Está utilizando la herencia (también conocida en el modelado entidad-relación como "subclase" o "categoría"). En general, hay 3 formas de representarlo en la base de datos:
- "Todas las clases en una tabla": Tenga solo una tabla que "cubra" el padre y todas las clases secundarias (es decir, con todas las columnas principal y secundaria), con una restricción CHECK para garantizar que el subconjunto correcto de campos no sea NULL (es decir, dos hijos diferentes no se "mezclan").
- "Clase concreta por tabla": Tenga una mesa diferente para cada niño, pero no una mesa principal. Esto requiere que las relaciones de los padres (en su caso, Inventario <- Almacenamiento) se repitan en todos los hijos.
- "Clase por mesa": Tener una mesa principal y una mesa separada para cada hijo, que es lo que está tratando de hacer. Esto es más limpio, pero puede costar algo de rendimiento (principalmente al modificar datos, no tanto al realizar consultas porque puede unirse directamente desde el elemento secundario y omitir el principal).
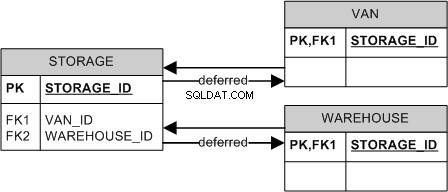
Por lo general, prefiero el tercer enfoque, pero hago cumplir tanto la presencia y la exclusividad de un niño a nivel de aplicación. Hacer cumplir ambos a nivel de la base de datos es un poco engorroso, pero se puede hacer si el DBMS admite restricciones diferidas. Por ejemplo:
CHECK (
(
(VAN_ID IS NOT NULL AND VAN_ID = STORAGE_ID)
AND WAREHOUSE_ID IS NULL
)
OR (
VAN_ID IS NULL
AND (WAREHOUSE_ID IS NOT NULL AND WAREHOUSE_ID = STORAGE_ID)
)
)
Esto hará cumplir tanto la exclusividad (debido al CHECK ) y la presencia (debido a la combinación de CHECK y FK1 /FK2 ) del niño.
Desafortunadamente, MS SQL Server no admite restricciones diferidas, pero es posible que pueda "ocultar" toda la operación detrás de los procedimientos almacenados y prohibir que los clientes modifiquen las tablas directamente.
Solo se puede hacer cumplir la exclusividad sin restricciones diferidas:
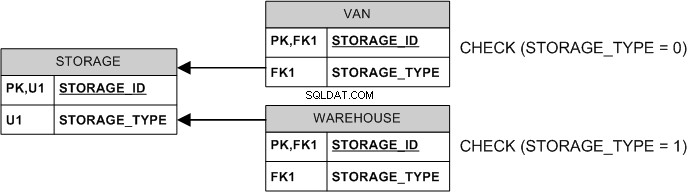
El STORAGE_TYPE es un discriminador de tipo, generalmente un número entero para ahorrar espacio (en el ejemplo anterior, 0 y 1 son "conocidos" por su aplicación y se interpretan en consecuencia).
El VAN.STORAGE_TYPE y WAREHOUSE.STORAGE_TYPE se pueden calcular (también conocido como "calculado") columnas para ahorrar almacenamiento y evitar la necesidad de CHECK s.
--- EDITAR ---
Las columnas calculadas funcionarían bajo SQL Server así:
CREATE TABLE STORAGE (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE tinyint NOT NULL,
UNIQUE (STORAGE_ID, STORAGE_TYPE)
);
CREATE TABLE VAN (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE AS CAST(0 as tinyint) PERSISTED,
FOREIGN KEY (STORAGE_ID, STORAGE_TYPE) REFERENCES STORAGE(STORAGE_ID, STORAGE_TYPE)
);
CREATE TABLE WAREHOUSE (
STORAGE_ID int PRIMARY KEY,
STORAGE_TYPE AS CAST(1 as tinyint) PERSISTED,
FOREIGN KEY (STORAGE_ID, STORAGE_TYPE) REFERENCES STORAGE(STORAGE_ID, STORAGE_TYPE)
);
-- We can make a new van.
INSERT INTO STORAGE VALUES (100, 0);
INSERT INTO VAN VALUES (100);
-- But we cannot make it a warehouse too.
INSERT INTO WAREHOUSE VALUES (100);
-- Msg 547, Level 16, State 0, Line 24
-- The INSERT statement conflicted with the FOREIGN KEY constraint "FK__WAREHOUSE__695C9DA1". The conflict occurred in database "master", table "dbo.STORAGE".
Desafortunadamente, SQL Server requiere una columna calculada que se usa en un extranjero clave para ser PERSISTENTE. Es posible que otras bases de datos no tengan esta limitación (por ejemplo, las columnas virtuales de Oracle), lo que puede ahorrar algo de espacio de almacenamiento.



