En un artículo anterior, exploramos los requisitos de índice de SQL Server y las consideraciones de rendimiento. Cuando se trata del rendimiento de la base de datos, el ajuste del rendimiento es, sin duda, una de las funciones más importantes y complejas. Consta de muchas áreas diferentes, como la optimización de consultas SQL, el ajuste de índices y el ajuste de recursos del sistema, todo lo cual debe realizarse correctamente para recuperar datos rápidamente.
Hay varias áreas importantes a considerar cuando se trata de índices de SQL Server, ya que pueden tener un impacto significativo tanto en sus esfuerzos de ajuste de rendimiento como en el rendimiento general de la base de datos. A continuación se presentan algunos detalles sobre cada uno y las funciones críticas que desempeñan.
Mejores prácticas de índices de SQL Server
1. Comprenda cómo el diseño de la base de datos afecta los índices de SQL Server
Los requisitos de indexación varían entre las bases de datos de procesamiento de transacciones en línea (OLTP) y de procesamiento analítico en línea (OLAP).
En una base de datos OLTP, los usuarios realizan operaciones frecuentes de lectura y escritura, insertando nuevos datos y modificando los existentes. Utilizan consultas de lenguaje de manipulación de datos (Insertar, Actualizar, Eliminar) junto con declaraciones Select para la recuperación y modificación de datos. Para las bases de datos OLTP, es mejor crear índices en la columna Seleccionada de una tabla. Múltiples índices pueden tener un impacto negativo en el rendimiento y ejercer presión sobre los recursos del sistema. En su lugar, se recomienda crear la cantidad mínima de índices que puedan cumplir con sus requisitos de indexación. En las bases de datos OLAP, por otro lado, utiliza principalmente declaraciones Select para recuperar datos para fines analíticos adicionales. En este caso, puede agregar más índices con varias columnas clave por índice. También puede aprovechar los índices de almacén de columnas para una recuperación de datos más rápida en consultas de almacenamiento de datos
2. Cree índices para sus requisitos de carga de trabajo
Al crear una nueva tabla en su base de datos, no solo agregue índices a ciegas. A veces, los desarrolladores colocan un índice agrupado y algunos índices no agrupados sin buscar las consultas que usan esos índices. Puede haber un índice que no satisfaga el requisito del optimizador de consultas; por lo tanto, debe analizar adecuadamente su carga de trabajo y consultas SQL (procedimientos almacenados, funciones, vistas y consultas ad-hoc). Puede capturar la carga de trabajo mediante SQL Profiler, eventos extendidos y vistas de administración dinámica, y luego crear índices para optimizar las consultas que consumen muchos recursos.
3. Cree índices para las consultas más utilizadas y utilizadas con mayor frecuencia
Es importante agrupar las cargas de trabajo para las consultas más utilizadas en su sistema. Al crear los mejores índices para estas consultas, ejercerá la menor cantidad de esfuerzo en su sistema.
4. Aplique las mejores prácticas de columna de clave de índice de SQL Server
Dado que puede tener varias columnas en una tabla, aquí hay algunas consideraciones para las columnas de clave de índice.
- Las columnas con texto, imagen, ntext, varchar(max), nvarchar(max) y varbinary(max) no se pueden usar en las columnas de clave de índice.
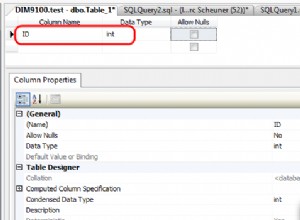
- Se recomienda utilizar un tipo de datos entero en la columna de clave de índice. Tiene un requisito de espacio bajo y funciona de manera eficiente. Debido a esto, querrá crear la columna de clave principal, generalmente en un tipo de datos entero.
- Solo puede usar el tipo de datos XML en un índice XML.
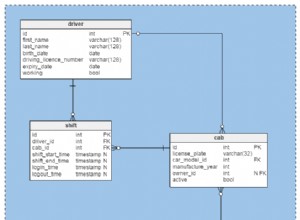
- Debe considerar crear una clave principal para la columna con valores únicos. Si una tabla no tiene columnas de valores únicos, puede definir una columna de identidad para un tipo de datos entero. Una clave principal también crea un índice agrupado para la distribución de filas.
- Puede considerar una columna con los valores Unique y Not NULL como un candidato clave de índice útil.
- Debe crear un índice basado en los predicados de la cláusula Where. Por ejemplo, puede considerar las columnas utilizadas en la cláusula Where, las uniones SQL, los predicados like, order by, group by, etc.
- Debe unir las tablas de forma que se reduzca el número de filas para el resto de la consulta. Esto ayudará al optimizador de consultas a preparar el plan de ejecución con recursos mínimos del sistema.
- Si usa varias columnas para una clave de índice, también es esencial considerar su posición en la clave de índice.
- También debería considerar el uso de columnas incluidas en sus índices.
5. Analice la distribución de datos de sus columnas de índice de SQL Server
Debe examinar la distribución de datos en las columnas de clave de índice de SQL Server. Una columna con valores no únicos puede provocar un retraso en la recuperación de los datos y dar como resultado una transacción de ejecución prolongada. Puede analizar la distribución de datos usando el histograma en estadísticas.
6. Usar orden de clasificación de datos
También debe considerar los requisitos de clasificación de datos en sus consultas e índices. De forma predeterminada, SQL Server ordena los datos en orden ascendente en un índice. Suponga que crea un índice en orden ascendente, pero sus consultas usan la cláusula Ordenar por para ordenar los datos en orden descendente.
Por ejemplo, observe el plan de ejecución real de la siguiente consulta.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
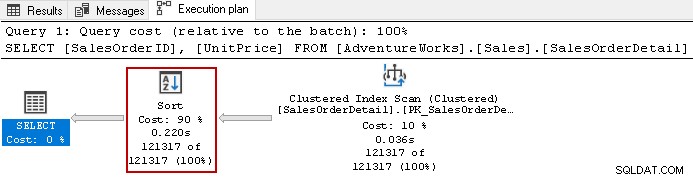
Utiliza el operador de clasificación costoso con un costo total del 90 % en esta consulta. Decidimos construir un índice no agrupado en [UnitPrice] y [SalesOrderID]. Utiliza un orden de clasificación predeterminado para ambas columnas en el índice.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Volvimos a ejecutar la instrucción Select y el optimizador de consultas todavía usa el operador de clasificación. Puede usar el índice no agrupado pero ordena los datos para preparar el resultado.
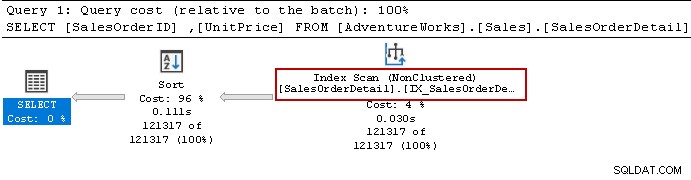
Recreemos el índice usando la siguiente consulta. Esta vez ordena los datos en orden descendente para [Unitprice] en la definición del índice.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
Ahora no requiere ningún operador de clasificación porque el índice satisface los requisitos de la consulta.
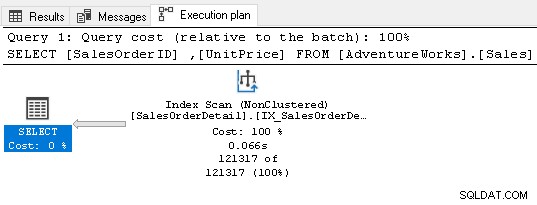
7. Use claves foráneas para su índice de SQL Server
Debe crear un índice en las columnas de claves externas. Es recomendable crear un índice agrupado en la clave externa para mejorar el rendimiento de las consultas.
8. Tenga en cuenta las consideraciones de almacenamiento de índices de SQL Server
El almacenamiento de índices también es un aspecto útil a considerar. SQL Server crea todos los índices en el mismo grupo de archivos de la tabla. Puede considerar un grupo de archivos separado para los índices y separar el archivo físico en un disco separado. Esto aumentará el rendimiento y el rendimiento de E/S.
De manera similar, puede usar la partición de tablas para segregar datos en varios discos y grupos de archivos. Puede diseñar índices particionados para estas particiones de tablas para mejorar el acceso a datos simultáneos.
Otra opción es definir el FACTOR DE RELLENO al crear o reconstruir un índice. Un FACTOR DE RELLENO define el espacio libre en las páginas de datos del nodo hoja. Es útil para futuras inserciones de datos. Si sus datos son estáticos y no cambian con frecuencia, puede considerar un valor alto de FILLFACTOR. Por otro lado, para datos que cambian con frecuencia, puede dejar suficiente espacio para nuevas inserciones de datos.
9. Buscar índices faltantes
A veces, obtiene información sobre un índice de SQL Server que falta en el plan de ejecución de la consulta. También puede ejecutar las vistas de administración dinámica para encontrar estos índices que faltan. No debe crear estos índices a ciegas. Es simplemente una sugerencia del optimizador de consultas, pero no tiene en cuenta el índice existente ni los requisitos de su carga de trabajo. También puede incluir varias columnas en la definición del índice, así que revise estas sugerencias antes de implementarlo.
10. Cree siempre un índice agrupado antes que un índice no agrupado
Como pauta general, debe crear un índice agrupado antes de crear índices no agrupados. Si una tabla no tiene un índice, un índice no agrupado consta de identificadores de fila. Una vez que crea un índice agrupado, SQL Server necesita reconstruir estos índices no agrupados para que puedan apuntar a la clave del índice agrupado en lugar de a los identificadores de fila.
11. Supervise el mantenimiento del índice y actualice las estadísticas
A continuación hay varias áreas de mantenimiento para monitorear cuando se trata de índices de SQL Server.
- Eliminar la fragmentación del índice :debe revisar regularmente las fragmentaciones internas y externas, especialmente para las tablas de transacciones altas. Sus consultas pueden responder lentamente incluso si tiene índices adecuados para sus cargas de trabajo. Un índice muy fragmentado podría degradar el rendimiento porque requiere E/S adicional. Puede realizar una reorganización o reconstruir un índice en función de sus valores de fragmentación. Por lo general, debe reconstruir el índice si tiene una fragmentación superior al 30 % y reorganizarlo si tiene una fragmentación inferior al 30 %.
- Eliminar índices no utilizados: Siempre debe revisar los índices no utilizados (inactivos) en su base de datos porque el optimizador de consultas debe tenerlos en cuenta para cada consulta. Un índice no utilizado también consume almacenamiento y aumenta los gastos generales de mantenimiento.
- Actualizar estadísticas: Debe actualizar periódicamente las estadísticas incluso si ha establecido las estadísticas de actualización automática dentro de la configuración de su base de datos. El optimizador de consultas podría preparar un mal plan de ejecución si las estadísticas del índice no se actualizan. Puede programar un trabajo de agente para actualizar las estadísticas de SQL Server con un análisis completo fuera del horario laboral.
Puede consultar Mantenimiento del índice SQL para obtener más información sobre este tema.
Aplicación de mejores prácticas de índices de SQL Server
Aunque no siempre existe una forma sencilla de diseñar un índice de SQL Server óptimo, aplicar las recomendaciones especificadas en esta publicación lo ayudará a navegar por los diferentes requisitos de indexación que encontrará con cada tipo de base de datos y sus cargas de trabajo. Estas prácticas recomendadas ayudarán a optimizar sus índices para mejorar el rendimiento de la base de datos y garantizar un proceso de ajuste de rendimiento más fluido en el camino.