Los índices de SQL Server se utilizan para ayudar a recuperar datos más rápido y reducir los cuellos de botella que afectan a los recursos críticos. Los índices en una tabla de base de datos sirven como una técnica de optimización del rendimiento. Quizás se pregunte:¿cómo aumentan los índices el rendimiento de las consultas? ¿Hay cosas tales como buenos y malos índices? Supongamos que tiene una tabla con 50 columnas, ¿es una buena idea crear índices en cada una de las columnas? Si creamos varios índices, ¿ayuda a que las consultas SQL se ejecuten más rápido?
Todas son excelentes preguntas, pero antes de profundizar, es esencial saber por qué los índices pueden ser necesarios en primer lugar.
Imagina que visitas una biblioteca de la ciudad que tiene una colección de miles de libros. Está buscando un libro específico, pero ¿cómo lo encontrará? Si revisó cada libro, en cada estante, podría llevar días encontrarlo. Lo mismo se aplica a una base de datos cuando busca un registro de los millones de filas almacenadas en una tabla.
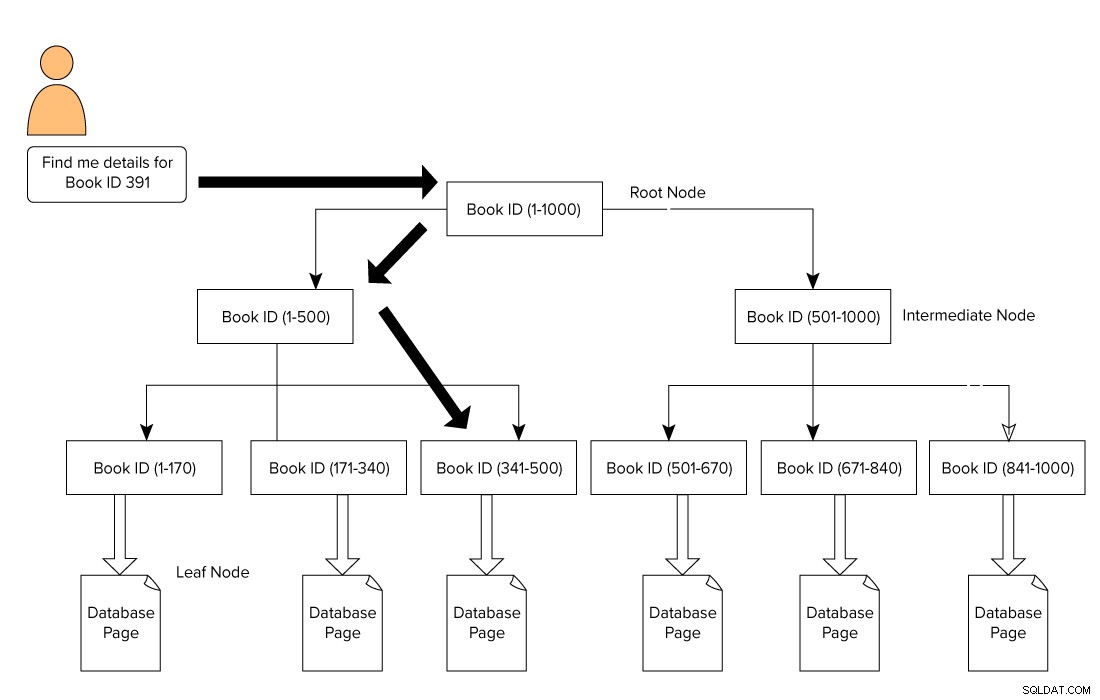
Un índice de SQL Server tiene la forma de un formato B-Tree que consta de un nodo raíz en la parte superior y un nodo hoja en la parte inferior. Para nuestro ejemplo de libros de la biblioteca, un usuario emite una consulta para buscar un libro con el ID 391. En este caso, el motor de consulta comienza a atravesar desde el nodo raíz y se mueve al nodo hoja.
Nodo Raíz –> Nodo Intermedio –> Nodo Hoja.
El motor de consultas busca la página de referencia en el nivel intermedio. En este ejemplo, el primer nodo intermedio consta de ID de libros del 1 al 500 y el segundo nodo intermedio consta del 501 al 1000.
En función del nodo intermedio, el motor de consultas atraviesa el árbol B para buscar el nodo intermedio correspondiente y el nodo hoja. Este nodo de hoja puede constar de datos reales o apuntar a la página de datos reales según el tipo de índice. En la imagen a continuación, vemos cómo recorrer el índice para buscar datos utilizando índices de SQL Server. En este caso, SQL Server no tiene que pasar por cada página, leerla y buscar un contenido de ID de libro específico.
Impactos de los índices en el rendimiento de SQL Server
En el ejemplo anterior de la biblioteca, examinamos los posibles impactos en el rendimiento del índice. Veamos el rendimiento de las consultas con y sin un índice.
Supongamos que necesitamos datos para [SalesOrderID] 56958 de la tabla [SalesOrderDetail_Demo].
SELECCIONE *
DE [AdventureWorks].[Sales].[SalesOrderDetail_Demo]
donde SalesOrderID=56958
Esta tabla no tiene índices. Una tabla sin índices se denomina tabla de montón en SQL Server.
Desde aquí, le gustaría ejecutar la declaración de selección anterior y ver el plan de ejecución real. Esta tabla tiene 121317 registros. Realiza un escaneo de la tabla, lo que significa que lee todas las filas de una tabla para encontrar el [SalesOrderID] específico.
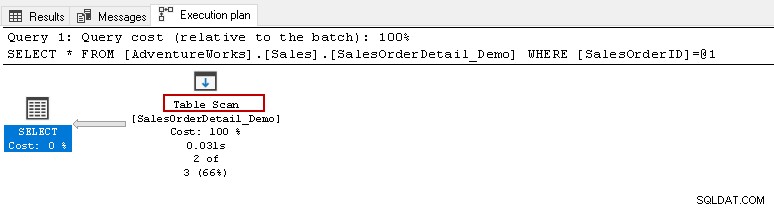
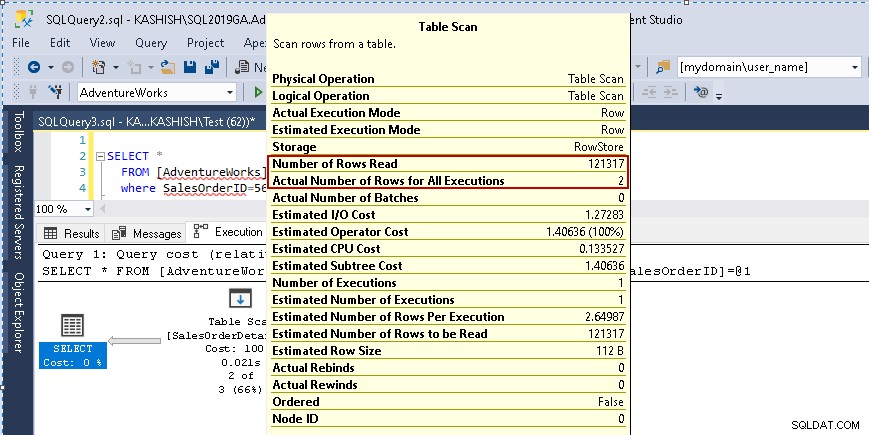
Cuando pasa el cursor sobre el ícono de Exploración de tabla, muestra que el conjunto de resultados real contiene 2 filas, pero para este propósito, lee todas las filas de esa tabla.
- Número de filas leídas:121317
- El número real de filas para la ejecución:2
Ahora, piense en una tabla con millones o miles de millones de filas. No es una buena práctica recorrer todos los registros de la tabla para filtrar algunas filas. En un extenso sistema de base de datos de procesamiento de transacciones en línea (OLTP), no utiliza los recursos del servidor (CPU, IO, memoria) de manera efectiva, por lo tanto, el usuario podría enfrentar problemas de rendimiento.
Ahora, ejecutemos la declaración de selección anterior con la tabla que tiene índices. Esta tabla tiene un índice agrupado de clave principal y dos índices no agrupados en las columnas [ProductID] y [rowguid]. Hablaremos más adelante sobre los diferentes tipos de índices en SQL Server.
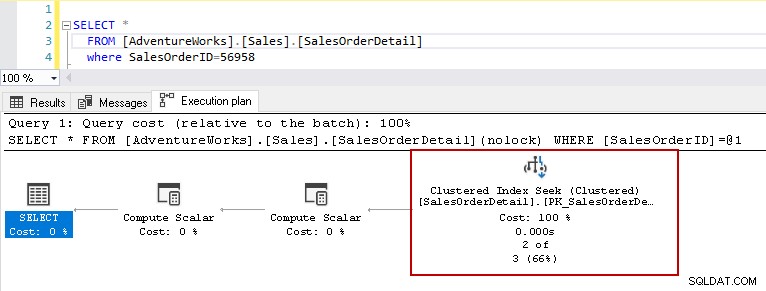
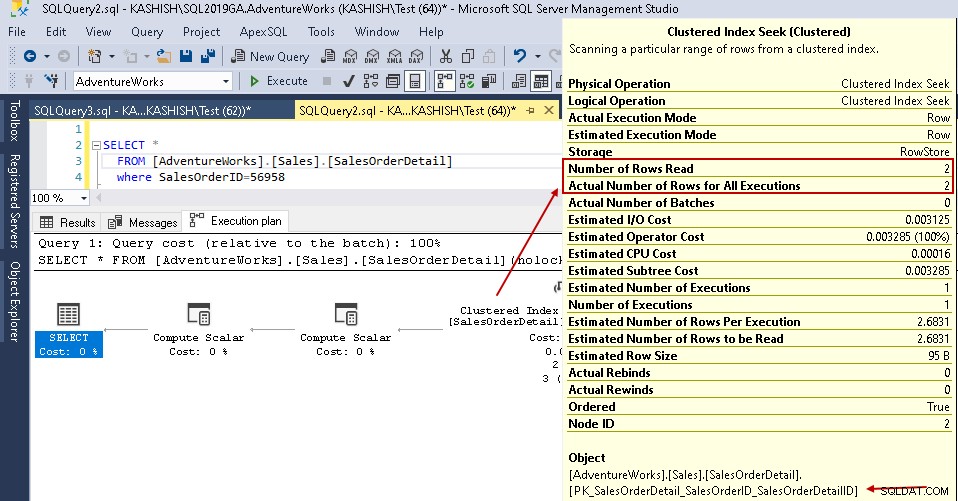
Ahora, si vuelve a ejecutar la declaración de selección con el mismo predicado, el plan de ejecución muestra el problema de rendimiento. El optimizador de consultas decide utilizar la búsqueda de índice agrupado en lugar de una exploración de índice agrupado.
En los detalles de búsqueda del índice agrupado, muestra que el optimizador de consultas lee con precisión las filas que proporcionó en el resultado.
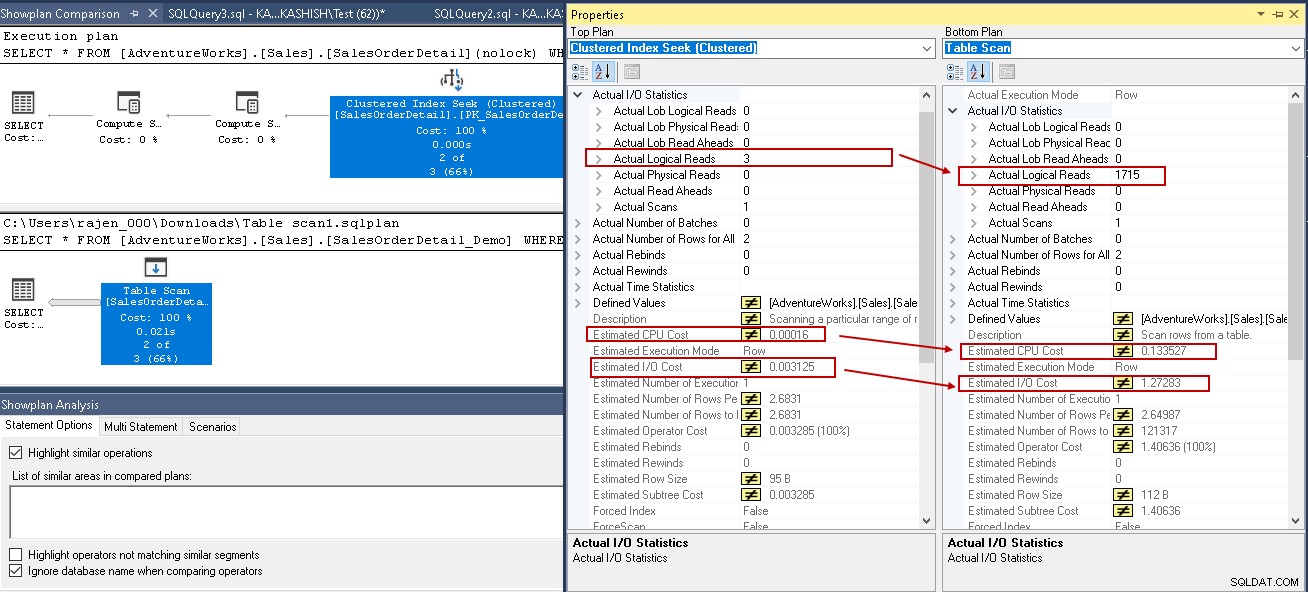
Para brindarle un análisis comparativo, comparemos el plan de ejecución con y sin un índice de SQL Server. Puede consultar el artículo Cómo comparar planes de ejecución de consultas en SQL Server 2016 de SQL Shack para obtener más información.
Para este ejemplo, mire los valores resaltados en la búsqueda del índice agrupado y el escaneo de la tabla:
- Lecturas lógicas:el motor de la base de datos de SQL Server lee una página del caché del búfer y provoca una lectura lógica. A continuación, vemos que las lecturas lógicas se reducen de 1715 a 3 una vez que crea el índice.
- El coste estimado de la CPU también se reduce de 0,133527 a 0,00016
- El costo estimado de IO cae de 1,27283 a 0,003125
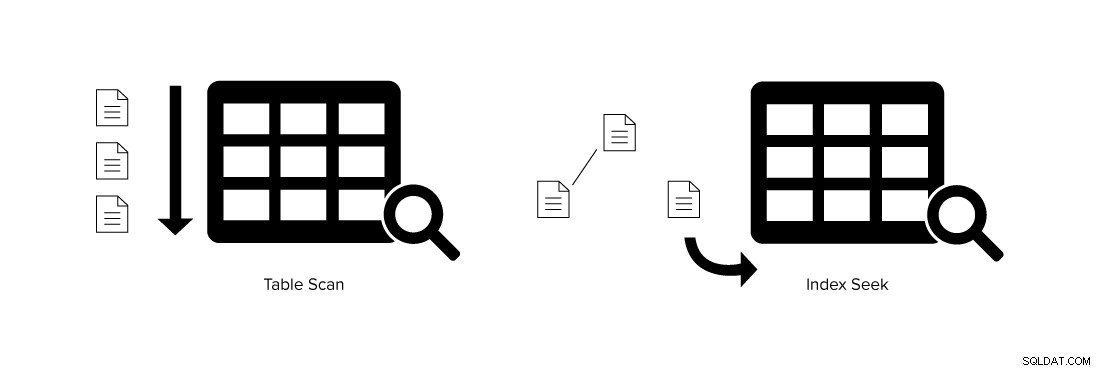
La siguiente imagen muestra una diferencia entre un escaneo de tabla y una búsqueda de índice.
Índices buenos (útiles) e índices malos en SQL Server
Como sugiere el nombre, un buen índice mejora el rendimiento de las consultas y minimiza la utilización de recursos. ¿Puede un índice reducir el rendimiento de las consultas en SQL Server? A veces creamos el índice en una columna específica, pero nunca se usa. Suponga que tiene un índice en una columna y realiza muchas inserciones y actualizaciones para esa columna. Para cada actualización, también se requiere la actualización del índice correspondiente. Si su carga de trabajo tiene más actividad de escritura y tiene muchos índices en una columna, ralentizaría el rendimiento general de sus consultas. Un índice no utilizado también puede causar un rendimiento lento para las declaraciones de selección. El optimizador de consultas utiliza estadísticas para crear un plan de ejecución. Lee todos los índices y su muestreo de datos y, en base a eso, crea un plan de ejecución de consultas optimizado. Puede realizar un seguimiento del uso de su índice mediante la vista de administración dinámica sys.dm_db_index_usage_stats y supervisar los recursos, como el análisis de usuarios, las búsquedas de usuarios y las búsquedas de usuarios.
Tipos de índices de SQL Server y consideraciones
SQL Server tiene dos índices principales:índices agrupados y no agrupados. Un índice agrupado almacena los datos reales en el nodo hoja del índice. Ordena físicamente los datos dentro de las páginas de datos según la clave del índice agrupado. SQL Server permite un índice agrupado por tabla. Puede unir varias columnas para crear una clave de índice agrupada. Un índice no agrupado es un índice lógico y tiene la columna de clave de índice que apunta a la clave de índice agrupado.
También podemos tener otros índices en SQL Server, como el índice XML, el índice de almacenamiento de columnas, el índice espacial, el índice de texto completo, el índice hash, etc.
Debe considerar los siguientes puntos antes de crear un índice en SQL Server:
- Carga de trabajo
- La columna en la que se requiere el índice
- Tamaño de la mesa
- Orden ascendente o descendente de los datos de la columna
- Orden de las columnas
- Tipo de índice
- Factor de relleno, índice de relleno y orden de clasificación de TempDB
Beneficios, implicaciones y recomendaciones del índice de SQL Server
Los índices en una base de datos pueden ser un arma de doble filo. Un útil índice de SQL Server mejora la consulta y el rendimiento del sistema sin afectar a las demás consultas. Por otro lado, si crea un índice sin ninguna preparación ni consideración, podría provocar una degradación del rendimiento, una recuperación de datos lenta y podría consumir recursos más críticos, como CPU, E/S y memoria. Los índices también aumentan las tareas de mantenimiento de su base de datos. Teniendo en cuenta estos factores, siempre es mejor probar un índice apropiado en un entorno de preproducción con la carga de trabajo equivalente de producción, luego analizar el rendimiento y decidir si es mejor implementarlo en una base de datos de producción. Hay muchas más recomendaciones que se deben tener en cuenta. Consulte mis 11 prácticas recomendadas de índice principales para obtener más información.