Introducción
Este tutorial incluye información sobre SQL (DDL, DML) que he recopilado durante mi vida profesional. Esto es lo mínimo que necesita saber mientras trabaja con bases de datos. Si es necesario utilizar construcciones SQL complejas, generalmente navego por la biblioteca de MSDN, que se puede encontrar fácilmente en Internet. En mi opinión, es muy difícil mantener todo en la cabeza y, por cierto, no hay necesidad de ello. Le recomiendo que conozca todas las construcciones principales utilizadas en la mayoría de las bases de datos relacionales, como Oracle, MySQL y Firebird. Aún así, pueden diferir en los tipos de datos. Por ejemplo, para crear objetos (tablas, restricciones, índices, etc.), simplemente puede usar el entorno de desarrollo integrado (IDE) para trabajar con bases de datos y no es necesario estudiar herramientas visuales para un tipo de base de datos en particular (MS SQL, Oracle , MySQL, Firebird, etc.). Esto es conveniente porque puede ver el texto completo y no necesita mirar a través de numerosas pestañas para crear, por ejemplo, un índice o una restricción. Si está trabajando constantemente con bases de datos, crear, modificar y especialmente reconstruir un objeto usando scripts es mucho más rápido que en un modo visual. Además, en mi opinión, en el modo script (con la debida precisión), es más fácil especificar y controlar reglas para nombrar objetos. Además, es conveniente utilizar secuencias de comandos cuando necesite transferir cambios en la base de datos de una base de datos de prueba a una base de datos de producción.
SQL se divide en varias partes. En mi artículo, revisaré los más importantes:
DDL – Lenguaje de definición de datos
DML – Lenguaje de manipulación de datos, que incluye las siguientes construcciones:
- SELECT:selección de datos
- INSERT:inserción de nuevos datos
- ACTUALIZAR:actualización de datos
- ELIMINAR:eliminación de datos
- MERGE:fusión de datos
Explicaré todas las construcciones en casos de estudio. Además, creo que un lenguaje de programación, especialmente SQL, debe estudiarse en la práctica para una mejor comprensión.
Este es un tutorial paso a paso, donde necesita realizar ejemplos mientras lo lee. Sin embargo, si necesita conocer los comandos en detalle, navegue por Internet, por ejemplo, MSDN.
Al crear este tutorial, utilicé la base de datos de MS SQL Server, versión 2014 y MS SQL Server Management Studio (SSMS) para ejecutar scripts.
Brevemente sobre MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) es la utilidad de Microsoft SQL Server para configurar, gestionar y administrar los componentes de la base de datos. Incluye un editor de secuencias de comandos y un programa de gráficos que funciona con objetos y configuraciones del servidor. La herramienta principal de SQL Server Management Studio es Object Explorer, que permite al usuario ver, recuperar y administrar objetos del servidor. Este texto se ha tomado parcialmente de Wikipedia.
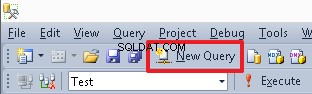
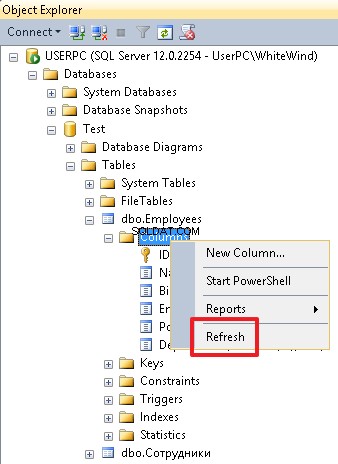
Para crear un nuevo editor de secuencias de comandos, use el botón Nueva consulta:
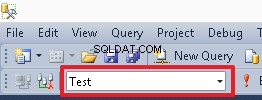
Para cambiar de la base de datos actual, puede usar el menú desplegable:
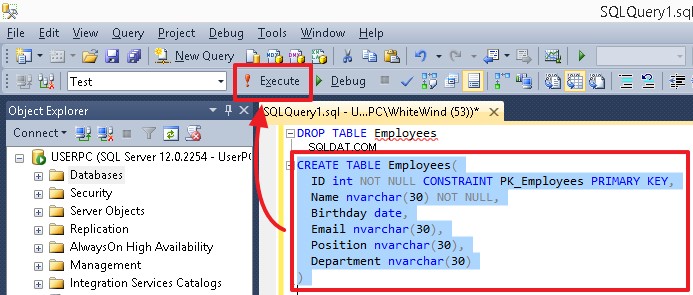
Para ejecutar un comando en particular o un conjunto de comandos, resáltelo y presione el botón Ejecutar o F5. Si solo hay un comando en el editor o si necesita ejecutar todos los comandos, no resalte nada.
Después de ejecutar secuencias de comandos que crean objetos (tablas, columnas, índices), seleccione el objeto correspondiente (por ejemplo, tablas o columnas) y luego haga clic en Actualizar en el menú contextual para ver los cambios.
En realidad, esto es todo lo que necesita saber para ejecutar los ejemplos proporcionados aquí.
Teoría
Una base de datos relacional es un conjunto de tablas vinculadas entre sí. En general, una base de datos es un archivo que almacena datos estructurados.
El Sistema de gestión de bases de datos (DBMS) es un conjunto de herramientas para trabajar con tipos de bases de datos particulares (MS SQL, Oracle, MySQL, Firebird, etc.).
Nota: Como en nuestra vida diaria, decimos "Oracle DB" o simplemente "Oracle" que en realidad significa "Oracle DBMS", luego en este tutorial usaré el término "base de datos".
Una tabla es un conjunto de columnas. Con mucha frecuencia, puede escuchar las siguientes definiciones de estos términos:campos, filas y registros, que significan lo mismo.
Una tabla es el objeto principal de la base de datos relacional. Todos los datos se almacenan fila por fila en las columnas de la tabla.
Para cada tabla, así como para sus columnas, debe especificar un nombre, según el cual puede encontrar un elemento requerido.
El nombre del objeto, la tabla, la columna y el índice pueden tener la longitud mínima:128 símbolos.
Nota: En las bases de datos de Oracle, el nombre de un objeto puede tener una longitud mínima de 30 símbolos. Por lo tanto, en una base de datos en particular, es necesario crear reglas personalizadas para los nombres de los objetos.
SQL es un lenguaje que permite ejecutar consultas en bases de datos a través de DBMS. En un DBMS particular, un lenguaje SQL puede tener su propio dialecto.
DDL y DML:el sublenguaje SQL:
- El lenguaje DDL sirve para crear y modificar la estructura de una base de datos (eliminación de tablas y enlaces);
- El lenguaje DML permite manipular datos de tablas, sus filas. También sirve para seleccionar datos de tablas, agregar nuevos datos, así como actualizar y eliminar datos actuales.
Es posible utilizar dos tipos de comentarios en SQL (de una sola línea y delimitados):
-- single-line comment
y
/* delimited comment */
Eso es todo en cuanto a la teoría.
DDL:lenguaje de definición de datos
Consideremos una tabla de muestra con datos sobre empleados representados de una manera familiar para una persona que no es programadora.
| ID de empleado | Nombre completo | Fecha de nacimiento | Correo electrónico | Puesto | Departamento |
| 1000 | Juan | 19.02.1955 | ejemplo@sqldat.com | CEO | Administración |
| 1001 | Daniel | 03.12.1983 | ejemplo@sqldat.com | programador | TI |
| 1002 | Mike | 07.06.1976 | ejemplo@sqldat.com | Contador | Departamento de cuentas |
| 1003 | Jordania | 17.04.1982 | ejemplo@sqldat.com | Programador sénior | TI |
En este caso, las columnas tienen los siguientes títulos:Identificación del empleado, Nombre completo, Fecha de nacimiento, Correo electrónico, Cargo y Departamento.
Podemos describir cada columna de esta tabla por su tipo de datos:
- ID de empleado:número entero
- Nombre completo:cadena
- Fecha de nacimiento – fecha
- Correo electrónico:cadena
- Posición:cadena
- Departamento – cadena
Un tipo de columna es una propiedad que especifica qué tipo de datos puede almacenar cada columna.
Para empezar, debe recordar los principales tipos de datos utilizados en MS SQL:
| Definición | Designación en | Descripción |
| Cadena de longitud variable | varchar(N) y nvarchar(N) | Usando el número N, podemos especificar la longitud de cadena máxima posible para una columna en particular. Por ejemplo, si queremos decir que el valor de la columna Nombre completo puede contener 30 símbolos (como máximo), entonces es necesario especificar el tipo de nvarchar(30).
La diferencia entre varchar y nvarchar es que varchar permite almacenar cadenas en formato ASCII, mientras que nvarchar almacena cadenas en formato Unicode, donde cada símbolo ocupa 2 bytes. |
| Cadena de longitud fija | char(N) y nchar(N) | Este tipo difiere de la cadena de longitud variable en lo siguiente:si la longitud de la cadena es menor que N símbolos, siempre se agregan espacios a la longitud N a la derecha. Por lo tanto, en una base de datos, toma exactamente N símbolos, donde un símbolo toma 1 byte para char y 2 bytes para nchar. En mi práctica, este tipo no se usa mucho. Aún así, si alguien lo usa, generalmente este tipo tiene el formato char(1), es decir, cuando un campo está definido por 1 símbolo. |
| Entero | int | Este tipo nos permite usar solo números enteros (tanto positivos como negativos) en una columna. Nota:un rango de números para este tipo es el siguiente:de 2 147 483 648 a 2 147 483 647. Por lo general, es el tipo principal que se usa para identificar identificadores. |
| Número de punto flotante | flotante | Números con punto decimal. |
| Fecha | fecha | Se utiliza para almacenar solo una fecha (fecha, mes y año) en una columna. Por ejemplo, 15/02/2014. Este tipo se puede usar para las siguientes columnas:fecha de recibo, fecha de nacimiento, etc., cuando necesita especificar solo una fecha o cuando la hora no es importante para nosotros y podemos eliminarla. |
| Tiempo | tiempo | Puede usar este tipo si es necesario almacenar tiempo:horas, minutos, segundos y milisegundos. Por ejemplo, tiene 17:38:31.3231603 o necesita agregar la hora de salida del vuelo. |
| Fecha y hora | fechahora | Este tipo permite a los usuarios almacenar tanto la fecha como la hora. Por ejemplo, tiene el evento el 15/02/2014 17:38:31.323. |
| Indicador | bit | Puede usar este tipo para almacenar valores como 'Sí'/'No', donde 'Sí' es 1 y 'No' es 0. |
Además, no es necesario especificar el valor del campo, a menos que esté prohibido. En este caso, puede usar NULL.
Para ejecutar ejemplos, crearemos una base de datos de prueba llamada 'Prueba'.
Para crear una base de datos simple sin propiedades adicionales, ejecute el siguiente comando:
CREATE DATABASE Test
Para eliminar una base de datos, ejecute este comando:
DROP DATABASE Test
Para cambiar a nuestra base de datos, use el comando:
USE Test
Como alternativa, puede seleccionar la base de datos de prueba del menú desplegable en el área de menú de SSMS.
Ahora, podemos crear una tabla en nuestra base de datos utilizando descripciones, espacios y símbolos cirílicos:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
En este caso, necesitamos envolver los nombres entre corchetes […].
Aún así, es mejor especificar todos los nombres de objetos en latín y no usar espacios en los nombres. En este caso, cada palabra comienza con una letra mayúscula. Por ejemplo, para el campo “EmployeeID”, podríamos especificar el nombre PersonnelNumber. También puede usar números en el nombre, por ejemplo, PhoneNumber1.
Nota: En algunos DBMS, es más conveniente utilizar el siguiente formato de nombre «PHONE_NUMBER». Por ejemplo, puede ver este formato en las bases de datos ORACLE. Además, el nombre del campo no debe coincidir con las palabras clave utilizadas en DBMS.
Por esta razón, puede olvidarse de la sintaxis de los corchetes y puede eliminar la tabla Empleados:
DROP TABLE [Employees]
Por ejemplo, puede nombrar la tabla con empleados como "Empleados" y establecer los siguientes nombres para sus campos:
- Identificación
- Nombre
- Cumpleaños
- Correo electrónico
- Posición
- Departamento
Muy a menudo, usamos 'ID' para el campo de identificador.
Ahora, creemos una tabla:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Para establecer las columnas obligatorias, puede utilizar la opción NOT NULL.
Para la tabla actual, puede redefinir los campos usando los siguientes comandos:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Nota: El concepto general del lenguaje SQL para la mayoría de los DBMS es el mismo (desde mi propia experiencia). La diferencia entre los DDL en diferentes DBMS está principalmente en los tipos de datos (pueden diferir no solo por sus nombres sino también por su implementación específica). Además, la implementación específica de SQL (comandos) es la misma, pero puede haber ligeras diferencias en el dialecto. Al conocer los conceptos básicos de SQL, puede cambiar fácilmente de un DBMS a otro. En este caso, solo necesitará comprender los detalles de la implementación de comandos en un nuevo DBMS.
Compare los mismos comandos en ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE difiere en la implementación del tipo varchar2. Su formato depende de la configuración de la base de datos y puede guardar un texto, por ejemplo, en UTF-8. Además, puede especificar la longitud del campo tanto en bytes como en símbolos. Para hacer esto, debe usar los valores BYTE y CHAR seguidos del campo de longitud. Por ejemplo:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
El valor (BYTE o CHAR) que se utilizará de forma predeterminada cuando simplemente indique varchar2(30) en ORACLE dependerá de la configuración de la base de datos. A menudo, puede confundirse fácilmente. Por lo tanto, recomiendo especificar explícitamente CHAR cuando use el tipo varchar2 (por ejemplo, con UTF-8) en ORACLE (ya que es más conveniente leer la longitud de la cadena en símbolos).
Sin embargo, en este caso, si hay datos en la tabla, entonces para ejecutar correctamente los comandos, es necesario completar los campos ID y Nombre en todas las filas de la tabla.
Lo mostraré en un ejemplo particular.
Insertemos datos en los campos ID, Posición y Departamento usando el siguiente script:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
En este caso, el comando INSERT también devuelve un error. Esto sucede porque no hemos especificado el valor del campo obligatorio Nombre.
Si hubiera algunos datos en la tabla original, entonces el comando "ALTER TABLE Employees ALTER COLUMN ID int NOT NULL" funcionaría, mientras que el comando "ALTER TABLE Employees ALTER COLUMN Name int NOT NULL" devolvería un error de que el campo Nombre tiene Valores NULOS.
Agreguemos valores en el campo Nombre:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Además, puede usar NOT NULL al crear una nueva tabla con la instrucción CREATE TABLE.
Primero, eliminemos una tabla:
DROP TABLE Employees
Ahora, vamos a crear una tabla con los campos obligatorios ID y Nombre:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Además, puede especificar NULL después de un nombre de columna, lo que implica que se permiten valores NULL. Esto no es obligatorio, ya que esta opción está configurada por defecto.
Si necesita hacer que la columna actual no sea obligatoria, use la siguiente sintaxis:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Alternativamente, puede usar este comando:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Además, con este comando podemos modificar el tipo de campo a otro compatible o cambiar su longitud. Por ejemplo, ampliemos el campo Nombre a 50 símbolos:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Clave principal
Al crear una tabla, debe especificar una columna o un conjunto de columnas exclusivo para cada fila. Usando este valor único, puede identificar un registro. Este valor se denomina clave principal. La columna ID (que contiene el «número personal de un empleado»; en nuestro caso, este es el valor único para cada empleado y no se puede duplicar) puede ser la clave principal para nuestra tabla de Empleados.
Puede usar el siguiente comando para crear una clave principal para la tabla:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
'PK_Employees' es un nombre de restricción que define la clave principal. Por lo general, el nombre de una clave principal consiste en el prefijo 'PK_' y el nombre de la tabla.
Si la clave principal contiene varios campos, debe enumerar estos campos entre paréntesis separados por una coma:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Tenga en cuenta que en MS SQL, todos los campos de la clave principal NO deben ser NULOS.
Además, puede definir una clave principal al crear una tabla. Borremos la tabla:
DROP TABLE Employees
Luego, crea una tabla usando la siguiente sintaxis:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Añadir datos a la tabla:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
En realidad, no necesita especificar el nombre de la restricción. En este caso, se le asignará un nombre de sistema. Por ejemplo, «PK__Empleado__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
o
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Personalmente, recomendaría especificar explícitamente el nombre de la restricción para las tablas permanentes, ya que es más fácil trabajar o eliminar un valor claro y definido explícitamente en el futuro. Por ejemplo:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Aún así, es más cómodo aplicar esta sintaxis corta, sin nombres de restricciones al crear tablas de bases de datos temporales (el nombre de una tabla temporal comienza con # o ##.
Resumen:
Ya hemos analizado los siguientes comandos:
- CREAR TABLA table_name (lista de campos y sus tipos, así como restricciones) – sirve para crear una nueva tabla en la base de datos actual;
- TABLA DE DESCENSO table_name:sirve para eliminar una tabla de la base de datos actual;
- TABLA ALTERADA table_name ALTERAR COLUMNA column_name … – sirve para actualizar el tipo de columna o para modificar su configuración (por ejemplo, cuando necesita establecer NULL o NOT NULL);
- TABLA ALTERADA table_name AÑADIR RESTRICCIÓN restricción_nombre CLAVE PRINCIPAL (field1, field2,…) – usado para agregar una clave principal a la tabla actual;
- TABLA ALTERADA table_name RESTRICCIÓN DE CAÍDA constreñir_nombre:se utiliza para eliminar una restricción de la tabla.
Mesas temporales
Resumen de MSDN. Hay dos tipos de tablas temporales en MS SQL Server:locales (#) y globales (##). Las tablas temporales locales solo son visibles para sus creadores antes de que se desconecte la instancia de SQL Server. Se eliminan automáticamente después de que el usuario se desconecta de la instancia de SQL Server. Las tablas temporales globales son visibles para todos los usuarios durante cualquier sesión de conexión después de crear estas tablas. Estas tablas se eliminan una vez que los usuarios se desconectan de la instancia de SQL Server.
Las tablas temporales se crean en la base de datos del sistema tempdb, lo que significa que no inundamos la base de datos principal. Además, puede eliminarlos con el comando DROP TABLE. Muy a menudo, se utilizan tablas temporales locales (#).
Para crear una tabla temporal, puede usar el comando CREAR TABLA:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
Puede eliminar la tabla temporal con el comando DROP TABLE:
DROP TABLE #Temp
Además, puede crear una tabla temporal y completarla con los datos utilizando la sintaxis SELECT... INTO:
SELECT ID,Name INTO #Temp FROM Employees
Nota: En diferentes DBMS, la implementación de bases de datos temporales puede variar. Por ejemplo, en los DBMS de ORACLE y Firebird, la estructura de las tablas temporales debe definirse de antemano mediante el comando CREATE GLOBAL TEMPORARY TABLE. Además, debe especificar la forma de almacenar los datos. Después de esto, un usuario lo ve entre tablas comunes y trabaja con él como con una tabla convencional.
Normalización de bases de datos:división en subtablas (tablas de referencia) y definición de relaciones entre tablas
Nuestra tabla Empleados actual tiene un inconveniente:un usuario puede escribir cualquier texto en los campos Cargo y Departamento, lo que puede generar errores, ya que para un empleado puede especificar "TI" como departamento, mientras que para otro empleado puede especificar "TI". Departamento". Como resultado, no quedará claro qué quiso decir el usuario, si estos empleados trabajan para el mismo departamento o si hay un error ortográfico y hay 2 departamentos diferentes. Además, en este caso, no podremos agrupar correctamente los datos para un informe, donde necesitamos mostrar la cantidad de empleados para cada departamento.
Otro inconveniente es el volumen de almacenamiento y su duplicación, es decir, debe especificar un nombre completo del departamento para cada empleado, lo que requiere espacio en las bases de datos para almacenar cada símbolo del nombre del departamento.
La tercera desventaja es la complejidad de actualizar los datos de campo cuando necesita modificar el nombre de cualquier puesto, desde programador hasta programador junior. En este caso, deberá agregar nuevos datos en cada fila de la tabla donde la Posición sea "Programador".
Para evitar tales situaciones, se recomienda utilizar la normalización de la base de datos, división en subtablas, tablas de referencia.
Vamos a crear 2 tablas de referencia “Puestos” y “Departamentos”:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Tenga en cuenta que aquí hemos utilizado una nueva propiedad IDENTIDAD. Significa que los datos en la columna ID se listarán automáticamente comenzando con 1. Así, al agregar nuevos registros, los valores 1, 2, 3, etc. se asignarán secuencialmente. Por lo general, estos campos se denominan campos de incremento automático. Solo se puede definir un campo con la propiedad IDENTITY como clave principal en una tabla. Por lo general, pero no siempre, dicho campo es la clave principal de la tabla.
Nota: En diferentes DBMS, la implementación de campos con un incrementador puede diferir. En MySQL, por ejemplo, dicho campo está definido por la propiedad AUTO_INCREMENT. En ORACLE y Firebird, podría emular esta funcionalidad por secuencias (SECUENCIA). Pero que yo sepa, la propiedad GENERADO COMO IDENTIDAD se ha agregado en ORACLE.
Completemos estas tablas automáticamente en función de los datos actuales en los campos Cargo y Departamento de la tabla Empleados:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
Debe realizar los mismos pasos para la tabla Departamentos:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Ahora, si abrimos las tablas de Posiciones y Departamentos, veremos una lista numerada de valores en el campo ID:
SELECT * FROM Positions
| ID | Nombre |
| 1 | Contador |
| 2 | CEO |
| 3 | Programador |
| 4 | Programador sénior |
SELECT * FROM Departments
| ID | Nombre |
| 1 | Administración |
| 2 | Departamento de cuentas |
| 3 | TI |
Estas tablas serán las tablas de referencia para definir puestos y departamentos. Ahora, nos referiremos a los identificadores de puestos y departamentos. En primer lugar, vamos a crear nuevos campos en la tabla Empleados para almacenar los identificadores:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
El tipo de campos de referencia debe ser el mismo que en las tablas de referencia, en este caso es int.
Además, puede agregar varios campos usando un comando enumerando los campos separados por comas:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Ahora, agregaremos restricciones de referencia (CLAVE EXTERNA) a estos campos, para que un usuario no pueda agregar valores que no sean los valores de ID de las tablas de referencia.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Se deben realizar los mismos pasos para el segundo campo:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Ahora, los usuarios solo pueden insertar en estos campos los valores de identificación de la tabla de referencia correspondiente. Así, para utilizar un nuevo departamento o puesto, un usuario debe agregar un nuevo registro en la tabla de referencia correspondiente. Como los puestos y departamentos se almacenan en tablas de referencia en una sola copia, para cambiar su nombre, debe cambiarlo solo en la tabla de referencia.
El nombre de una restricción de referencia suele ser compuesto. Consta del prefijo «FK» seguido de un nombre de tabla y un nombre de campo que hace referencia al identificador de la tabla de referencia.
El identificador (ID) suele ser un valor interno utilizado solo para enlaces. No importa el valor que tenga. Por lo tanto, no intente deshacerse de las lagunas en la secuencia de valores que aparecen cuando trabaja con la tabla, por ejemplo, cuando elimina registros de la tabla de referencia.
En algunos casos, es posible construir una referencia a partir de varios campos:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
En este caso, una clave primaria está representada por un conjunto de varios campos (field1, field2, …) en la tabla “reference_table”.
Ahora, actualicemos los campos PositionID y DepartmentID con los valores de ID de las tablas de referencia.
Para ello, utilizaremos el comando ACTUALIZAR:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Ejecute la siguiente consulta:
SELECT * FROM Employees
| ID | Nombre | Cumpleaños | Correo electrónico | Posición | Departamento | Id. de posición | ID de departamento |
| 1000 | Juan | NULO | NULO | CEO | Administración | 2 | 1 |
| 1001 | Daniel | NULO | NULO | Programador | TI | 3 | 3 |
| 1002 | Mike | NULO | NULO | Contador | Departamento de cuentas | 1 | 2 |
| 1003 | Jordania | NULO | NULO | Programador sénior | TI | 4 | 3 |
Como puede ver, los campos PositionID y DepartmentID coinciden con puestos y departamentos. Por lo tanto, puede eliminar los campos Cargo y Departamento en la tabla Empleados ejecutando el siguiente comando:
ALTER TABLE Employees DROP COLUMN Position,Department
Ahora, ejecute esta instrucción:
SELECT * FROM Employees
| ID | Nombre | Cumpleaños | Correo electrónico | Id. de posición | ID de departamento |
| 1000 | Juan | NULO | NULO | 2 | 1 |
| 1001 | Daniel | NULO | NULO | 3 | 3 |
| 1002 | Mike | NULO | NULO | 1 | 2 |
| 1003 | Jordania | NULO | NULO | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
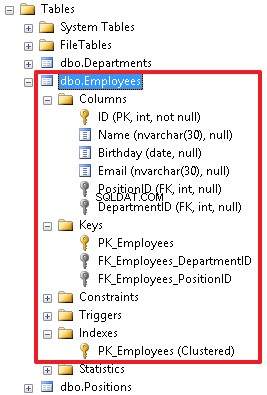
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
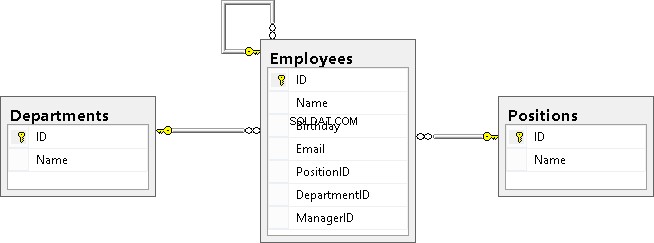
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
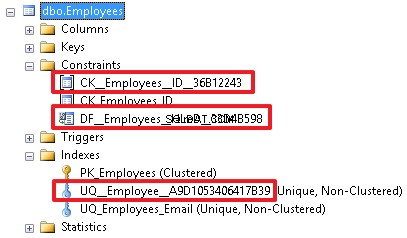
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Summary
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.