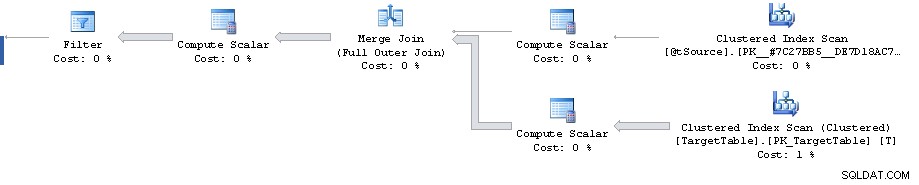
Los costos de los subárboles deben tomarse con cuidado (y especialmente cuando tiene grandes errores de cardinalidad). SET STATISTICS IO ON; SET STATISTICS TIME ON; la salida es un mejor indicador del rendimiento real.
La ordenación de fila cero no requiere el 87 % de los recursos. Este problema en su plan es uno de estimación de estadísticas. Los costos que se muestran en el plan real siguen siendo costos estimados. No los ajusta para tener en cuenta lo que realmente sucedió.
Hay un punto en el plan en el que un filtro reduce 1 911 721 filas a 0, pero las filas estimadas en el futuro son 1 860 310. A partir de entonces, todos los costos son falsos y culminan en el 87 % del costo estimado de clasificación de 3.348.560 filas.
El error de estimación de cardinalidad se puede reproducir fuera de Merge consultando el plan estimado para la Full Outer Join con predicados equivalentes (da la misma estimación de 1 860 310 filas).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Dicho esto, sin embargo, el plan hasta el filtro en sí parece bastante subóptimo. Está realizando un escaneo de índice agrupado completo cuando tal vez desee un plan con 2 búsquedas de rango de índice agrupado. Uno para recuperar la única fila que coincide con la clave principal de la combinación en el origen y el otro para recuperar la T.Key1 = @id rango (aunque tal vez esto es para evitar la necesidad de clasificar en orden de clave agrupada más adelante?)
Tal vez podría probar esta reescritura y ver si funciona mejor o peor
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;