En este artículo, analizaremos varios problemas que puede enfrentar al crear, configurar o mantener un sitio de grupo de disponibilidad Always on.
Antes de leer este artículo, se recomienda leer el artículo anterior, Configuración y configuración del grupo de disponibilidad Always on en SQL Server, para familiarizarse con el concepto de grupo de disponibilidad Always on y los asistentes para nuevos grupos de disponibilidad que se muestran en este artículo.
Función de grupo de disponibilidad siempre activa no habilitada
Suponga que, al intentar crear un nuevo grupo de disponibilidad Always on, desde el nodo de alta disponibilidad Always On, en el Explorador de objetos de SQL Server Management Studio, recibió el siguiente mensaje de error:
La función Grupos de disponibilidad siempre activos debe estar habilitada para la instancia de servidor 'SQL1' antes de poder crear un grupo de disponibilidad en esta instancia. Para habilitar esta función, abra el Administrador de configuración de SQL Server, seleccione Servicios de SQL Server, haga clic con el botón derecho en el nombre del servicio de SQL Server, seleccione Propiedades y use la pestaña Grupos de disponibilidad siempre activos del cuadro de diálogo Propiedades del servidor. Habilitar los grupos de disponibilidad siempre activos puede requerir que la instancia del servidor esté alojada en un nodo de clúster de conmutación por error de Windows Server (WSFC). (Microsoft.SqlServer.Management.HadrTasks)

Del mensaje de error se desprende claramente que la función Grupos de disponibilidad AlwaysOn debe estar habilitada en cada instancia de SQL Server que participe en el sitio del Grupo de disponibilidad AlwaysOn, antes de crear ese sitio.
Puede habilitar fácilmente la función Siempre en el grupo de disponibilidad abriendo la consola del Administrador de configuración de SQL Server, navegando por la pestaña Servicios de SQL Server y luego haciendo clic con el botón derecho en el servicio Motor de base de datos de SQL Server y eligiendo la opción Propiedades.
Desde la ventana Propiedades de SQL Server abierta, vaya a la pestaña Siempre en alta disponibilidad y marque la casilla de verificación junto a Habilitar siempre en grupo de disponibilidad , teniendo en cuenta que este cambio requiere reiniciar el servicio de SQL Server para que surta efecto, como se muestra a continuación:

Problema de validación de requisitos previos de la base de datos
En los pasos anteriores del asistente Nuevo grupo de disponibilidad, se le pedirá que especifique las bases de datos que participarán en el grupo de disponibilidad siempre activo. Antes de agregar la base de datos, la base de datos debe pasar la verificación de validación de requisitos previos. De lo contrario, la base de datos no se puede seleccionar de las listas de bases de datos, como se muestra en el siguiente mensaje de error:
Para agregarse a un grupo de disponibilidad, esta base de datos debe configurarse en el modelo de recuperación completa. Establezca la propiedad de la base de datos Modelo de recuperación en Completo y realice una copia de seguridad de base de datos completa o diferencial en la base de datos. Luego deberá programar copias de seguridad de registros en la base de datos.

El mensaje es claro. Donde la base de datos debe configurarse con un modelo de recuperación completa y debe realizarse una copia de seguridad completa o diferencial en esa base de datos.
Además, el asistente le advierte que programe una copia de seguridad del registro de transacciones para esa base de datos después de cambiar el modelo de recuperación a Completo, para truncar el archivo de registro de transacciones automáticamente y evitar ejecutar ese archivo de registro de transacciones sin espacio libre.
Para solucionar ese problema, cambie el modelo de recuperación de la base de datos de simple a completo, desde la pestaña Opciones de la ventana de propiedades de la base de datos, luego realice una copia de seguridad completa de esa base de datos, como se muestra a continuación:

Al actualizar la ventana Seleccionar bases de datos, el estado de la base de datos cambiará a Cumplir con los requisitos previos, como se muestra a continuación:

Problema de permiso de ubicación de red compartida
Al intentar configurar un sitio de grupo de disponibilidad siempre activo, el paso de validación del asistente Nuevo grupo de disponibilidad falló con el siguiente mensaje de error:
El servidor principal 'SQL1' no puede escribir en '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
Error en la copia de seguridad del servidor 'SQL1'. (Microsoft.SqlServer.SmoExtended)
No se puede abrir el dispositivo de respaldo '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. Error 5 del sistema operativo (acceso denegado).
BACKUP DATABASE finaliza de manera anormal. (Proveedor de datos de .Net SqlClient)
En el método de sincronización inicial de copia de seguridad de registro y base de datos completa, se requiere una carpeta compartida para mantener los archivos de copia de seguridad de registro de transacciones y copia de seguridad completa temporalmente para restaurarlos en todas las réplicas secundarias. Si la réplica principal no puede escribir los archivos de respaldo en ella, o las réplicas secundarias no pueden leer los archivos de respaldo, el proceso de validación del nuevo grupo de disponibilidad fallará como se indica a continuación:

Para solucionar ese problema, debemos otorgar a la cuenta de servicio de SQL Server de las réplicas principal y secundaria permiso de lectura y escritura en la carpeta compartida que se muestra en el mensaje de error, luego volver a ejecutar el proceso de validación para asegurarnos de que todas las comprobaciones se hayan realizado correctamente. , como se muestra a continuación:

Problema del clúster de conmutación por error de Windows
Suponga que está comprobando el estado de un sitio de grupo de disponibilidad Always on existente y verá que:
- La función principal se mueve de la instancia de SQL1 a SQL2.
- En SQL2, las bases de datos están en estado Sincronizado.
- En SQL1, las bases de datos no están sincronizadas.
- SQL1 está en estado de resolución.
Como puede ver claramente en el Explorador de objetos de SSMS a continuación:

Al revisar los registros de errores de SQL Server en el nodo problemático, podemos ver que la réplica del grupo de disponibilidad se desconecta y el grupo de disponibilidad dejó de funcionar debido a un problema en el clúster de conmutación por error de Windows Server, como se muestra en los errores a continuación:
- Grupos de disponibilidad siempre activos:el nodo local de clústeres de conmutación por error de Windows Server ya no está en línea . este es solo un mensaje informativo. No se requiere ninguna acción del usuario.
- Siempre activado:el administrador de réplicas de disponibilidad se desconecta porque el nodo local de clústeres de conmutación por error de Windows Server (WSFC) ha perdido el quórum. este es solo un mensaje informativo. No se requiere ninguna acción del usuario.
- Siempre encendido:la réplica local del grupo de disponibilidad 'DemoGroup' se está deteniendo. este es solo un mensaje informativo. No se requiere ninguna acción del usuario.

Lo mismo se puede detectar desde el Visor de eventos de Windows Server, que muestra gradualmente cómo la réplica cambia su estado a Resolver, como se muestra a continuación:
- Siempre activo:la réplica local del grupo de disponibilidad 'DemoGroup' se está preparando para la transición a la función de resolución . este es solo un mensaje informativo. No se requiere ninguna acción del usuario.
- Se le pide al grupo de disponibilidad 'DemoGroup' que detenga la renovación de la concesión porque el grupo de disponibilidad se desconecta . este es solo un mensaje informativo. No se requiere ninguna acción del usuario.
- El estado de la réplica de disponibilidad local en el grupo de disponibilidad 'DemoGroup' ha cambiado de 'PRIMARY_NORMAL' a 'RESOLVING_NORMAL'. El estado cambió porque el grupo de disponibilidad se está desconectando. La réplica se desconecta porque el grupo de disponibilidad asociado se eliminó, o el usuario desconectó el grupo de disponibilidad asociado en la consola de administración de Clústeres de conmutación por error de Windows Server (WSFC), o el grupo de disponibilidad está conmutando por error a otra instancia de SQL Server. Para obtener más información, consulte el registro de errores o el registro del clúster de SQL Server. Si se trata de un grupo de disponibilidad de Windows Server Failover Clustering (WSFC), también puede ver la consola de administración de WSFC.

Para comprobar el estado del sitio del clúster de Windows, utilizaremos el Administrador de clústeres de conmutación por error para ver qué parte del clúster de Windows está fallando.
Pero el Administrador de clústeres de conmutación por error muestra que todo el clúster está inactivo, como se muestra a continuación:

Lo primero que debe validar aquí desde el lado del clúster de conmutación por error de Windows es el servicio de clúster, que se puede verificar desde la consola de servicios de Windows, como se muestra a continuación:

Está claro en la consola de Servicios que el Servicio de Cluster Server no se está ejecutando. Para solucionar ese problema, inicie el servicio desde esa consola, luego actualice la consola del Administrador de clústeres de conmutación por error para asegurarse de que el sitio del clúster de Windows esté en funcionamiento, como se muestra a continuación:

Al volver a verificar el grupo de disponibilidad Always on, verá que las bases de datos están sincronizadas nuevamente y el sitio del grupo de disponibilidad Always on está nuevamente en estado de salud, como se muestra a continuación:

El archivo de registro de transacciones está lleno en el lado principal
Suponga que recibe el siguiente mensaje de error cuando intenta ejecutar una nueva consulta en una de las bases de datos del grupo de disponibilidad Always on:

Al comprobar qué está bloqueando el archivo de registros de transacciones y evita que se trunque, verá que el archivo de registro de transacciones de esta base de datos está pendiente de que se trunque la operación de copia de seguridad del registro, como se muestra a continuación:

Realizar una copia de seguridad del registro de transacciones para esa base de datos, en caso de que olvide programar un trabajo de copia de seguridad del registro de transacciones, de la siguiente manera:

Y verifique nuevamente qué está bloqueando el registro de transacciones de esa base de datos, muestra en mi escenario que está esperando Availability_Replica. Lo que significa que los registros están esperando a que se escriban en la réplica secundaria, pero no pueden enviar estos registros de transacciones a las réplicas secundarias debido a un problema en el sitio del grupo de disponibilidad Always on, como se muestra a continuación:

La mejor ubicación para comprobar y solucionar problemas del sitio del grupo de disponibilidad Always on es el panel de control Always on, que se puede abrir haciendo clic con el botón derecho en el nombre del grupo de disponibilidad y seleccionando la opción Mostrar panel.
Desde el panel, puede ver que la réplica secundaria SQL2 no está sincronizada con la réplica principal debido a un problema de conectividad, como se muestra a continuación:

Comprobando la réplica secundaria y asegurándose de que el servicio de SQL Server esté activo y ejecutándose en el lado secundario, de la siguiente manera:

Luego, al actualizar de nuevo el panel del grupo de disponibilidad, verá que el sitio del grupo de disponibilidad siempre activo vuelve a estar en buen estado. Checking if the transaction logs file is blocked by any operation, we will see that it is pending OLDEST_PAGE, indicating that the oldest page of the database is older than the checkpoint LSN. This issue can be fixed easily by taking another transaction log backup and the transaction log file will be blocked by nothing, as shown clearly below:

Always on Availability Group Failover Misconfiguration
Assume that the Primary replica becomes offline due to an unplanned issue. As expected, the system will not be affected as an automatic failover operation will be performed and the secondary replica will act as the new Primary replica.
But in our case, this happy scenario is not valid, where the secondary replica changed to Resolving state and the system is down!

Checking the secondary replica’s error log and see why it is not acting as the new Primary as expected, you will see that it is failing due to a role synchronization issue, as shown below:
The availability group database "AdventureWorks2017" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.

This means that there is an issue with the synchronization mode that is used in this Availability Group. The synchronization mode used, can be checked from the Always on Availability Group properties page.
From the properties page below, it is clear that the Failover mode in this Availability Group is configured to be performed Manually only. In this case, you need to manually perform a failover operation before rebooting or shutting down the server:

This can be fixed easily by changing the Failover Mode to Automatic, where an automatic failover operation will be performed in case of any unplanned shutdown or reboot:

The same issue can be faced when the Windows Failover Cluster quorum is configured with Node Majority for an even number of replicas, where any failure for one of the servers will bring the Windows Failover Cluster site offline. For more information, check Windows Failover Cluster Quorum Modes in SQL Server Always On Availability Groups:

Failover with Data Loss
Assume that you are trying to perform a manual failover between the Primary and one of the Secondary replicas, but in the Select New Primary Replica window, you see a warning message that the failover operation may end up with data loss as the Primary and the selected Secondary replica are not synchronized, as shown below:

To identify the cause of that issue, we will browse the Always on Health events using the Always on Availability Group dashboard, which shows that the Primary replica is not able to open a connection to the Secondary replica, ash shown below:

After fixing the connectivity issue between the Primary and the Secondary, refresh the replicas list and you will see that the data loss issue is fixed, as shown below. For more information about troubleshooting the connectivity issues, check Troubleshoot connecting to the SQL Server Database Engine.

Monitoring Always on Availability Group Latency
The Availability Group dashboard can be modified to include additional columns that provide information about the synchronization latency between Primary and Secondary replicas, including the Commit LSN, Sent LSN and harden LSN values, without showing why there is a latency, as shown below:
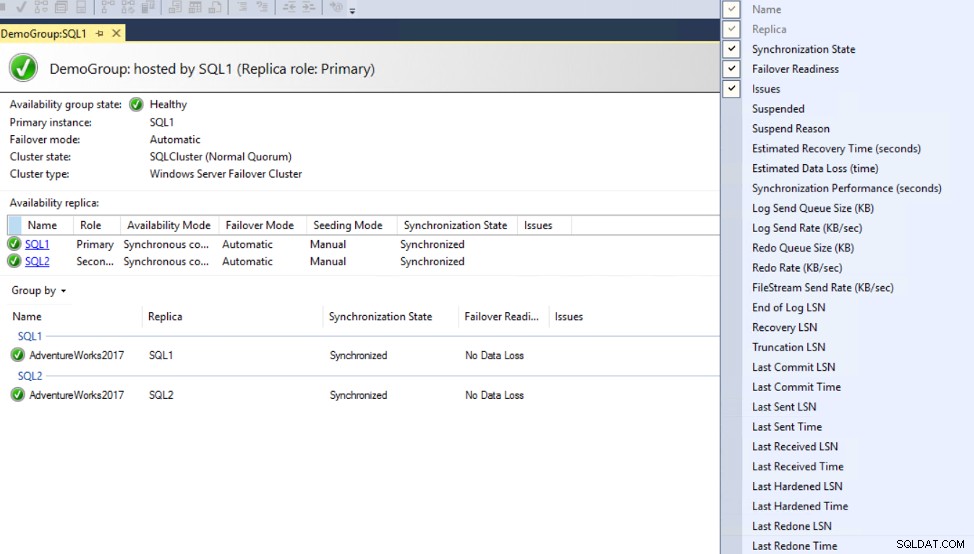
For more information about measuring the latency, check the Measuring Availability Group synchronization lag.
Starting from SSMS 17.4, the Always on Availability Group dashboard enhanced to include two new options that are used for latency information calculation, analysis and reporting, which helps in identifying the bottlenecks in the transaction logs flow between the Primary and the Secondary replicas and narrow down the cause of that latency.
For more information about the new functionality and reports, check to Use the Always on Availability Group dashboard.
To trigger using this new option, click on Collect Latency Data option from the Always on Availability Group dashboard, that will create a new SQL Agent job on the Primary and Secondary replicas to collect the latency data, As shown below:

When the created job execution has completed on all the Availability Group replicas, you will be able to view the latency statistics from the latency reports by right-clicking on the Availability Group name and choose the Primary Replica Latency or Secondary Replica Latency report, based on the replica role in the Availability Group.
After providing information about the Availability Group replicas, the latency report will show a graphical view of the transaction log commit time on the Primary replica and the remote Hardening time for the secondary replicas, aggregated as average values. Also, the report provides statistical values for the transaction logs send, receive, commit, compress, decompress and other numerical values based on the replica role in the Availability Group.
For more information about the latency report, check New in SSMS - Always On Availability Group Latency Reports.
The below report is an example of the latency reports generated from the Secondary replica, showing normal logs transport operations:

Also, the Log Block Latency report shows the amount of time, in ms, that the transaction log on the Primary replica waits for Secondary replicas to commit that transaction. After enabling it from the Availability Group Dashboard, you can browse it from the SSMS similar to the previous latency reports. Take into consideration that, the large latency time indicates that the Primary replica is waiting a long time for the Secondary replicas to commit the sent transactions, as shown below: