Breve resumen
- El rendimiento del método de subconsultas depende de la distribución de datos.
- El rendimiento de la agregación condicional no depende de la distribución de datos.
El método de subconsultas puede ser más rápido o más lento que la agregación condicional, depende de la distribución de datos.
Naturalmente, si la tabla tiene un índice adecuado, es probable que las subconsultas se beneficien de él, porque el índice permitiría escanear solo la parte relevante de la tabla en lugar del escaneo completo. Es poco probable que tener un índice adecuado beneficie significativamente al método de agregación condicional, porque de todos modos escaneará el índice completo. El único beneficio sería si el índice es más estrecho que la tabla y el motor tendría que leer menos páginas en la memoria.
Sabiendo esto, puede decidir qué método elegir.
Primera prueba
Hice una mesa de prueba más grande, con filas de 5M. No había índices en la tabla. Medí las estadísticas de IO y CPU usando SQL Sentry Plan Explorer. Usé SQL Server 2014 SP1-CU7 (12.0.4459.0) Express de 64 bits para estas pruebas.
De hecho, sus consultas originales se comportaron como usted describió, es decir, las subconsultas fueron más rápidas a pesar de que las lecturas fueron 3 veces más altas.
Después de algunos intentos en una tabla sin índice, reescribí su agregado condicional y agregué variables para mantener el valor de DATEADD expresiones.
El tiempo total se volvió significativamente más rápido.
Luego reemplacé SUM con COUNT y volvió a ser un poco más rápido.
Después de todo, la agregación condicional se volvió casi tan rápida como las subconsultas.
Calentar el caché (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subconsultas (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Agregación condicional original (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregación condicional con variables (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregación condicional con variables y COUNT en lugar de SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Según estos resultados, supongo que CASE invocó DATEADD para cada fila, mientras que WHERE fue lo suficientemente inteligente como para calcularlo una vez. Más COUNT es un poquito más eficiente que SUM .
Al final, la agregación condicional es solo un poco más lenta que las subconsultas (1062 frente a 1031), tal vez porque WHERE es un poco más eficiente que CASE en sí mismo, y además, WHERE filtra bastantes filas, por lo que COUNT tiene que procesar menos filas.
En la práctica, usaría la agregación condicional, porque creo que la cantidad de lecturas es más importante. Si su tabla es pequeña para caber y permanecer en el grupo de búfer, entonces cualquier consulta será rápida para el usuario final. Pero, si la tabla es más grande que la memoria disponible, espero que la lectura desde el disco ralentice significativamente las subconsultas.
Segunda prueba
Por otro lado, también es importante filtrar las filas lo antes posible.
Aquí hay una ligera variación de la prueba, que lo demuestra. Aquí configuro el umbral para que sea GETDATE() + 100 años, para asegurarme de que ninguna fila satisfaga los criterios del filtro.
Calentar el caché (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subconsultas (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Agregación condicional original (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregación condicional con variables (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Agregación condicional con variables y COUNT en lugar de SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
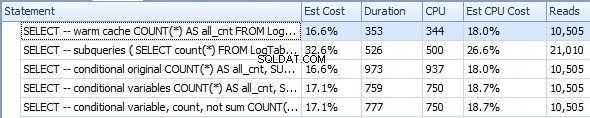
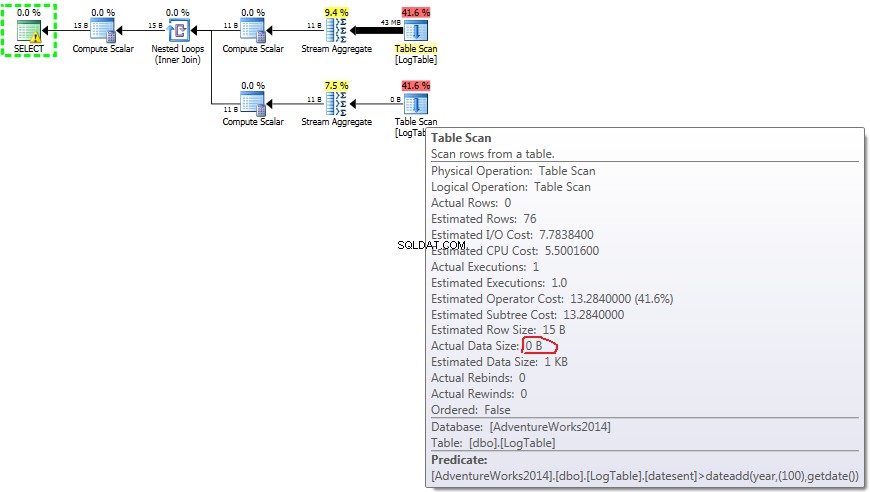
A continuación se muestra un plan con subconsultas. Puede ver que 0 filas entraron en Stream Aggregate en la segunda subconsulta, todas ellas se filtraron en el paso Table Scan.
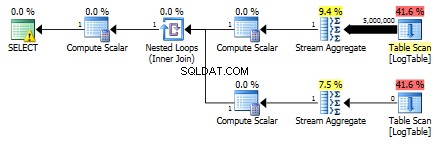
Como resultado, las subconsultas vuelven a ser más rápidas.
Tercera prueba
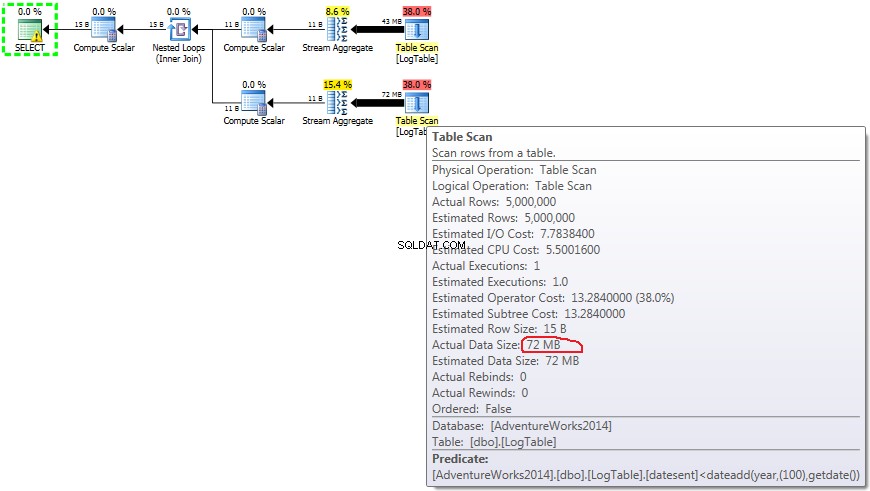
Aquí cambié el criterio de filtrado de la prueba anterior:all > fueron reemplazados por < . Como resultado, el condicional COUNT contó todas las filas en lugar de ninguna. ¡Sorpresa sorpresa! La consulta de agregación condicional tomó los mismos 750 ms, mientras que las subconsultas se convirtieron en 813 en lugar de 500.

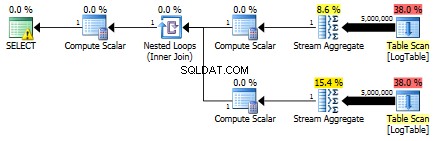
Este es el plan para las subconsultas:
¿Podría darme un ejemplo, donde la agregación condicional supera notablemente a la solución de subconsulta?
Aquí está. El rendimiento del método de subconsultas depende de la distribución de datos. El rendimiento de la agregación condicional no depende de la distribución de datos.
El método de subconsultas puede ser más rápido o más lento que la agregación condicional, depende de la distribución de datos.
Sabiendo esto, puede decidir qué método elegir.
Detalles de bonificación
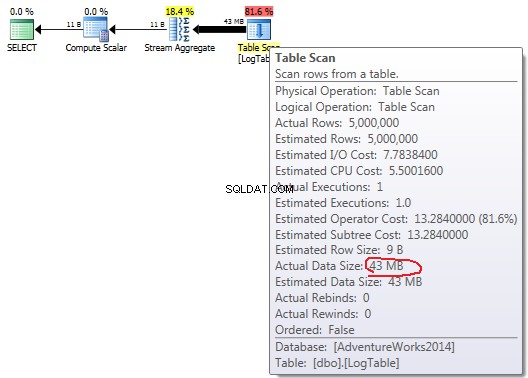
Si pasa el mouse sobre el Table Scan puede ver el Actual Data Size en diferentes variantes.
- Simple
COUNT(*):
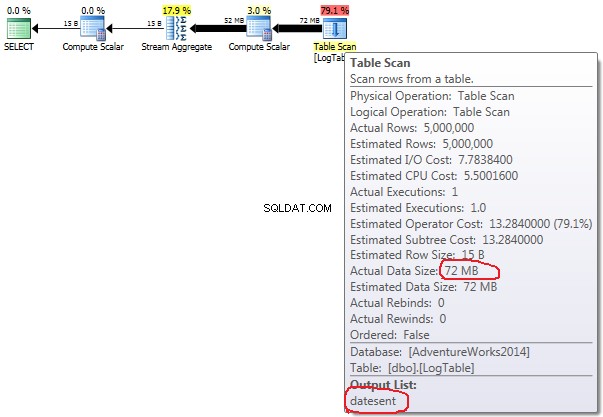
- Agregación condicional:
- Subconsulta en la prueba 2:
- Subconsulta en la prueba 3:
Ahora queda claro que la diferencia en el rendimiento probablemente se deba a la diferencia en la cantidad de datos que fluyen a través del plan.
En caso de simple COUNT(*) no hay Output list (no se necesitan valores de columna) y el tamaño de los datos es el más pequeño (43 MB).
En caso de agregación condicional, esta cantidad no cambia entre las pruebas 2 y 3, siempre es de 72 MB. Output list tiene una columna datesent .
En caso de subconsultas, esta cantidad no cambiar dependiendo de la distribución de datos.