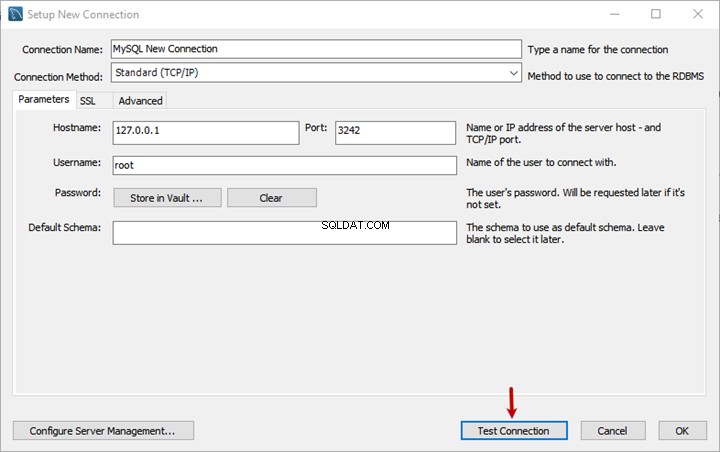
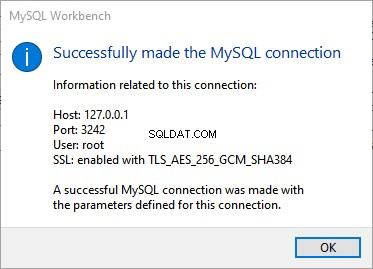
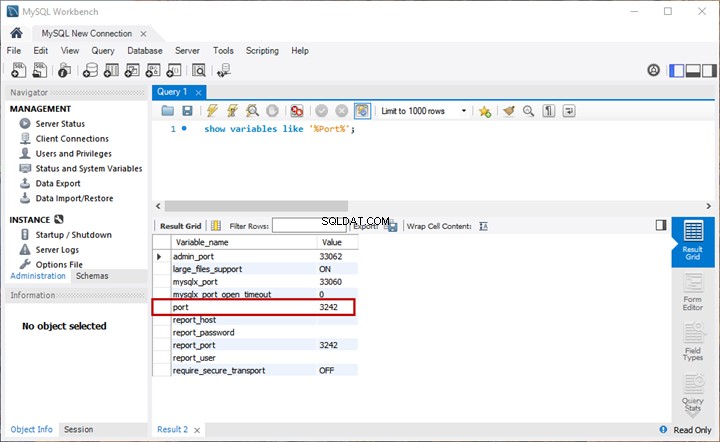
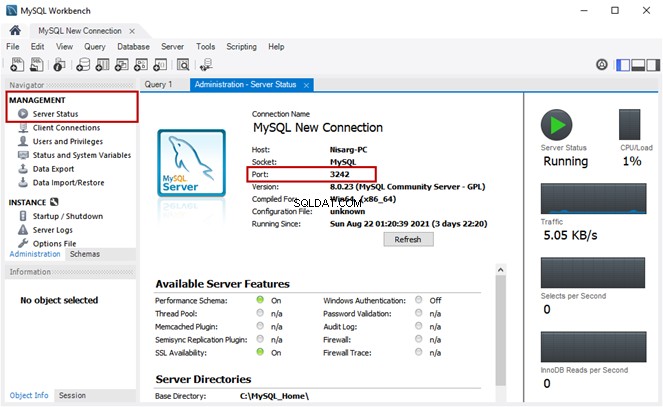
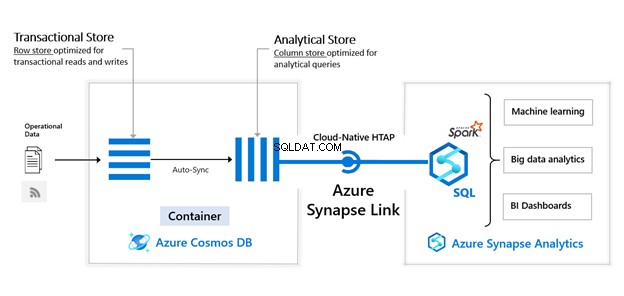
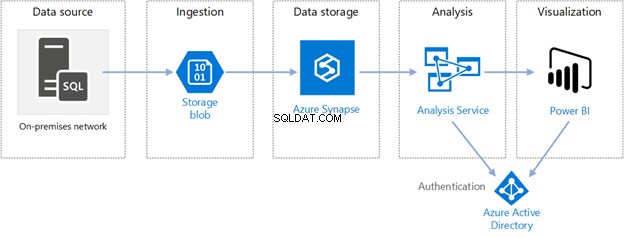
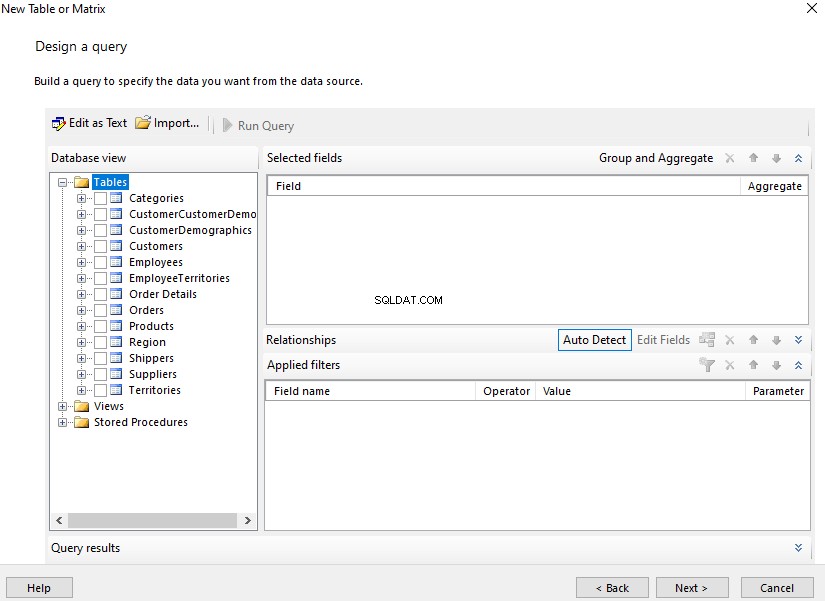
Esta es la segunda parte del material dedicado a la búsqueda semántica de SQL Server . En el artículo anterior, exploramos los conceptos básicos. Ahora, nos vamos a centrar en la comparación de documentos almacenados en Windows File System y el análisis comparativo con la Búsqueda Semántica en SQL Server.
Realización de análisis comparativos de documentos basados en nombres
Vamos a realizar un análisis comparativo de documentos en base a su denominación estándar. En este punto, hagamos una revisión rápida consultando el EmployeesFilestreamSample base de datos que configuramos anteriormente:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
Los resultados deben mostrarnos documentos almacenados:
Lista de verificación de búsqueda semántica
Ya tenemos la base de datos y dos documentos de muestra de MS Word en el sistema de archivos usando la tabla de archivos (puede consultar la Parte 1 para actualizar el conocimiento si es necesario). Sin embargo, eso no califica automáticamente nuestros documentos para el escenario de búsqueda semántica.
La búsqueda semántica se puede habilitar de una de las siguientes maneras:
- Si ya ha configurado la Búsqueda de texto completo , puede habilitar la búsqueda semántica en un solo paso.
- Puede configurar la búsqueda semántica directamente, pero antes también debe configurar la búsqueda de texto completo.
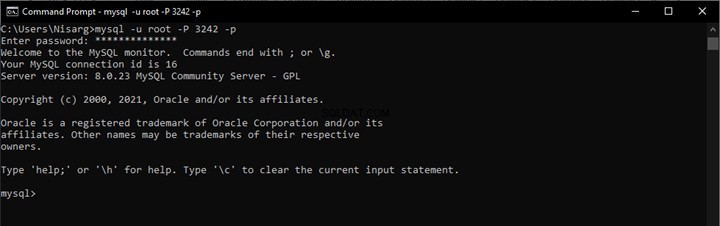
Prueba de búsqueda de texto completo antes de la configuración de búsqueda semántica
Si una consulta de texto completo funciona, solo necesitamos habilitar la búsqueda semántica. Para verificar eso, ejecute una consulta de texto completo en la tabla deseada:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
La salida:
Por lo tanto, primero debemos cumplir con los requisitos de búsqueda de texto completo y luego habilitar la búsqueda semántica.
Habilitación de la búsqueda semántica para uso
Al menos dos de los siguientes puntos son necesarios para usar la búsqueda semántica:
- Índice único
- Un catálogo de texto completo
- Un índice de texto completo
Ejecute el siguiente script T-SQL para crear un índice único:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
Cree un catálogo de texto completo basado en el índice único recién creado. Y luego, cree un índice de texto completo como se muestra a continuación:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
Los resultados:
Prueba de búsqueda de texto completo después de la configuración de búsqueda semántica
Ejecutemos la misma consulta de texto completo para buscar la palabra Empleado en los documentos almacenados:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
La salida:
Está bien que las consultas de texto completo funcionen con la tabla de archivos mientras la preparamos para la búsqueda semántica.
Agregar más documentos de MS Word
Vamos a la EmployeesDocumentStore Tabla de archivos y haga clic en Explorar directorio de tabla de archivos :
Cree y almacene un nuevo documento llamado Empleado contratado por Sadaf :
A continuación, agregue el siguiente texto al documento recién creado. ¡La primera línea debe ser el título del documento!
Empleado contratado por Sadaf (título)
Sadaf es un analista comercial muy eficiente que realiza un trabajo basado en contactos. Es totalmente capaz de manejar los requisitos comerciales y convertirlos en especificaciones técnicas para que trabajen los desarrolladores. Es una analista de negocios con mucha experiencia.
Agregue otro documento llamado Mike Empleado Permanente :
Actualice el documento con el siguiente texto:
Mike Empleado Permanente (Título del documento)
Mike es un programador novato cuya experiencia incluye el desarrollo web. Aprende rápido y está feliz de trabajar en cualquier proyecto. Tiene fuertes habilidades para resolver problemas, pero tiene menos conocimientos de negocios. Requiere asistencia de otros desarrolladores o analistas comerciales para comprender el problema y cumplir con los requisitos.
Es bueno cuando trabaja en proyectos pequeños, pero tiene dificultades si se le asigna un proyecto grande o complejo.
Tenemos cuatro documentos almacenados en el Sistema de archivos de Windows administrado por Tabla de archivos. Estos documentos deben ser consumidos por la búsqueda semántica (incluida la búsqueda de texto completo).
Importante:aunque acabamos de almacenar cuatro documentos de MS Word en la carpeta como muestra, puede imaginar la importancia de usar la búsqueda semántica cuando una base de datos de SQL Server mantiene cientos de dichos documentos y necesita consultar esos documentos para encontrar información valiosa.
La denominación estándar de los documentos es muy importante para la implementación exitosa de este enfoque.
Conteo simple de documentos
Podemos comparar estos documentos y definir las diferencias y similitudes en función de su denominación estándar mediante la búsqueda semántica. Por ejemplo, una simple consulta puede decirnos el número total de documentos almacenados en la Carpeta de Windows:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

Comparación de empleados permanentes y empleados por contrato
Esta vez, estamos utilizando la búsqueda semántica para comparar la cantidad de empleados permanentes y por contrato en nuestra organización:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
La salida:
Ejecutemos una consulta de búsqueda semántica simple (basada en el nombre del documento) para ver la frase clave y su puntuación relativa para cada documento:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
La salida:
Agreguemos más detalles a los nombres de los documentos. Los renombraremos de la siguiente manera:
- Empleado permanente de Asif - Gerente de proyecto experimentado
- Mike empleado permanente - Programador nuevo
- Peter Empleado Permanente - Gerente de Proyecto Nuevo
- Empleado por contrato de Sadaf:analista comercial experimentado
Encontrar nuevos empleados (documentos)
Encuentre los documentos relacionados con los nuevos empleados en función de sus títulos (nomenclatura estándar):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
Los resultados:
Encontrar empleados con experiencia (documentos)
Supongamos que queremos revisar rápidamente todos los detalles de los empleados experimentados para el complejo proyecto que tenemos por delante. Utilice la siguiente consulta de búsqueda semántica:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
La salida:
Encontrar todos los Gerentes de Proyecto (Documentos)
Finalmente, si queremos revisar rápidamente los documentos de todos los gerentes de proyecto, necesitamos la siguiente consulta de búsqueda semántica:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
Los resultados:
Después de implementar el tutorial, puede almacenar con éxito datos no estructurados, como documentos de MS Word, en una carpeta de Windows usando la tabla de archivos.
Revisión de análisis basada en nombres
Hasta ahora, hemos aprendido a realizar un análisis basado en nombres de documentos almacenados en una tabla de archivos mediante la búsqueda semántica. Sin embargo, necesitamos que se cumplan las siguientes condiciones:
- Debe haber una nomenclatura estándar.
- Los nombres deben proporcionar la información requerida para el análisis.
Estas condiciones también son limitaciones del análisis basado en nombres. Pero esto no significa que no podamos hacer mucho con él.
Nuestro enfoque permanece en el enfoque de búsqueda semántica basada en nombre/columna.
Ver las Columnas de Nombre de los Documentos
Veamos algunas de las columnas principales de la tabla Documentos, incluido el Nombre columna:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
La salida:
Comprender la función SEMANTICKEYPHRASETABLE
SQL Server ofrece la SEMANTICKEYPHRASETABLE Función para analizar el documento con búsqueda semántica. La sintaxis es la siguiente:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
Esta función nos da frases clave asociadas con el documento. Podemos usarlos para analizar documentos en función de sus nombres o contenido. En nuestro caso, no solo necesitamos usar esta función, sino también comprender cómo utilizarla correctamente.
La función requiere los siguientes datos:
- Nombre de la tabla de archivos que se usará para el análisis de búsqueda semántica.
- Nombre de la columna que se utilizará para el análisis de búsqueda semántica.
Luego devuelve los siguientes datos:
- Id_columna – el número de columna
- Clave_del_documento – la clave principal predeterminada para el documento de tabla de archivos
- Frase clave – es una frase que Semantic Search decide indexar para su análisis. Se aplica tanto al nombre como al contenido del documento según la columna en la que queremos ver las frases clave
- Puntuación – determina la fuerza de una frase clave asociada con un documento, por ejemplo, cómo se reconoce mejor un documento por su frase clave. La puntuación puede estar entre 0,0 y 1,0.
Análisis de todos los documentos mediante la función SEMANTICKEYPHRASETABLE
Utilizamos la SEMANTICKEYPHRASETABLE función para el análisis basado en el nombre de los documentos almacenados en la carpeta de Windows administrada por la Tabla de archivos.
Ejecute el siguiente script T-SQL:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
La salida:
Tenemos una lista de todas las frases clave adjuntas a todos los documentos y sus puntajes. El id_columna 3 en la fila superior está el nombre columna. Además, también llamamos a la función proporcionando esta columna (nombre):
Puede encontrar la document_key : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 ejecutando el siguiente script (aunque es claro que este documento es aquel donde el nombre contiene la frase clave sadaf ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
La salida:
La frase clave sadaf ha obtenido la mejor puntuación :
Así, en el caso de la nomenclatura estándar de documentos con información suficiente para el análisis de Búsqueda Semántica, nuestra frase clave sadaf es la mejor coincidencia para ese nombre de documento en particular.
Análisis de un documento específico mediante la función SEMANTICKEYPHRASETABLE
Podemos limitar nuestro análisis de búsqueda semántica en función del nombre columna. Por ejemplo, solo necesitamos ver la columna name- frases clave basadas en un documento en particular. Podemos especificar la clave del documento en la SEMANTICKEYPHRASETABLE Función.
Primero, identificamos la clave del documento para ese documento donde queremos ver todas las frases clave. Ejecute el siguiente script T-SQL:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
La clave del documento es 0xFF6A92952500812FF013376870181CFA6D7C070220
Ahora, veamos este documento con respecto a todas las frases clave que pueden definir el nombre del documento:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
Los resultados:
La frase clave empleado
Comprender la función SEMANTICSIMILARITYTABLE
Esta función nos ayuda a comparar un documento con todos los demás documentos en función de frases clave. La sintaxis de esta función es la siguiente:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
Requiere el nombre de la tabla, la columna y la clave del documento para que coincida con otros documentos. Por ejemplo, podemos afirmar que dos documentos son similares si tienen una buena puntuación de coincidencia de frases clave.
Comparación de documentos usando la función SEMANTICSIMILARITYTABLE
Comparemos un documento con otros documentos usando la TABLA DE SIMILARIDAD SEMÁNTICA Función.
Comparación de todos los documentos de los directores de proyecto
Necesitamos ver todos los documentos relacionados con los gerentes de proyecto. De los ejemplos anteriores, sabemos que la clave del documento para el documento especificado es 0xFF6A92952500812FF013376870181CFA6D7C070220 . Por lo tanto, podemos usar esta clave para encontrar otras coincidencias, incluidos los administradores de proyectos:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
La salida:
El documento más relacionado es Empleado permanente de Asif - Gerente de proyecto experimentado.docx
Comparación de documentos de analistas de negocios experimentados
Ahora, vamos a comparar los documentos relacionados con analista de negocios experimentado s y encuentre la coincidencia más cercana mediante la búsqueda semántica. Estamos limitados al análisis basado en el nombre del documento:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
La salida:
Como podemos ver en los resultados anteriores, la coincidencia más cercana para el documento relacionado con el analista de negocios experimentado es el documento del gestor de proyectos experimentado porque ambos tienen experiencia . Sin embargo, la puntuación de 0,3 indica que no hay mucho en común entre estos dos documentos.
Conclusión
¡Felicidades! Hemos aprendido con éxito cómo almacenar documentos en carpetas de Windows y analizarlos utilizando la búsqueda semántica. También exploramos las funciones a utilizar en la práctica. Ahora puedes aplicar los nuevos conocimientos y probar los siguientes ejercicios para
¡Estén atentos para más materiales!