Según Wikipedia, la inserción masiva es un proceso o método proporcionado por un sistema de gestión de base de datos para cargar varias filas de datos en una tabla de base de datos. Si ajustamos esta explicación a la instrucción BULK INSERT, la inserción masiva permite importar archivos de datos externos a SQL Server.
Supongamos que nuestra organización tiene un archivo CSV de 1.500.000 filas y queremos importarlo a una tabla en particular en SQL Server para usar la instrucción BULK INSERT en SQL Server. Podemos encontrar varios métodos para manejar esta tarea. Podría estar usando BCP (b ulk c opia p programa), el Asistente de importación y exportación de SQL Server o el paquete del Servicio de integración de SQL Server. Sin embargo, la instrucción BULK INSERT es mucho más rápida y potente. Otra ventaja es que ofrece varios parámetros que ayudan a determinar la configuración del proceso de inserción masiva.
Comencemos con una muestra básica. Luego pasaremos por escenarios más sofisticados.
Preparación
En primer lugar, necesitamos un archivo CSV de muestra. Descargamos un archivo CSV de muestra del sitio web E for Excel (una colección de archivos CSV de muestra con un número de fila diferente). Aquí vamos a utilizar 1.500.000 registros de ventas.
Descargue un archivo zip, descomprímalo para obtener un archivo CSV y colóquelo en su disco local.
Importar archivo CSV a la tabla de SQL Server
Importamos nuestro archivo CSV a la tabla de destino de la forma más simple. Coloqué mi archivo CSV de muestra en la unidad C:. Ahora creamos una tabla para importarle los datos del archivo CSV:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
La siguiente instrucción BULK INSERT importa el archivo CSV a la tabla Ventas:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Probablemente haya notado los parámetros específicos de la declaración de inserción masiva anterior. Vamos a aclararlos:
- PRIMERO especifica el punto de partida de la declaración de inserción. En el siguiente ejemplo, queremos omitir los encabezados de las columnas, por lo que establecemos este parámetro en 2.

- TERMINADOR DE CAMPO define el carácter que separa los campos entre sí. SQL Server detecta cada campo de esta manera.
- TERMINADOR DE FILA no difiere mucho de FIELDTERMINATOR. Define el carácter de separación de filas.
En el archivo CSV de muestra, FIELDTERMINATOR es muy claro y es una coma (,). Para detectar este parámetro, abra el archivo CSV en Notepad++ y vaya a Ver -> Mostrar símbolo -> Mostrar todas las cartas. Los caracteres CRLF se encuentran al final de cada campo.
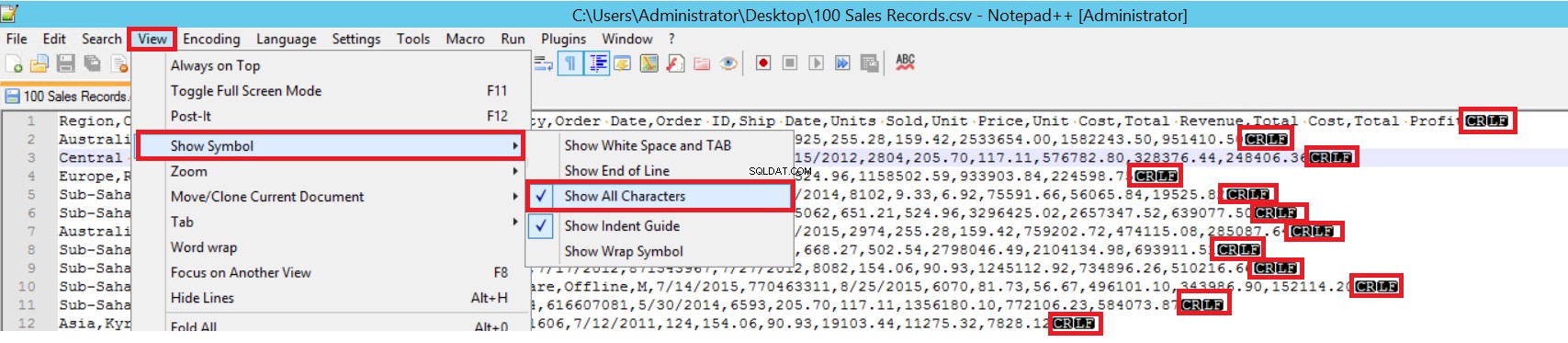
CR =Retorno de carro y LF =Avance de línea. Se utilizan para marcar un salto de línea en un archivo de texto. El indicador es "\n" en la declaración de inserción masiva.
Otra forma de importar un archivo CSV a una tabla con inserción masiva es mediante el parámetro FORMATO. Tenga en cuenta que este parámetro solo está disponible en SQL Server 2017 y versiones posteriores.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Ese fue el escenario más simple donde la tabla de destino y el archivo CSV tienen la misma cantidad de columnas. Sin embargo, el caso cuando la tabla de destino tiene más columnas, entonces el archivo CSV es típico. Considerémoslo.
Agregamos una clave principal a la tabla Ventas para romper las asignaciones de columnas de igualdad. Creamos la tabla Ventas con una clave principal e importamos el archivo CSV a través del comando de inserción masiva.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Pero produce un error:
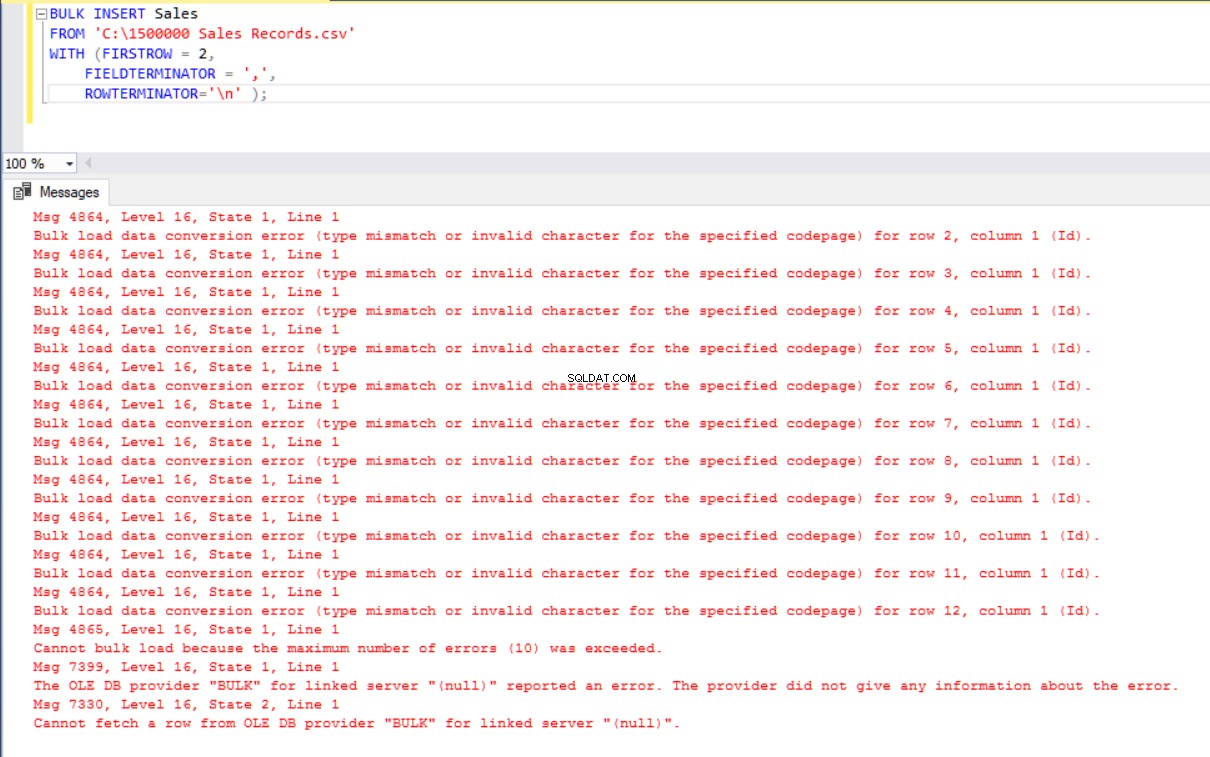
Para solucionar el error, creamos una vista de la tabla Ventas con columnas de asignación al archivo CSV. Luego importamos los datos CSV sobre esta vista a la tabla Ventas:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Separe y cargue un archivo CSV grande en un lote pequeño
SQL Server adquiere un bloqueo en la tabla de destino durante la operación de inserción masiva. De manera predeterminada, si no configura el parámetro BATTSIZE, SQL Server abre una transacción e inserta todos los datos CSV en ella. Con este parámetro, SQL Server divide los datos CSV según el valor del parámetro.
Dividamos todos los datos CSV en varios conjuntos de 300 000 filas cada uno.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Los datos se importarán cinco veces en partes.
- Si su declaración de inserción masiva no incluye el parámetro BATCHSIZE, se producirá un error y SQL Server revertirá todo el proceso de inserción masiva.
- Con este parámetro establecido en declaración de inserción masiva, SQL Server revierte solo la parte donde ocurrió el error.
No existe un valor óptimo o mejor para este parámetro porque su valor puede cambiar según los requisitos del sistema de su base de datos.
Establece el comportamiento en caso de errores
Si se produce un error en algunos escenarios de copia masiva, podemos cancelar el proceso de copia masiva o mantenerlo en marcha. El parámetro MAXERRORS nos permite especificar el número máximo de errores. Si el proceso de inserción masiva alcanza este valor de error máximo, cancela la operación de importación masiva y retrocede. El valor predeterminado para este parámetro es 10.
Por ejemplo, tenemos tipos de datos corruptos en 3 filas del archivo CSV. El parámetro MAXERRORS se establece en 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Toda la operación de inserción masiva se cancelará porque hay más errores que el valor del parámetro MAXERRORS.
Si cambiamos el parámetro MAXERRORS a 4, la declaración de inserción masiva omitirá estas filas con errores e insertará filas estructuradas de datos correctos. El proceso de inserción masiva estará completo.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Si usamos BATCHSIZE y MAXERRORS simultáneamente, el proceso de copia masiva no cancelará toda la operación de inserción. Solo cancelará la parte dividida.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
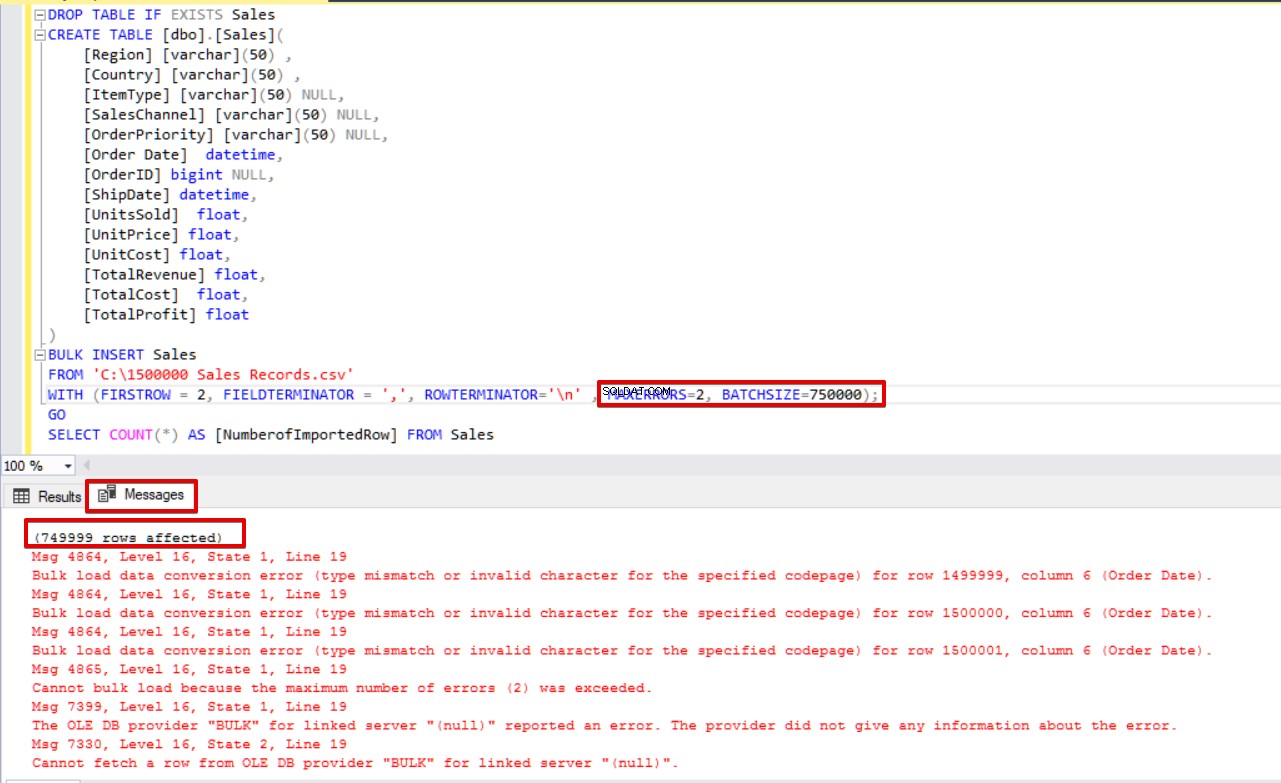
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Eche un vistazo a la imagen a continuación que muestra el resultado de la ejecución del script:
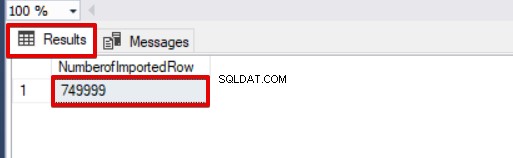
Otras opciones del proceso de inserción masiva
FIRE_TRIGGERS:habilita activadores en la tabla de destino durante la operación de inserción masiva
De forma predeterminada, durante el proceso de inserción masiva, los activadores de inserción especificados en la tabla de destino no se activan. Aún así, en algunas situaciones, es posible que queramos habilitarlos.
La solución es usar la opción FIRE_TRIGGERS en declaraciones de inserción masiva. Pero tenga en cuenta que puede afectar y disminuir el rendimiento de la operación de inserción masiva. Esto se debe a que el activador/activadores pueden realizar operaciones separadas en la base de datos.
Al principio, no configuramos el parámetro FIRE_TRIGGERS y el proceso de inserción masiva no activará el activador de inserción. Consulte el siguiente script T-SQL:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogCuando se ejecuta este script, el activador de inserción no se activará porque la opción FIRE_TRIGGERS no está configurada.
Ahora, agreguemos la opción FIRE_TRIGGERS a la declaración de inserción masiva:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 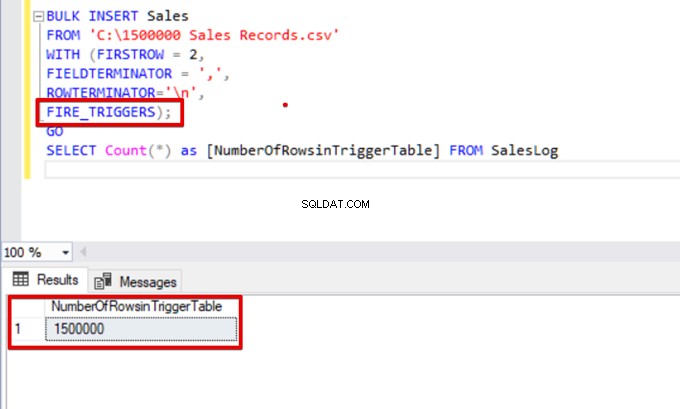
CHECK_CONSTRAINTS:habilite una restricción de verificación durante la operación de inserción masiva
Las restricciones de verificación nos permiten hacer cumplir la integridad de los datos en las tablas de SQL Server. El propósito de la restricción es verificar los valores insertados, actualizados o eliminados de acuerdo con su regulación de sintaxis. Por ejemplo, la restricción NOT NULL establece que el valor NULL no puede modificar una columna específica.
Aquí, nos centramos en las restricciones y las interacciones de inserción masiva. De forma predeterminada, durante el proceso de inserción masiva, se ignoran las restricciones de verificación y clave externa. Pero hay algunas excepciones.
Según Microsoft, “las restricciones de CLAVE PRIMARIA y ÚNICA siempre se aplican. Al importar a una columna de caracteres para la que se define la restricción NOT NULL, BULK INSERT inserta una cadena en blanco cuando no hay ningún valor en el archivo de texto.”
En el siguiente script T-SQL, agregamos una restricción de verificación a la columna OrderDate, que controla la fecha del pedido posterior al 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Como resultado, el proceso de inserción masiva omite el control de restricción de verificación. Sin embargo, SQL Server indica que la restricción de verificación no es de confianza:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'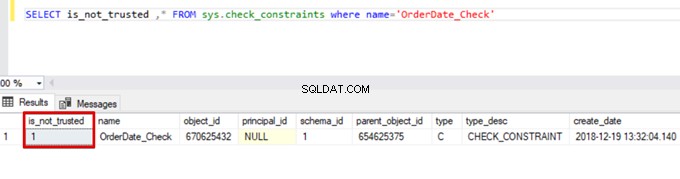
Este valor indica que alguien insertó o actualizó algunos datos en esta columna omitiendo la restricción de verificación. Al mismo tiempo, esta columna puede contener datos inconsistentes con respecto a esa restricción.
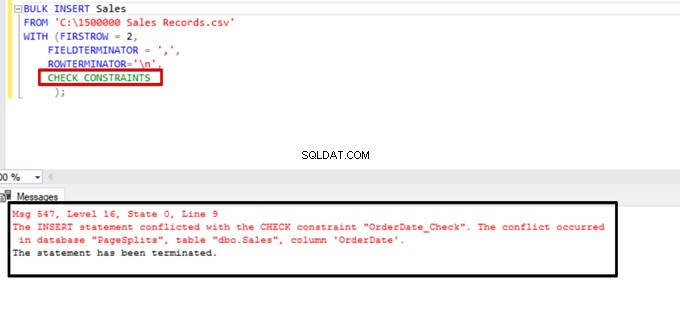
Intente ejecutar la declaración de inserción masiva con la opción CHECK_CONSTRAINTS. El resultado es sencillo:la restricción de verificación devuelve un error debido a datos incorrectos.
TABLOCK:aumente el rendimiento en múltiples inserciones masivas en una tabla de destino
El propósito principal del mecanismo de bloqueo en SQL Server es proteger y garantizar la integridad de los datos. En el Concepto principal del artículo de bloqueo de SQL Server, puede encontrar detalles sobre el mecanismo de bloqueo.
Nos centraremos en los detalles de bloqueo del proceso de inserción masiva.
Si ejecuta la declaración de inserción masiva sin la opción TABLELOCK, adquiere el bloqueo de filas o tablas según la jerarquía de bloqueo. Pero en algunos casos, es posible que queramos ejecutar varios procesos de inserción masiva en una tabla de destino y, por lo tanto, disminuir el tiempo de operación.
Primero, ejecutamos dos declaraciones de inserción masiva simultáneamente y analizamos el comportamiento del mecanismo de bloqueo. Abra dos ventanas de consulta en SQL Server Management Studio y ejecute las siguientes instrucciones de inserción masiva simultáneamente.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
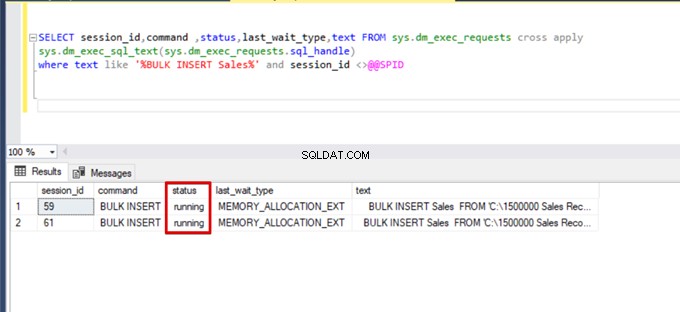
);Ejecute la siguiente consulta DMV (Vista de administración dinámica):ayuda a monitorear el estado del proceso de inserción masiva:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID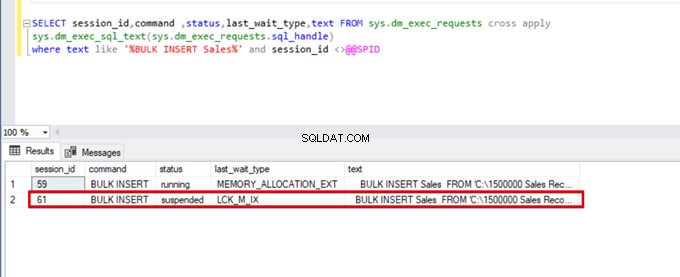
Como puede ver en la imagen de arriba, sesión 61, el estado del proceso de inserción masiva está suspendido debido a un bloqueo. Si verificamos el problema, la sesión 59 bloquea la tabla de destino de inserción masiva. Luego, la sesión 61 espera a que se libere este bloqueo para continuar con el proceso de inserción masiva.
Ahora, agregamos la opción TABLOCK a las declaraciones de inserción masiva y ejecutamos las consultas.
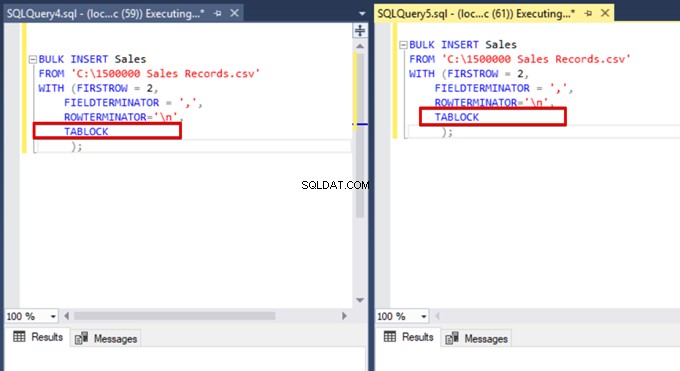
Cuando volvemos a ejecutar la consulta de supervisión del DMV, no podemos ver ningún proceso de inserción masiva suspendido porque SQL Server usa un tipo de bloqueo particular llamado bloqueo de actualización masiva (BU). Este tipo de bloqueo permite procesar múltiples operaciones de inserción masiva contra la misma tabla simultáneamente. Esta opción también reduce el tiempo total del proceso de inserción masiva.
Cuando ejecutamos la siguiente consulta durante el proceso de inserción masiva, podemos monitorear los detalles de bloqueo y los tipos de bloqueo:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()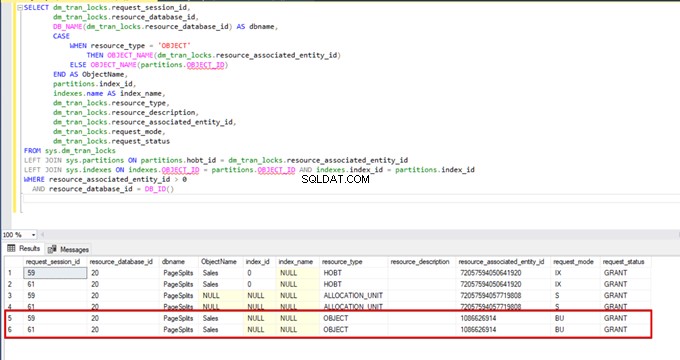
Conclusión
El artículo actual exploró todos los detalles de la operación de inserción masiva en SQL Server. En particular, mencionamos el comando BULK INSERT y sus configuraciones y opciones. Además, analizamos varios escenarios cercanos a problemas de la vida real.
Herramienta útil:
dbForge Data Pump:un complemento de SSMS para llenar bases de datos SQL con datos de fuentes externas y migrar datos entre sistemas.