¿Aún conserva el diseño principal/secundario o le gustaría probar algo nuevo, como el ID de jerarquía de SQL Server? Bueno, es realmente nuevo porque el ID de jerarquía ha sido parte de SQL Server desde 2008. Por supuesto, la novedad en sí no es un argumento convincente. Pero tenga en cuenta que Microsoft agregó esta característica para representar mejor las relaciones de uno a muchos con múltiples niveles.
Tal vez se pregunte qué diferencia hace y qué beneficios obtiene al usar el ID de jerarquía en lugar de las relaciones padre/hijo habituales. Si nunca exploraste esta opción, puede que te sorprenda.
La verdad es que no exploré esta opción desde que se lanzó. Sin embargo, cuando finalmente lo hice, me pareció una gran innovación. Es un código más atractivo, pero contiene mucho más. En este artículo vamos a conocer todas esas excelentes oportunidades.
Sin embargo, antes de sumergirnos en las peculiaridades del uso de la jerarquía ID de SQL Server, aclaremos su significado y alcance.
¿Qué es el ID de jerarquía de SQL Server?
El ID de jerarquía de SQL Server es un tipo de datos integrado diseñado para representar árboles, que son el tipo más común de datos jerárquicos. Cada elemento de un árbol se denomina nodo. En formato de tabla, es una fila con una columna de tipo de datos de ID de jerarquía.
Por lo general, demostramos jerarquías usando un diseño de tabla. Una columna de ID representa un nodo y otra columna representa el padre. Con el ID de jerarquía de SQL Server, solo necesitamos una columna con un tipo de datos de ID de jerarquía.
Cuando consulta una tabla con una columna de ID de jerarquía, ve valores hexadecimales. Es una de las imágenes visuales de un nodo. Otra forma es una cadena:
'/' representa el nodo raíz;
'/1/', '/2/', '/3/' o '/n/' representan a los hijos - descendientes directos 1 a n;
‘/1/1/’ o ‘/1/2/’ son los “hijos de niños – “nietos”. La cadena como ‘/1/2/’ significa que el primer hijo de la raíz tiene dos hijos, que son, a su vez, dos nietos de la raíz.
Aquí hay una muestra de cómo se ve:
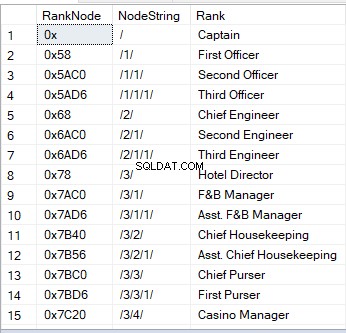
A diferencia de otros tipos de datos, las columnas de ID de jerarquía pueden aprovechar los métodos integrados. Por ejemplo, si tiene una columna de ID de jerarquía denominada RankNode , puede tener la siguiente sintaxis:
RankNode.
Métodos de ID de jerarquía de SQL Server
Uno de los métodos disponibles es IsDescendantOf . Devuelve 1 si el nodo actual es descendiente de un valor de ID de jerarquía.
Puede escribir código con este método similar al siguiente:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Otros métodos utilizados con el ID de jerarquía son los siguientes:
- GetRoot:el método estático que devuelve la raíz del árbol.
- GetDescendant:devuelve un nodo secundario de un padre.
- GetAncestor:devuelve un ID de jerarquía que representa el enésimo antepasado de un nodo dado.
- GetLevel:devuelve un número entero que representa la profundidad del nodo.
- ToString:devuelve la cadena con la representación lógica de un nodo. ToString se llama implícitamente cuando se produce la conversión del ID de jerarquía al tipo de cadena.
- GetReparentedValue:mueve un nodo del padre antiguo al padre nuevo.
- Parse:actúa como lo contrario de ToString . Convierte la vista de cadena de un hierarchyID valor a hexadecimal.
Estrategias de indexación de SQL Server HierarchyID
Para asegurarse de que las consultas de tablas que utilizan el ID de jerarquía se ejecuten lo más rápido posible, debe indexar la columna. Existen dos estrategias de indexación:
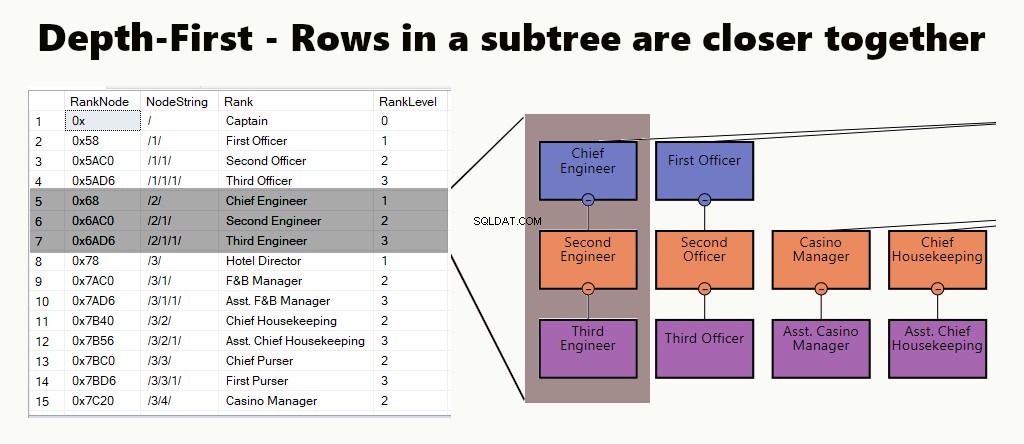
PRIMERO EN PROFUNDIDAD
En un índice primero en profundidad, las filas del subárbol están más cerca unas de otras. Se adapta a consultas como encontrar un departamento, sus subunidades y empleados. Otro ejemplo es un gerente y sus empleados almacenados más juntos.
En una tabla, puede implementar un índice primero en profundidad creando un índice agrupado para los nodos. Además, realizamos uno de nuestros ejemplos, así.
LA AMPLIA PRIMERO
En un índice de amplitud, las filas del mismo nivel están más juntas. Se adapta a consultas como encontrar todos los empleados que reportan directamente al gerente. Si la mayoría de las consultas son similares a esta, cree un índice agrupado basado en (1) nivel y (2) nodo.
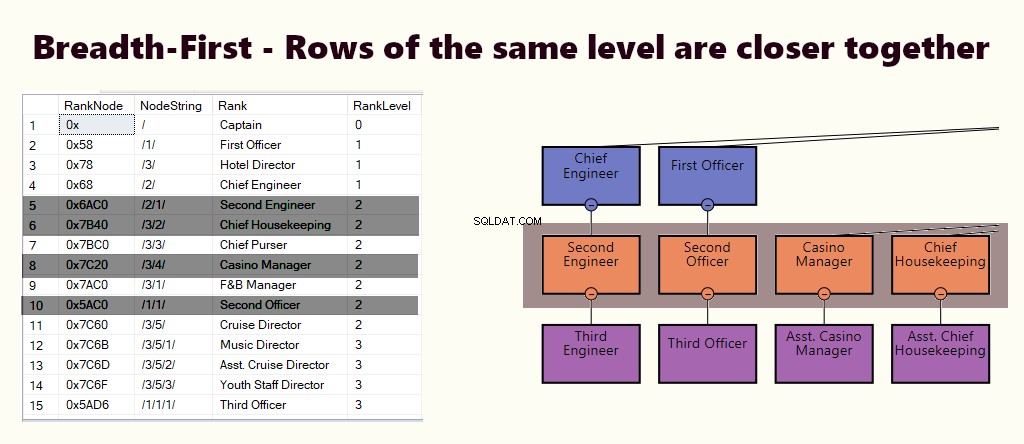
Depende de sus requisitos si necesita un índice primero en profundidad, primero en amplitud o ambos. Debe equilibrar la importancia del tipo de consultas y las instrucciones DML que ejecuta en la tabla.
Limitaciones de ID de jerarquía de SQL Server
Desafortunadamente, usar el ID de jerarquía no puede resolver todos los problemas:
- SQL Server no puede adivinar qué es el hijo de un padre. Tienes que definir el árbol en la tabla.
- Si no usa una restricción única, el valor de ID de jerarquía generado no será único. Manejar este problema es responsabilidad del desarrollador.
- Las relaciones de un nodo primario y secundario no se aplican como una relación de clave externa. Por lo tanto, antes de eliminar un nodo, consulte los descendientes existentes.
Visualización de jerarquías
Antes de continuar, considere una pregunta más. Mirando el conjunto de resultados con cadenas de nodos, ¿le resulta difícil visualizar la jerarquía?
Para mí, es un gran sí porque no me estoy haciendo más joven.
Por esta razón, vamos a utilizar Power BI y Hierarchy Chart de Akvelon junto con nuestras tablas de base de datos. Ayudarán a mostrar la jerarquía en un organigrama. Espero que facilite el trabajo.
Ahora, pongámonos manos a la obra.
Usos de SQL Server HierarchyID
Puede usar HierarchyID con los siguientes escenarios comerciales:
- Estructura organizativa
- Carpetas, subcarpetas y archivos
- Tareas y subtareas en un proyecto
- Páginas y subpáginas de un sitio web
- Datos geográficos con países, regiones y ciudades
Incluso si su escenario empresarial es similar al anterior y rara vez realiza consultas en las secciones de la jerarquía, no necesita el ID de jerarquía.
Por ejemplo, su organización procesa las nóminas de los empleados. ¿Necesita acceder al subárbol para procesar la nómina de alguien? De nada. Sin embargo, si procesa comisiones de personas en un sistema de marketing multinivel, puede ser diferente.
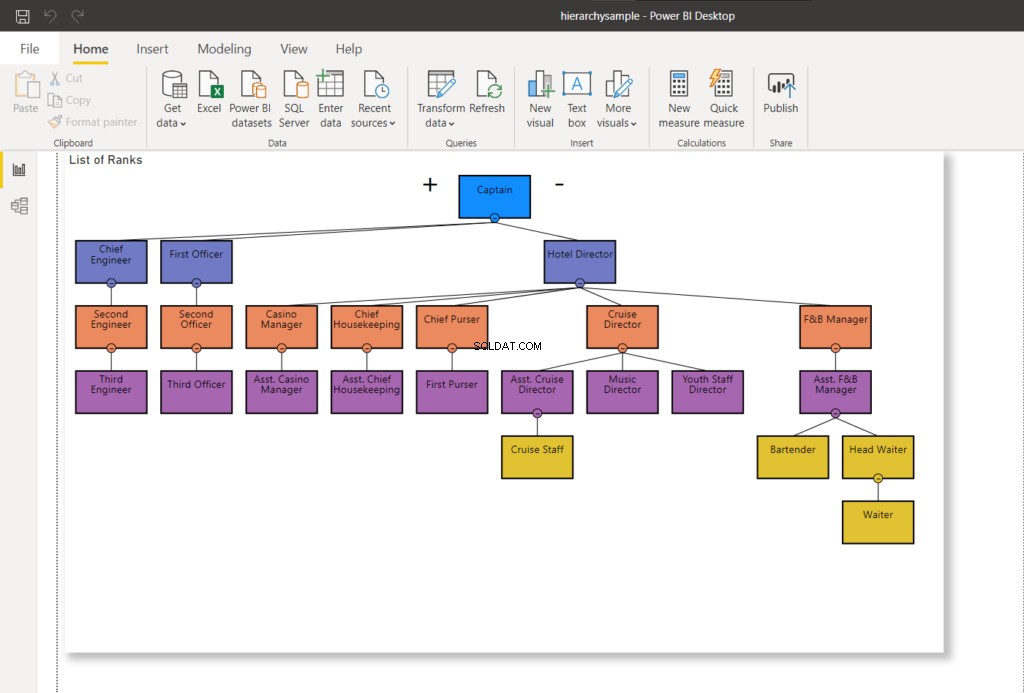
En esta publicación, usamos la parte de la estructura organizacional y la cadena de mando en un crucero. La estructura fue adaptada del organigrama de aquí. Mírelo en la Figura 4 a continuación:

Ahora puede visualizar la jerarquía en cuestión. Usamos las siguientes tablas a lo largo de esta publicación:
- Embarcaciones – es la tabla que representa la lista de cruceros.
- Clasificaciones – es la tabla de rangos de la tripulación. Allí establecemos jerarquías utilizando el ID de jerarquía.
- Tripulación – es la lista de la tripulación de cada embarcación y sus rangos.
La estructura de la tabla de cada caso es la siguiente:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOInserción de datos de tabla con SQL Server HierarchyID
La primera tarea al usar el ID de jerarquía a fondo es agregar registros a la tabla con un ID de jerarquía columna. Hay dos formas de hacerlo.
Uso de cadenas
La forma más rápida de insertar datos con el ID de jerarquía es usar cadenas. Para ver esto en acción, agreguemos algunos registros a los Clasificaciones mesa.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)El código anterior agrega 20 registros a la tabla de rangos.
Como puede ver, la estructura de árbol se ha definido en el INSERTAR declaración anterior. Es discernible fácilmente cuando usamos cadenas. Además, SQL Server lo convierte a los valores hexadecimales correspondientes.
Uso de Max(), GetAncestor() y GetDescendant()
El uso de cadenas se adapta a la tarea de completar los datos iniciales. A la larga, necesita el código para manejar la inserción sin proporcionar cadenas.
Para realizar esta tarea, obtenga el último nodo utilizado por un padre o antepasado. Lo logramos usando las funciones MAX() y GetAncestor() . Vea el código de muestra a continuación:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())A continuación se muestran los puntos tomados del código anterior:
- Primero, necesita una variable para el último nodo y el superior inmediato.
- El último nodo se puede adquirir usando MAX() contra RankNode para el padre especificado o superior inmediato. En nuestro caso, es el Subgerente de F&B con un valor de nodo de 0x7AD6.
- A continuación, para asegurarse de que no aparezca ningún elemento secundario duplicado, use @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . El valor en @MaxNode es el ultimo hijo. Si no es NULL , ObtenerDescendiente() devuelve el siguiente valor de nodo posible.
- Último, ObtenerNivel() devuelve el nivel del nuevo nodo creado.
Consulta de datos
Después de agregar registros a nuestra tabla, es hora de consultarla. Hay 2 formas de consultar datos disponibles:
La consulta de descendientes directos
Cuando buscamos a los empleados que reportan directamente al gerente, necesitamos saber dos cosas:
- El valor del nodo del administrador o principal
- El nivel del empleado bajo el gerente
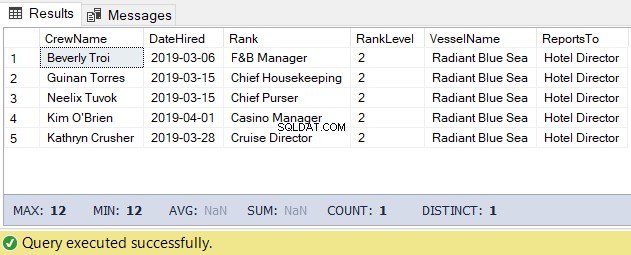
Para esta tarea, podemos usar el siguiente código. El resultado es la lista de la tripulación bajo el Director del Hotel.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorEl resultado del código anterior es el siguiente en la Figura 5:
Consulta de subárboles
A veces, también es necesario enumerar los hijos y los hijos de los hijos hasta el final. Para hacer esto, debe tener el ID de jerarquía del padre.
La consulta será similar al código anterior pero sin necesidad de subir el nivel. Vea el ejemplo de código:
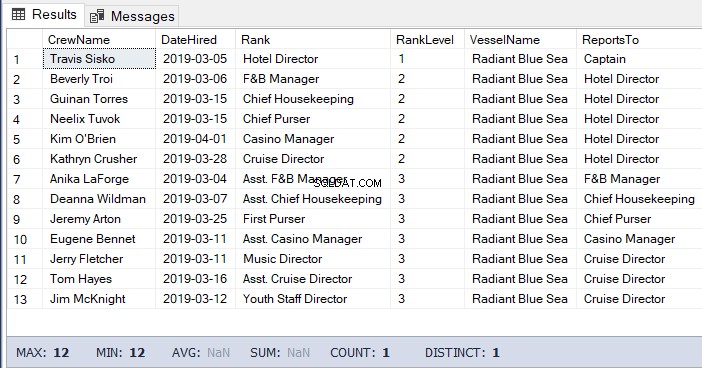
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1El resultado del código anterior:
Mover nodos con SQL Server HierarchyID
Otra operación estándar con datos jerárquicos es mover un hijo o un subárbol completo a otro padre. Sin embargo, antes de continuar, tenga en cuenta un posible problema:
Problema potencial
- Primero, los nodos móviles implican E/S. La frecuencia con la que mueva los nodos puede ser el factor decisivo si usa el ID de jerarquía o el padre/hijo habitual.
- En segundo lugar, mover un nodo en un diseño principal/secundario actualiza una fila. Al mismo tiempo, cuando mueve un nodo con ID de jerarquía, actualiza una o más filas. El número de filas afectadas depende de la profundidad del nivel de jerarquía. Puede convertirse en un problema de rendimiento importante.
Solución
Puede manejar este problema con el diseño de su base de datos.
Consideremos el diseño que usamos aquí.
En lugar de definir la jerarquía en el equipo tabla, lo definimos en los Rangos mesa. Este enfoque difiere del Empleado tabla en AdventureWorks base de datos de muestra, y ofrece las siguientes ventajas:
- Los miembros de la tripulación se mueven con más frecuencia que los rangos en un barco. Este diseño reducirá los movimientos de los nodos en la jerarquía. Como resultado, minimiza el problema definido anteriormente.
- Definir más de una jerarquía en el Equipo El cuadro es más complicado, ya que dos barcos necesitan dos capitanes. El resultado son dos nodos raíz.
- Si necesita mostrar todos los rangos con el miembro de la tripulación correspondiente, puede usar LEFT JOIN. Si no hay nadie a bordo para ese rango, muestra un espacio vacío para el puesto.
Ahora, pasemos al objetivo de esta sección. Agregue nodos secundarios bajo los padres incorrectos.
Para visualizar lo que estamos a punto de hacer, imagina una jerarquía como la siguiente. Tenga en cuenta los nodos amarillos.

Mover un nodo sin hijos
Mover un nodo secundario requiere lo siguiente:
- Defina el ID de jerarquía del nodo secundario para mover.
- Defina el ID de jerarquía del padre anterior.
- Defina el ID de jerarquía del nuevo padre.
- Usar ACTUALIZAR con GetReparentedValue() para mover el nodo físicamente.
Comience moviendo un nodo sin hijos. En el siguiente ejemplo, movemos el Personal de Crucero de debajo del Director de Crucero a debajo del Asistente. Director de crucero.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveUna vez que se actualiza el nodo, se utilizará un nuevo valor hexadecimal para el nodo. Actualizar mi conexión de Power BI a SQL Server:cambiará el gráfico de jerarquía como se muestra a continuación:
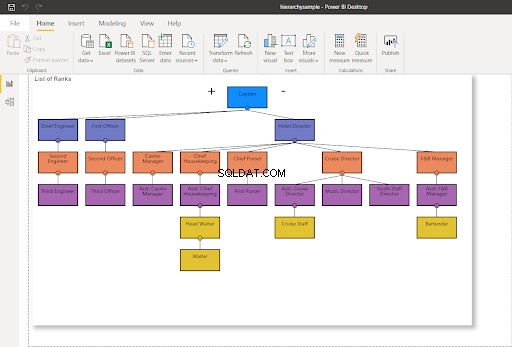
En la Figura 8, el personal de cruceros ya no informa al Director de cruceros; se cambia para informar al Asistente del director de cruceros. Compárelo con la Figura 7 anterior.
Ahora, pasemos a la siguiente etapa y pasemos al jefe de camareros al asistente del gerente de F&B.
Mover un nodo con hijos
Hay un desafío en esta parte.
La cuestión es que el código anterior no funcionará con un nodo con un solo hijo. Recordamos que mover un nodo requiere actualizar uno o más nodos hijos.
Además, no termina ahí. Si el nuevo padre tiene un hijo existente, es posible que nos encontremos con valores de nodo duplicados.
En este ejemplo, tenemos que enfrentar ese problema:el Asst. F&B Manager tiene un nodo secundario Bartender.
¿Listo? Aquí está el código:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;En el ejemplo de código anterior, la iteración comienza como la necesidad de transferir el nodo al hijo en el último nivel.
Después de ejecutarlo, los Ranks la tabla se actualizará. Y nuevamente, si desea ver los cambios visualmente, actualice el informe de Power BI. Verá cambios similares al siguiente:
Beneficios de usar SQL Server HierarchyID frente a padre/hijo
Para convencer a cualquiera de usar una característica, necesitamos conocer los beneficios.
Por lo tanto, en esta sección, compararemos declaraciones utilizando las mismas tablas que las del principio. Uno utilizará el ID de jerarquía y el otro utilizará el enfoque padre/hijo. El conjunto de resultados será el mismo para ambos enfoques. Lo esperamos para este ejercicio como el de la Figura 6 arriba.
Ahora que los requisitos son precisos, examinemos los beneficios a fondo.
Más fácil de codificar
Vea el código a continuación:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Esta muestra solo necesita un valor de ID de jerarquía. Puede cambiar el valor a voluntad sin cambiar la consulta.
Ahora, compare la declaración para el enfoque padre/hijo que produce el mismo conjunto de resultados:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)¿Qué piensas? Los ejemplos de código son casi iguales excepto en un punto.
El DÓNDE La cláusula en la segunda consulta no será flexible para adaptarse si se requiere un subárbol diferente.
Haga que la segunda consulta sea lo suficientemente genérica y el código será más largo. ¡Ay!
Ejecución más rápida
Según Microsoft, "las consultas de subárboles son significativamente más rápidas con el ID de jerarquía" en comparación con padre/hijo. Veamos si es verdad.
Usamos las mismas consultas que antes. Una métrica importante para usar para el rendimiento son las lecturas lógicas. desde el FIJAR ESTADÍSTICAS IO . Indica cuántas páginas de 8 KB necesitará SQL Server para obtener el conjunto de resultados que queremos. Cuanto mayor sea el valor, mayor será el número de páginas a las que accede y lee SQL Server, y más lenta se ejecuta la consulta. Ejecute SET STATISTICS IO ON y vuelva a ejecutar las dos consultas anteriores. El valor más bajo de las lecturas lógicas será el ganador.
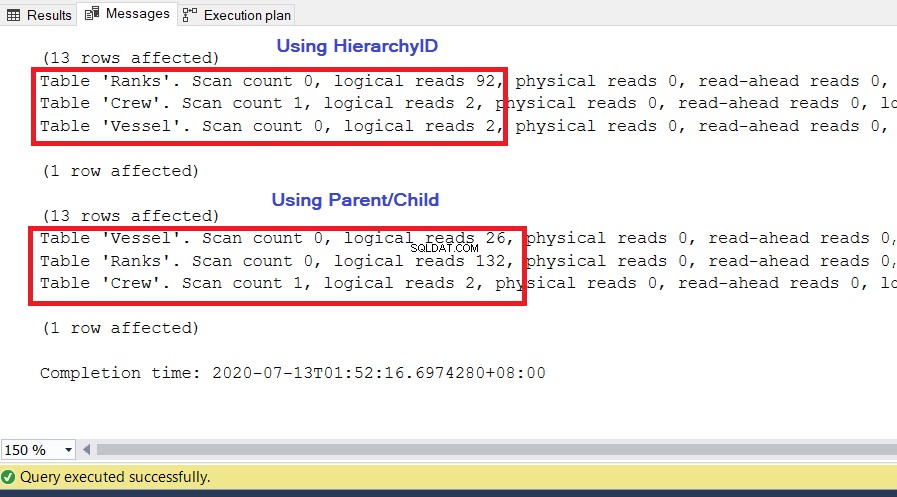
ANÁLISIS
Como puede ver en la Figura 10, las estadísticas de E/S para la consulta con ID de jerarquía tienen lecturas lógicas más bajas que sus contrapartes principales/secundarias. Tenga en cuenta los siguientes puntos en este resultado:
- El Recipiente La mesa es la más notable de las tres mesas. El uso de la jerarquía ID requiere solo 2 * 8 KB =16 KB de páginas para que SQL Server las lea desde la caché (memoria). Mientras tanto, usar padre/hijo requiere 26 * 8 KB =208 KB de páginas, significativamente más que usar el ID de jerarquía.
- Los Clasificaciones table, que incluye nuestra definición de jerarquías, requiere 92 * 8 KB =736 KB. Por otro lado, usar padre/hijo requiere 132 * 8 KB =1056 KB.
- La tripulación la tabla necesita 2 * 8 KB =16 KB, que es lo mismo para ambos enfoques.
Los kilobytes de páginas pueden ser un valor pequeño por ahora, pero solo tenemos unos pocos registros. Sin embargo, nos da una idea de cuán exigente será nuestra consulta en cualquier servidor. Para mejorar el rendimiento, puede realizar una o más de las siguientes acciones:
- Agregar índice(s) apropiado(s)
- Reestructurar la consulta
- Actualizar estadísticas
Si hizo lo anterior y las lecturas lógicas disminuyeron sin agregar más registros, el rendimiento aumentaría. Siempre que haga que las lecturas lógicas sean más bajas que las que usan el ID de jerarquía, serán buenas noticias.
Pero, ¿por qué hacer referencia a lecturas lógicas en lugar de tiempo transcurrido?
Verificando el tiempo transcurrido para ambas consultas usando SET STATISTICS TIME ON revela una pequeña cantidad de diferencias de milisegundos para nuestro pequeño conjunto de datos. Además, su servidor de desarrollo puede tener una configuración de hardware, una configuración de SQL Server y una carga de trabajo diferentes. Un tiempo transcurrido de menos de un milisegundo puede engañarlo si su consulta está funcionando tan rápido como esperaba o no.
EXCAVANDO MÁS
ACTIVAR ESTADÍSTICAS IO no revela las cosas que suceden "detrás de escena". En esta sección, descubrimos por qué SQL Server llega con esos números mirando el plan de ejecución.
Comencemos con el plan de ejecución de la primera consulta.
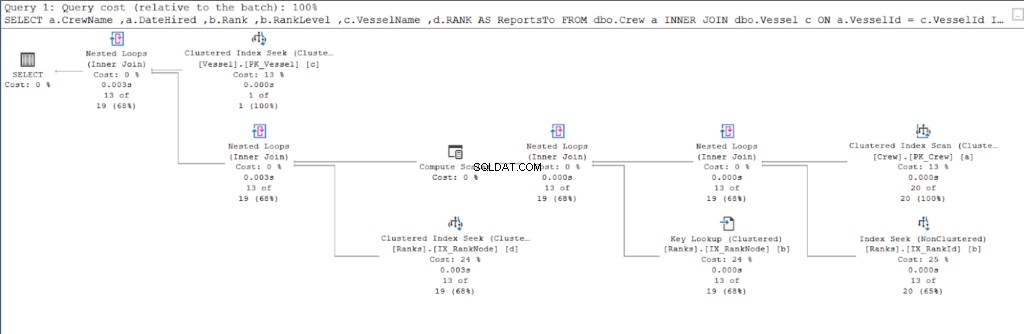
Ahora, observe el plan de ejecución de la segunda consulta.
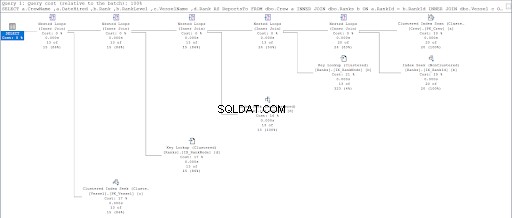
Al comparar las Figuras 11 y 12, vemos que SQL Server necesita un esfuerzo adicional para producir el conjunto de resultados si utiliza el enfoque principal/secundario. El DÓNDE cláusula es responsable de esta complicación.
Sin embargo, la falla también puede ser del diseño de la mesa. Usamos la misma tabla para ambos enfoques:los Clasificaciones mesa. Entonces, traté de duplicar los Clasificaciones pero utiliza diferentes índices agrupados apropiados para cada procedimiento.
En el resultado, usar el ID de jerarquía aún tenía menos lecturas lógicas en comparación con la contraparte principal/secundaria. Finalmente, demostramos que Microsoft tenía razón al reclamarlo.
Conclusión
Aquí el momento central de aha para el ID de jerarquía son:
- HierarchyID es un tipo de datos integrado diseñado para una representación más optimizada de árboles, que son el tipo más común de datos jerárquicos.
- Cada elemento del árbol es un nodo y los valores de ID de jerarquía pueden estar en formato hexadecimal o de cadena.
- HierarchyID se aplica a datos de estructuras organizativas, tareas de proyectos, datos geográficos y similares.
- Existen métodos para recorrer y manipular datos jerárquicos, como GetAncestor (), Obtenerdescendiente (). ObtenerNivel (), ObtenerValorReparentado (), y más.
- La forma convencional de consultar datos jerárquicos es obtener los descendientes directos de un nodo o los subárboles debajo de un nodo.
- El uso del ID de jerarquía para consultar subárboles no solo es más sencillo de codificar. También funciona mejor que padre/hijo.
El diseño padre/hijo no está nada mal, y esta publicación no es para disminuirlo. Sin embargo, expandir las opciones e introducir nuevas ideas es siempre un gran beneficio para un desarrollador.
Puede probar los ejemplos que ofrecemos aquí usted mismo. Reciba los efectos y vea cómo puede aplicarlos para su próximo proyecto que involucre jerarquías.
Si le gusta la publicación y sus ideas, puede correr la voz haciendo clic en los botones para compartir de las redes sociales preferidas.