La respuesta, por supuesto, será "depende", pero según las pruebas de este extremo...
Suponiendo
- 1 millón de productos
producttiene un índice agrupado enproduct_id- La mayoría de los productos (si no todos) tienen la información correspondiente en el
product_codemesa - Índices ideales presentes en
product_codepara ambas consultas.
El PIVOT idealmente, la versión necesita un índice product_code(product_id, type) INCLUDE (code) mientras que JOIN idealmente, la versión necesita un índice product_code(type,product_id) INCLUDE (code)
Si estos están en su lugar dando los planes a continuación
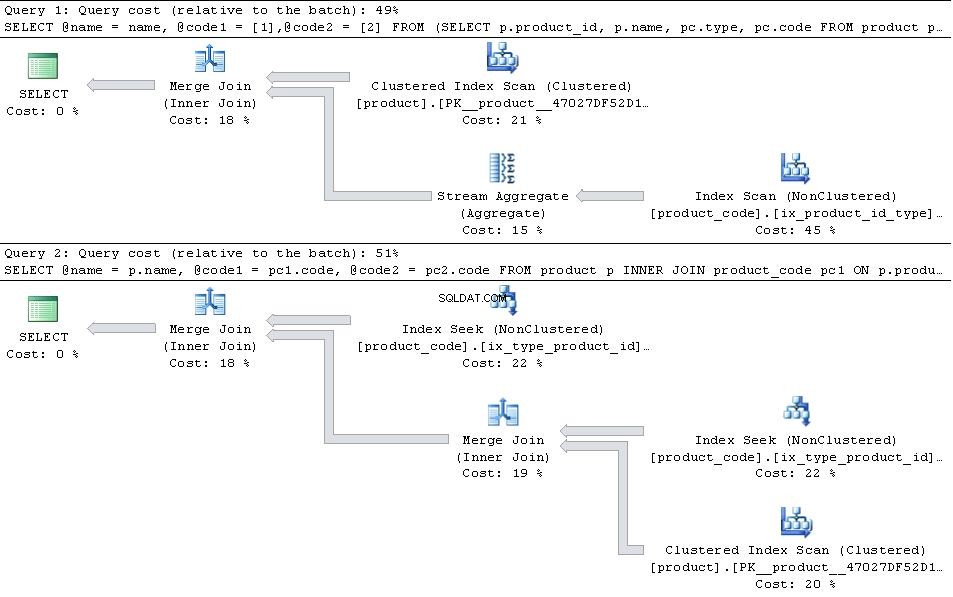
luego el JOIN La versión es más eficiente.
En el caso de que type 1 y type 2 son los únicos types en la tabla, entonces el PIVOT la versión tiene una ligera ventaja en términos de número de lecturas, ya que no tiene que buscar en product_code dos veces, pero eso es más que superado por la sobrecarga adicional del operador agregado de flujo
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
ÚNETE
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Si hay type adicionales registros que no sean 1 y 2 el JOIN La versión aumentará su ventaja ya que solo fusiona uniones en las secciones relevantes del type,product_id index mientras que el PIVOT el plan usa product_id, type y entonces tendría que escanear el type adicional filas que se entremezclan con el 1 y 2 filas.