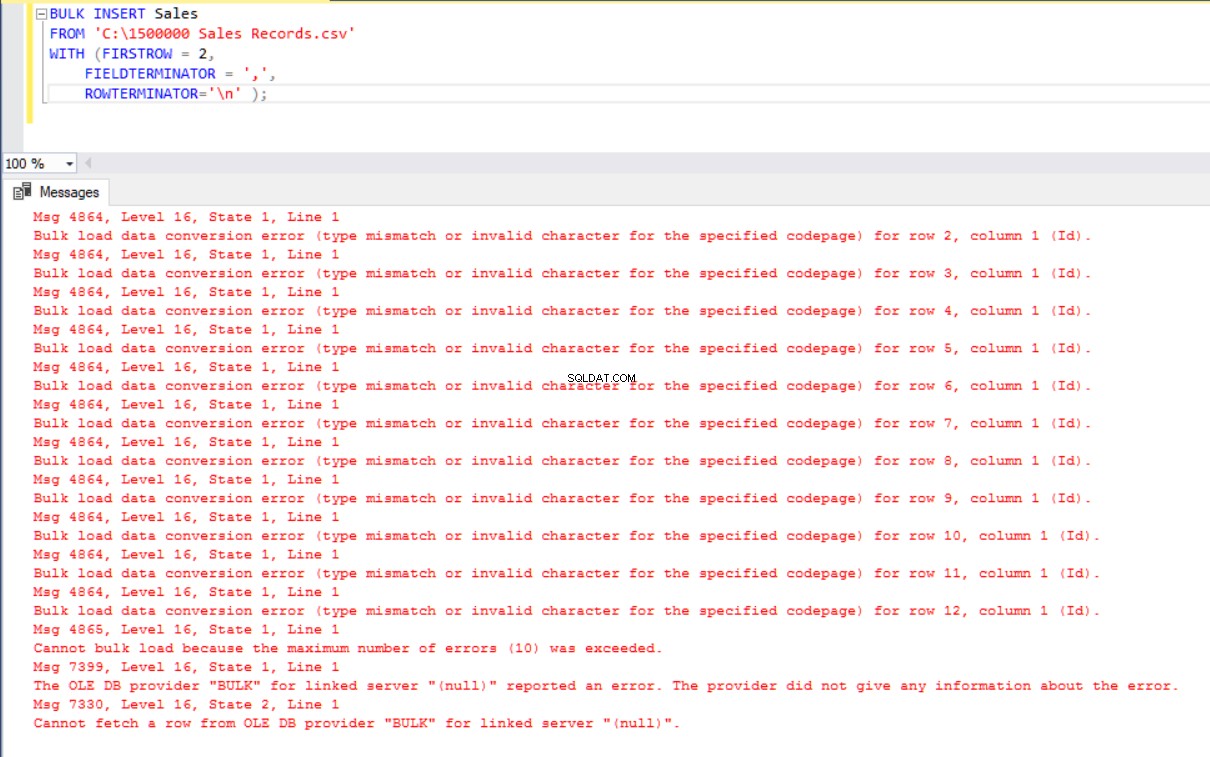
Para solucionar este error, crearemos una vista de la tabla Ventas con columnas de asignación al archivo CSV e importaremos los datos CSV sobre esta vista a la tabla Ventas.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Escenario 3:¿Cómo separar y cargar archivos CSV en lotes pequeños?
SQL Server adquiere un bloqueo en la tabla de destino durante la operación de inserción masiva. De forma predeterminada, si no configura el parámetro BATTSIZE, SQL Server abre una transacción e inserta todos los datos CSV en esta transacción. Sin embargo, si establece el parámetro TAMAÑO DEL LOTE, SQL Server divide los datos CSV según el valor de este parámetro. En el siguiente ejemplo, dividiremos todos los datos CSV en varios conjuntos de 300 000 filas cada uno. Por lo tanto, los datos se importarán 5 veces.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
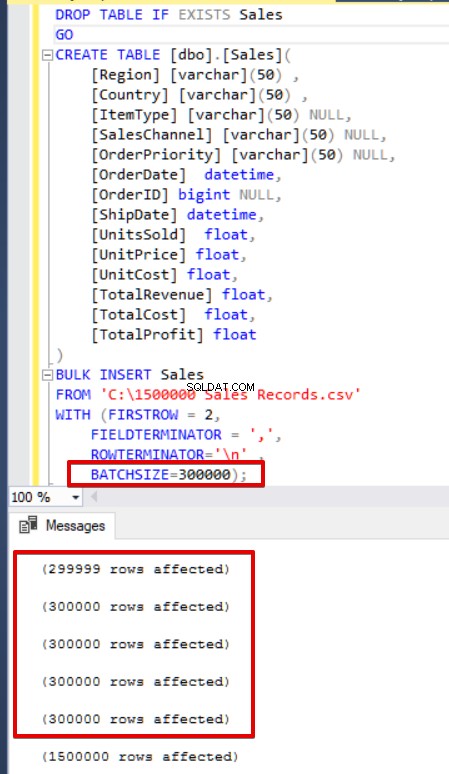
Si su declaración de inserción masiva no incluye el parámetro de tamaño de lote (BATCHSIZE), se producirá un error y SQL Server revertirá todo el proceso de inserción masiva. Por otro lado, si establece el parámetro de tamaño de lote en la declaración de inserción masiva, SQL Server revertirá solo esta parte dividida donde ocurrió el error. No existe un valor óptimo o mejor para este parámetro porque este valor de parámetro se puede cambiar de acuerdo con los requisitos del sistema de su base de datos.
Escenario-4:Cómo cancelar la ¿proceso de importación al recibir un error?
En algunos escenarios de copia masiva, si ocurre un error, es posible que deseemos cancelar el proceso de copia masiva o continuar con el proceso. El parámetro MAXERRORS nos permite especificar el número máximo de errores. Si el proceso de inserción masiva alcanza este valor máximo de error, la operación de importación masiva se cancelará y revertirá. El valor predeterminado para este parámetro es 10.
En el siguiente ejemplo, corromperemos intencionalmente el tipo de datos en 3 filas del archivo CSV y estableceremos el parámetro MAXERRORS en 2. Como resultado, toda la operación de inserción masiva se cancelará porque el número de error excede el parámetro de error máximo.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
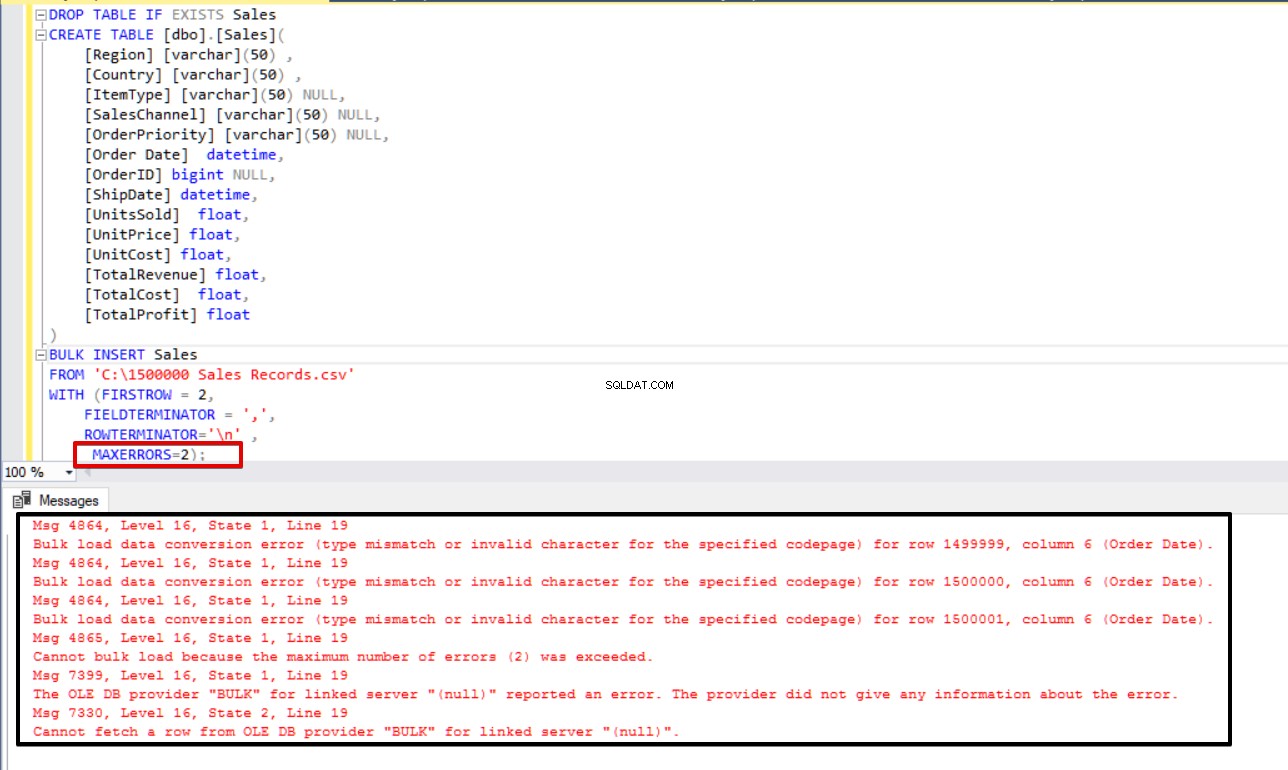
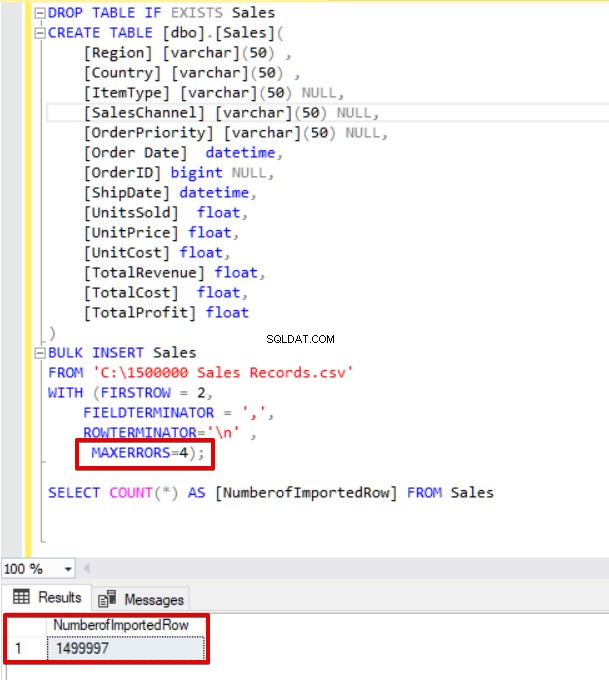
Ahora cambiaremos el parámetro de error máximo a 4. Como resultado, la declaración de inserción masiva omitirá estas filas e insertará las filas estructuradas de datos adecuadas y completará el proceso de inserción masiva.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
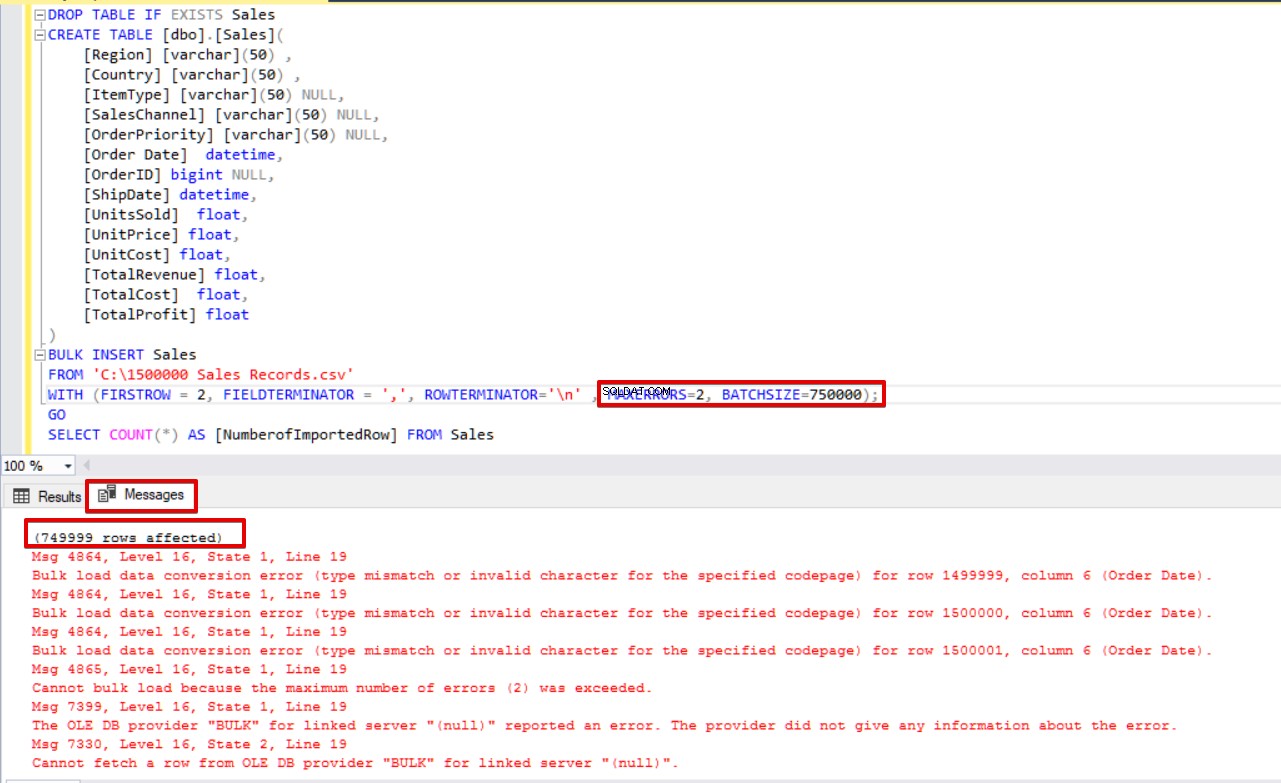
Además, si usamos los parámetros de tamaño de lote y error máximo al mismo tiempo, el proceso de copia masiva no cancelará toda la operación de inserción, solo cancelará la parte dividida.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
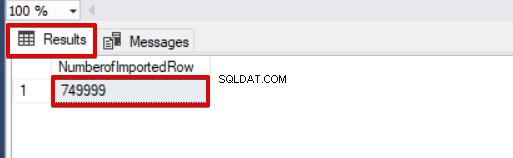
En esta primera parte de esta serie de artículos, discutimos los conceptos básicos del uso de la operación de inserción masiva en SQL Server y analizamos varios escenarios que están cerca de los problemas de la vida real.
Inserción masiva de SQL Server:parte 2
Enlaces útiles:
Inserto a granel
E para Excel:archivos CSV de muestra/conjuntos de datos para pruebas (hasta 1,5 millones de registros)
Descarga de Notepad++
Herramienta útil:
dbForge Data Pump:un complemento de SSMS para llenar bases de datos SQL con datos de fuentes externas y migrar datos entre sistemas.