La durabilidad retrasada es una característica de última hora pero interesante en SQL Server 2014; el tono de ascensor de alto nivel de la característica es, simplemente:
- "Cambia durabilidad por rendimiento".
Algunos antecedentes primero. De forma predeterminada, SQL Server usa un registro de escritura anticipada (WAL), lo que significa que los cambios se escriben en el registro antes de que se puedan confirmar. En sistemas donde las escrituras del registro de transacciones se convierten en el cuello de botella y donde existe una tolerancia moderada a la pérdida de datos , ahora tiene la opción de suspender temporalmente el requisito de esperar el vaciado y el reconocimiento del registro. Esto sucede literalmente para quitar la D de ACID, al menos para una pequeña parte de los datos (más sobre esto más adelante).
Ya haces este sacrificio ahora. En el modo de recuperación completa, siempre existe algún riesgo de pérdida de datos, solo se mide en términos de tiempo en lugar de tamaño. Por ejemplo, si realiza una copia de seguridad del registro de transacciones cada cinco minutos, podría perder hasta poco menos de 5 minutos de datos si ocurriera algo catastrófico. No estoy hablando de una conmutación por error simple aquí, pero digamos que el servidor literalmente se incendia o alguien tropieza con el cable de alimentación:la base de datos puede ser irrecuperable y es posible que tenga que volver al punto en el tiempo de la última copia de seguridad del registro. . Y eso suponiendo que incluso esté probando sus copias de seguridad restaurándolas en algún lugar; en caso de una falla crítica, es posible que no tenga el punto de recuperación que cree que tiene. Tendemos a no pensar en este escenario, por supuesto, porque nunca esperamos cosas malas™ que suceda.
Cómo funciona
La durabilidad retrasada permite que las transacciones de escritura continúen ejecutándose como si el registro se hubiera vaciado en el disco; en realidad, las escrituras en el disco se han agrupado y diferido, para ser manejadas en segundo plano. La transacción es optimista; asume que el vaciado de registro será ocurrir. El sistema usa un fragmento de 60 KB de búfer de registro e intenta vaciar el registro en el disco cuando este bloque de 60 KB está lleno (a más tardar, puede suceder y sucederá con frecuencia antes de eso). Puede establecer esta opción a nivel de base de datos, a nivel de transacción individual o, en el caso de procedimientos compilados de forma nativa en In-Memory OLTP, a nivel de procedimiento. La configuración de la base de datos gana en caso de conflicto; por ejemplo, si la base de datos está deshabilitada, simplemente se ignorará el intento de confirmar una transacción usando la opción retrasada, sin mensaje de error. Además, algunas transacciones siempre son totalmente duraderas, independientemente de la configuración de la base de datos o la configuración de confirmación; por ejemplo, transacciones del sistema, transacciones entre bases de datos y operaciones relacionadas con FileTable, seguimiento de cambios, captura de datos modificados y replicación.
A nivel de base de datos, puede utilizar:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Si lo establece en ALLOWED , esto significa que cualquier transacción individual puede usar Durabilidad Retrasada; FORCED significa que todas las transacciones que pueden usar la Durabilidad Retrasada lo harán (las excepciones anteriores siguen siendo relevantes en este caso). Es probable que desee utilizar ALLOWED en lugar de FORCED – pero este último puede ser útil en el caso de una aplicación existente en la que desea utilizar esta opción en todo momento y también minimizar la cantidad de código que debe tocarse. Una cosa importante a tener en cuenta sobre ALLOWED es que las transacciones totalmente duraderas pueden tener que esperar más tiempo, ya que forzarán primero el vaciado de cualquier transacción duradera retrasada.
En el nivel de transacción, puede decir:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Y en un procedimiento compilado de forma nativa de OLTP en memoria, puede agregar la siguiente opción a BEGIN ATOMIC bloque:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Una pregunta común es sobre qué sucede con la semántica de bloqueo y aislamiento. Nada cambia, de verdad. El bloqueo y el bloqueo aún ocurren, y las transacciones se comprometen de la misma manera y con las mismas reglas. La única diferencia es que, al permitir que se produzca la confirmación sin esperar a que el registro se vacíe en el disco, los bloqueos relacionados se liberan mucho antes.
Cuándo debe usarlo
Además del beneficio que obtiene al permitir que las transacciones continúen sin esperar a que ocurra la escritura del registro, también obtiene menos escrituras de registros de mayor tamaño. Esto puede funcionar muy bien si su sistema tiene una alta proporción de transacciones que en realidad son menores a 60 KB, y particularmente cuando el disco de registro es lento (aunque encontré beneficios similares en SSD y HDD tradicional). No funciona tan bien si sus transacciones son, en su mayor parte, mayores de 60 KB, si suelen ser de larga duración o si tiene un alto rendimiento y alta simultaneidad. Lo que puede suceder aquí es que puede llenar todo el búfer de registro antes de que finalice el vaciado, lo que solo significa transferir sus esperas a un recurso diferente y, en última instancia, no mejorar el rendimiento percibido por los usuarios de la aplicación.
En otras palabras, si su registro de transacciones no es actualmente un cuello de botella, no active esta función. ¿Cómo puede saber si su registro de transacciones es actualmente un cuello de botella? El primer indicador sería alto WRITELOG espera, particularmente cuando se combina con PAGEIOLATCH_** . Paul Randal (@PaulRandal) tiene una gran serie de cuatro partes sobre la identificación de problemas en el registro de transacciones, así como la configuración para un rendimiento óptimo:
- Recortar la grasa del registro de transacciones
- Recortar más grasa del registro de transacciones
- Problemas de configuración del registro de transacciones
- Supervisión del registro de transacciones
Consulte también esta publicación de blog de Kimberly Tripp (@KimberlyLtripp), 8 pasos para mejorar el rendimiento del registro de transacciones y la publicación de blog del equipo SQL CAT, Diagnóstico de problemas de rendimiento del registro de transacciones y límites del administrador de registros.
Esta investigación puede llevarlo a la conclusión de que vale la pena analizar la Durabilidad retrasada; puede que no Probar su carga de trabajo será la forma más confiable de saberlo con seguridad. Como muchas otras adiciones en versiones recientes de SQL Server (*cough* Hekaton ), esta función NO está diseñada para mejorar todas las cargas de trabajo y, como se indicó anteriormente, en realidad puede empeorar algunas cargas de trabajo. Consulte esta publicación de blog de Simon Harvey para conocer otras preguntas que debe hacerse sobre su carga de trabajo para determinar si es factible sacrificar algo de durabilidad para lograr un mejor rendimiento.
Posibilidad de pérdida de datos
Voy a mencionar esto varias veces, y agregaré énfasis cada vez que lo haga:Debe ser tolerante con la pérdida de datos . Con un disco de buen rendimiento, lo máximo que debe esperar perder en una catástrofe, o incluso en un apagado planificado y correcto, es hasta un bloque completo (60 KB). Sin embargo, en el caso de que su subsistema de E/S no pueda seguir el ritmo, es posible que pierda tanto como el búfer de registro completo (~7 MB).
Para aclarar, de la documentación (énfasis mío):
Para una durabilidad retrasada, no hay diferencia entre un apagado inesperado y un apagado/reinicio esperado de SQL Server . Al igual que los eventos catastróficos, debe planificar la pérdida de datos . En un apagado/reinicio planificado, algunas transacciones que no se han escrito en el disco pueden guardarse primero en el disco, pero no debe planificarlo. Planifique como si un apagado/reinicio, ya sea planificado o no, perdiera los datos al igual que un evento catastrófico.Por lo tanto, es muy importante que sopese el riesgo de pérdida de datos con su necesidad de aliviar los problemas de rendimiento del registro de transacciones. Si administra un banco o algo relacionado con el dinero, puede ser mucho más seguro y apropiado para usted mover su registro a un disco más rápido que tirar los dados con esta función. Si está tratando de mejorar el tiempo de respuesta en su aplicación Web Gamerz Chat Room, tal vez el riesgo sea menos grave.
Puede controlar este comportamiento hasta cierto punto para minimizar el riesgo de pérdida de datos. Puede forzar que todas las transacciones duraderas retrasadas se vacíen en el disco de una de dos maneras:
- Comprometer cualquier transacción totalmente duradera.
- Llamar a
sys.sp_flush_logmanualmente.
Esto le permite volver a controlar la pérdida de datos en términos de tiempo, en lugar de tamaño; podría programar el lavado cada 5 segundos, por ejemplo. Pero querrás encontrar tu punto ideal aquí; enjuagar con demasiada frecuencia puede compensar el beneficio de durabilidad retardada en primer lugar. En cualquier caso, deberá ser tolerante a la pérdida de datos , incluso si solo vale
Uno pensaría que CHECKPOINT podría ayudar aquí, pero esta operación en realidad no garantiza técnicamente que el registro se vacíe en el disco.
Interacción con HA/DR
Quizás se pregunte cómo funciona Delayed Durablity con funciones de HA/DR, como el trasvase de registros, la replicación y los grupos de disponibilidad. Con la mayoría de estos funciona sin cambios. El envío de registros y la replicación reproducirán los registros que se han reforzado, por lo que existe el mismo potencial de pérdida de datos. Con los AG en modo asíncrono, no estamos esperando el reconocimiento secundario de todos modos, por lo que se comportará igual que hoy. Sin embargo, con synchronous, no podemos confirmar en el principal hasta que la transacción se confirme y se proteja en el registro remoto. Incluso en ese escenario, podemos tener algún beneficio localmente al no tener que esperar a que se escriba el registro local, todavía tenemos que esperar la actividad remota. Entonces, en ese escenario, hay menos beneficio, y potencialmente ninguno; excepto quizás en el raro escenario donde el disco de registro del primario es muy lento y el disco de registro del secundario es muy rápido. Sospecho que las mismas condiciones son válidas para la duplicación sincronizada/asincrónica, pero no obtendrá ningún compromiso oficial de mi parte sobre cómo funciona una característica nueva brillante con una obsoleta. :-)
Observaciones de rendimiento
Esta no sería una gran publicación aquí si no mostrara algunas observaciones reales de rendimiento. Configuré 8 bases de datos para probar los efectos de dos patrones de carga de trabajo diferentes con los siguientes atributos:
- Modelo de recuperación:simple frente a completo
- Ubicación de registro:SSD frente a HDD
- Durabilidad:retardada frente a totalmente duradera
Soy muy, muy, muy perezoso eficiente en este tipo de cosas. Como quiero evitar repetir las mismas operaciones dentro de cada base de datos, creé la siguiente tabla temporalmente en model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Luego construí un conjunto de comandos SQL dinámicos para construir estas 8 bases de datos, en lugar de crear las bases de datos individualmente y luego modificar la configuración:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Siéntase libre de ejecutar este código usted mismo (con el EXEC todavía comentado) para ver que esto crearía 4 bases de datos con Durabilidad retrasada desactivada (dos en recuperación COMPLETA, dos en SIMPLE, una de cada una con inicio de sesión en disco lento y una de cada una con inicio de sesión en SSD). Repita ese patrón para 4 bases de datos con Durabilidad retrasada FORZADA:hice esto para simplificar el código en la prueba, en lugar de reflejar lo que haría en la vida real (donde probablemente querría tratar algunas transacciones como críticas y otras como, bueno, menos que crítico).
Para verificar la cordura, ejecuté la siguiente consulta para asegurarme de que las bases de datos tuvieran la matriz de atributos correcta:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Resultados:
| nombre | modelo_de_recuperación | durabilidad_retrasada | disco_de_registro |
|---|---|---|---|
| dd1 | COMPLETO | FORZADO | SSD |
| dd2 | SIMPLE | FORZADO | SSD |
| dd3 | COMPLETO | FORZADO | HDD |
| dd4 | SIMPLE | FORZADO | HDD |
| dd5 | COMPLETO | DESHABILITADO | SSD |
| dd6 | SIMPLE | DESHABILITADO | SSD |
| dd7 | COMPLETO | DESHABILITADO | HDD |
| dd8 | SIMPLE | DESHABILITADO | HDD |
Configuración relevante de las 8 bases de datos de prueba
También ejecuté la prueba limpiamente varias veces para asegurarme de que un archivo de datos de 1 GB y un archivo de registro de 1 GB serían suficientes para ejecutar todo el conjunto de cargas de trabajo sin introducir ningún evento de crecimiento automático en la ecuación. Como práctica recomendada, rutinariamente hago todo lo posible para garantizar que los sistemas de los clientes tengan suficiente espacio asignado (y alertas adecuadas integradas) para que nunca ocurra ningún evento de crecimiento en un momento inesperado. En el mundo real, sé que esto no siempre sucede, pero es ideal.
Configuré el sistema para ser monitoreado con SQL Sentry; esto me permitiría mostrar fácilmente la mayoría de las métricas de rendimiento que quería resaltar. Pero también creé una tabla temporal para almacenar métricas por lotes, incluida la duración y resultados muy específicos de sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Esto me permitiría registrar la hora de inicio y finalización de cada lote individual y medir los deltas en el DMV entre la hora de inicio y la hora de finalización (solo confiable en este caso porque sé que soy el único usuario en el sistema).
Muchas transacciones pequeñas
La primera prueba que quería realizar era muchas transacciones pequeñas. Para cada base de datos, quería terminar con 500 000 lotes separados de una sola inserción cada uno:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Recuerda, trato de ser perezoso eficiente en este tipo de cosas. Entonces, para generar el código para las 8 bases de datos, ejecuté esto:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ejecuté esta prueba y luego miré el #Metrics tabla con la siguiente consulta:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Esto arrojó los siguientes resultados (y confirmé a través de múltiples pruebas que los resultados eran consistentes):
| base de datos | escribe | bytes | bytes/escritura | io_stall_ms | hora_de_inicio | hora_fin | duración (segundos) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418,56 | 2740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8246 | 262,254,592 | 31.803,85 | 3996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8055 | 261.688.320 | 32.487,68 | 4231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500.012 | 526,448,640 | 1052,87 | 35.593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1051,71 | 35.435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500.015 | 526,120,448 | 1052,20 | 50.857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | 133 |
Transacciones pequeñas:duración y resultados de sys.dm_io_virtual_file_stats
Definitivamente algunas observaciones interesantes aquí:
- El número de operaciones de escritura individuales fue muy pequeño para las bases de datos de durabilidad retardada (~60X para las tradicionales).
- El número total de bytes escritos se redujo a la mitad utilizando la durabilidad retardada (supongo que porque todas las escrituras en el caso tradicional contenían mucho espacio desperdiciado).
- La cantidad de bytes por escritura fue mucho mayor para la durabilidad retrasada. Esto no fue demasiado sorprendente, ya que el propósito de la función es agrupar las escrituras en lotes más grandes.
- La duración total de las paradas de E/S fue volátil, pero aproximadamente un orden de magnitud menor para la durabilidad retrasada. Las paradas en transacciones totalmente duraderas eran mucho más sensibles al tipo de disco.
- Si algo no te ha convencido hasta ahora, la columna de duración es muy reveladora. Los lotes totalmente duraderos que tardan dos minutos o más se reducen casi a la mitad.
Las columnas de hora de inicio/finalización me permitieron centrarme en el panel de Performance Advisor para el período preciso en el que ocurrieron estas transacciones, donde podemos dibujar una gran cantidad de indicadores visuales adicionales:
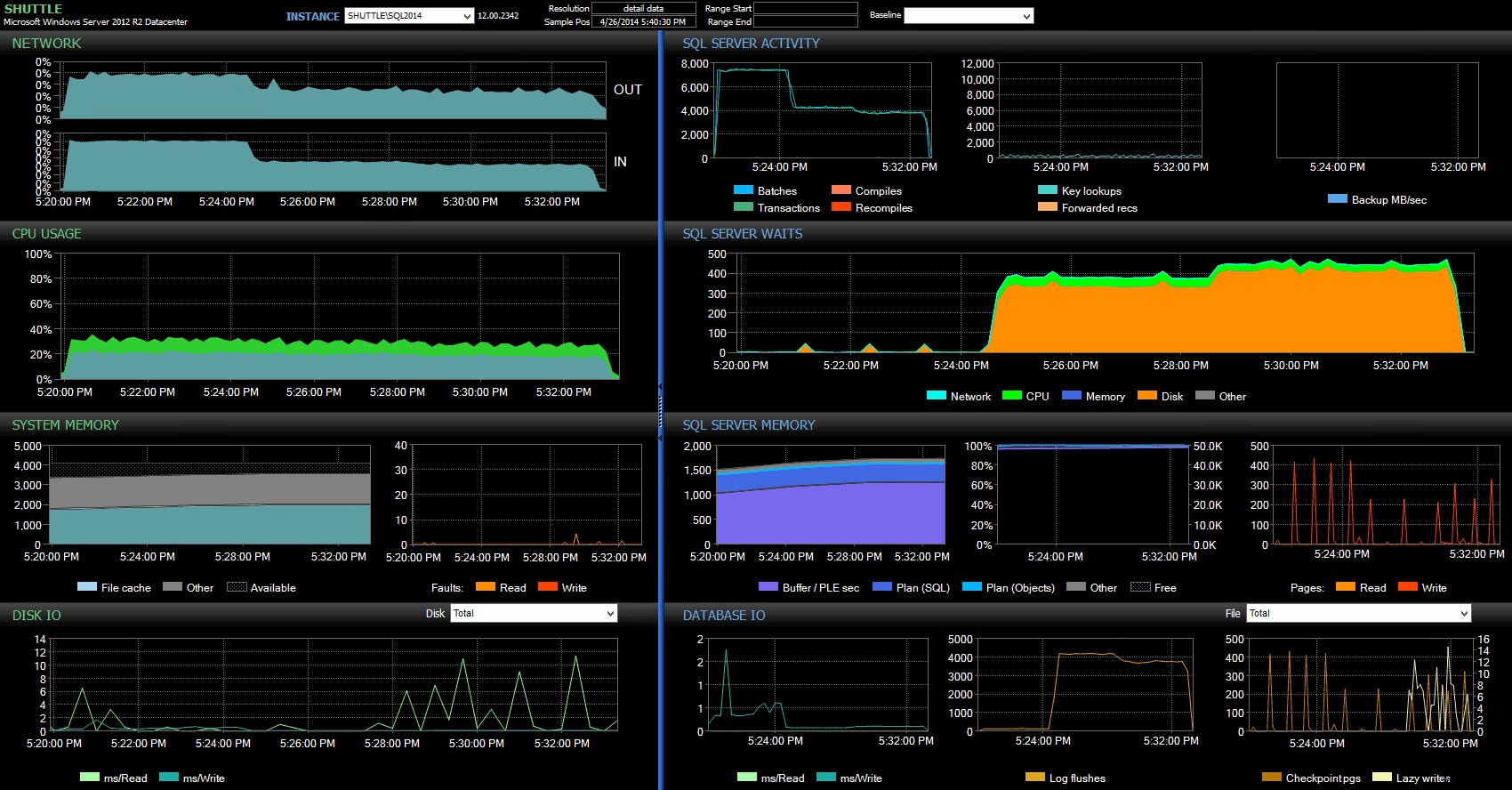
Panel de SQL Sentry:haga clic para ampliar
Más observaciones aquí:
- En varios gráficos, puede ver claramente cuándo se hizo cargo la porción del lote sin durabilidad retrasada (~5:24:32 p. m.).
- No hay un impacto observable en la CPU o la memoria cuando se usa la durabilidad retrasada.
- Puede ver un tremendo impacto en los lotes/transacciones por segundo en el primer gráfico en Actividad de SQL Server.
- Las esperas de SQL Server se dispararon cuando comenzaron las transacciones totalmente duraderas. Estos estaban compuestos casi exclusivamente por
WRITELOGespera, con una pequeña cantidad dePAGEIOLOATCH_EXyPAGEIOLATCH_UPespera la buena medida. - El número total de vaciados de registro durante las operaciones de durabilidad retardada fue bastante pequeño (bajo 100 s/seg), mientras que saltó a más de 4000/seg para el comportamiento tradicional (y ligeramente inferior para la duración de HDD de la prueba).
Menos transacciones, más grandes
Para la próxima prueba, quería ver qué sucedería si realizáramos menos operaciones, pero me aseguré de que cada declaración afectara una mayor cantidad de datos. Quería que este lote se ejecutara en cada base de datos:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Así que nuevamente usé el método perezoso para producir 8 copias de este script, una por base de datos:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Ejecuté este lote, luego cambié la consulta contra #Metrics arriba para ver la segunda prueba en lugar de la primera. Los resultados:
| base de datos | escribe | bytes | bytes/escritura | io_stall_ms | hora_de_inicio | hora_fin | duración (segundos) |
|---|---|---|---|---|---|---|---|
| dd1 | 20.970 | 1,271,911,936 | 60.653,88 | 12.577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20.997 | 1,272,145,408 | 60.587,00 | 14.698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20.973 | 1,272,982,016 | 60.696,22 | 12.085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20.958 | 1,272,064,512 | 60.695,89 | 11.795 | 143 | ||
| dd5 | 30.138 | 1,282,231,808 | 42.545,35 | 7402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30.138 | 1,282,260,992 | 42.546,31 | 7806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30,129 | 1,281,575,424 | 42.536,27 | 9888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30,130 | 1,281,449,472 | 42.530,68 | 11.452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Transacciones más grandes:duración y resultados de sys.dm_io_virtual_file_stats
Esta vez, el impacto de la durabilidad retrasada es mucho menos perceptible. Vemos un número ligeramente menor de operaciones de escritura, con un número ligeramente mayor de bytes por escritura, con el total de bytes escritos casi idénticos. En este caso, vemos que las paradas de E/S son más altas para la durabilidad retardada, y esto probablemente explica el hecho de que las duraciones también fueron casi idénticas.
Desde el panel de Performance Advisor, encontramos algunas similitudes con la prueba anterior y también algunas diferencias marcadas:
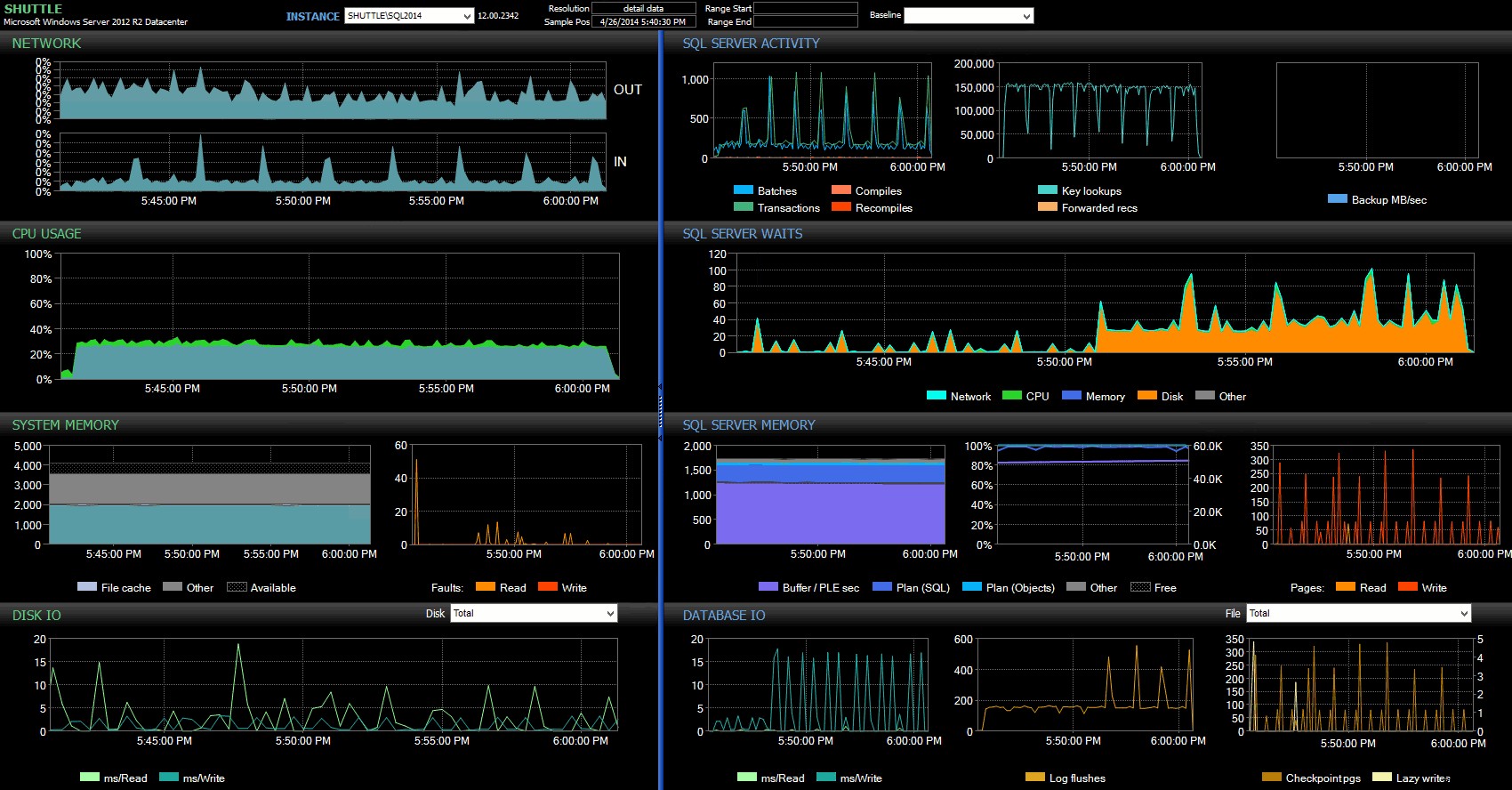
Panel de SQL Sentry:haga clic para ampliar
Una de las grandes diferencias a señalar aquí es que el delta en las estadísticas de espera no es tan pronunciado como en la prueba anterior:todavía hay una frecuencia mucho mayor de WRITELOG espera los lotes completamente duraderos, pero no se acerca a los niveles observados con las transacciones más pequeñas. Otra cosa que puede detectar de inmediato es que el impacto observado anteriormente en los lotes y transacciones por segundo ya no está presente. Y, por último, si bien hay más vaciados de registro con transacciones totalmente duraderas que cuando se retrasan, esta disparidad es mucho menos pronunciada que con las transacciones más pequeñas.
Conclusión
Debe quedar claro que hay ciertos tipos de cargas de trabajo que pueden beneficiarse enormemente de la durabilidad retrasada, siempre que, por supuesto, tenga tolerancia a la pérdida de datos . Esta función no está restringida a OLTP en memoria, está disponible en todas las ediciones de SQL Server 2014 y se puede implementar con pocos o ningún cambio en el código. Sin duda, puede ser una técnica poderosa si su carga de trabajo puede soportarla. Pero nuevamente, deberá probar su carga de trabajo para asegurarse de que se beneficiará de esta función y también considerar seriamente si esto aumenta su exposición al riesgo de pérdida de datos.
Aparte, esto puede parecerle a la multitud de SQL Server una idea nueva y fresca, pero en realidad Oracle lo introdujo como "Confirmación asíncrona" en 2006 (ver COMMIT WRITE ... NOWAIT como se documenta aquí y se publicó en un blog en 2007). Y la idea en sí ha existido durante casi 3 décadas; véase la breve crónica de Hal Berenson sobre su historia.
La próxima vez
Una idea que he barajado es tratar de mejorar el rendimiento de tempdb forzando Durabilidad Retrasada allí. Una propiedad especial de tempdb Lo que lo convierte en un candidato tan tentador es que es transitorio por naturaleza:cualquier cosa en tempdb está diseñado, explícitamente, para ser arrojado a raíz de una amplia variedad de eventos del sistema. Estoy diciendo esto ahora sin tener idea de si hay una forma de carga de trabajo en la que funcionará bien; pero planeo probarlo, y si encuentro algo interesante, puede estar seguro de que lo publicaré aquí.



