Motivo del problema :
TOKEN El método en SSIS usa la implementación de strtok función en C++ . Reuní esta información mientras leía el libro Microsoft® SQL Server® 2012 Integration Services
. Se menciona como nota en la página 113 (¡Me gusta este libro! Mucha información interesante. ).
Busqué la implementación de strtok y encontré los siguientes enlaces.
INFORMACIÓN:strtok():Función C -- Suplemento de documentación - El ejemplo de código en este enlace muestra que la función ignora los caracteres delimitadores consecutivos.
Las respuestas a las siguientes preguntas SO señalan que strtok La función está diseñada para ignorar los delimitadores consecutivos.
Necesita saber cuándo no aparecen datos entre dos separadores de fichas usando strtok()
comportamiento de strtok_s con delimitadores consecutivos
Creo que el TOKEN y TOKENCOUNT las funciones funcionan según el diseño, pero si SSIS debe comportarse así podría ser una pregunta para el equipo de SSIS de Microsoft.
Publicación original:la sección anterior es una actualización:
Creé un paquete simple en SSIS 2012 basado en sus entradas de datos. Como describió en su pregunta, el TOKEN la función no se comporta como se esperaba. Estoy de acuerdo contigo en que la función no parece funcionar. Esta publicación no una respuesta a su problema original.
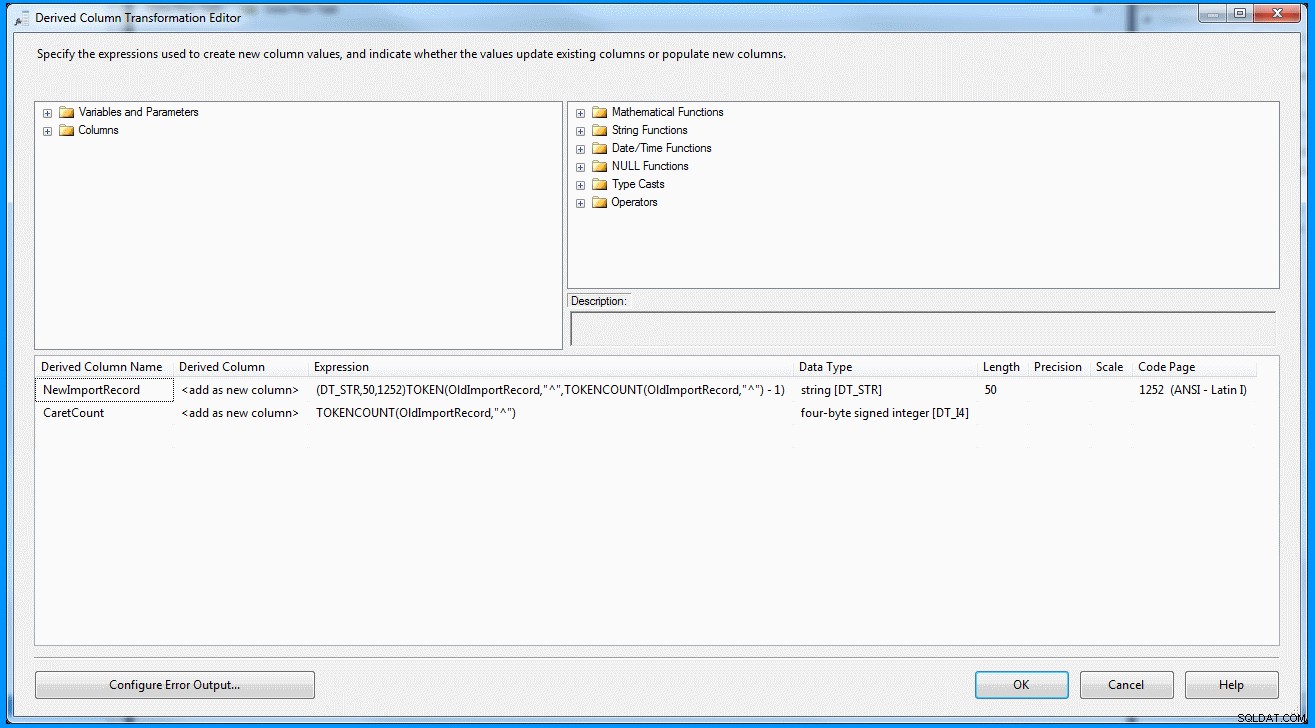
Aquí hay una forma alternativa de escribir la expresión de una manera relativamente más simple. Esto solo funcionará si el último segmento en su registro de entrada siempre tendrá un valor (digamos A1 , B2 , C3 etc.).
La expresión se puede reescribir como :
Esta declaración tomará el registro de entrada como parámetro, el delimitador (^) como segundo parámetro. El tercer parámetro calcula el número total de segmentos en los registros cuando se divide por el delimitador. Si tiene datos en el último segmento, tiene la garantía de tener dos segmentos. Luego puede restar 1 para obtener el penúltimo segmento.
(DT_STR,50,1252)TOKEN(OldImportRecord,"^",TOKENCOUNT(OldImportRecord,"^") - 1)
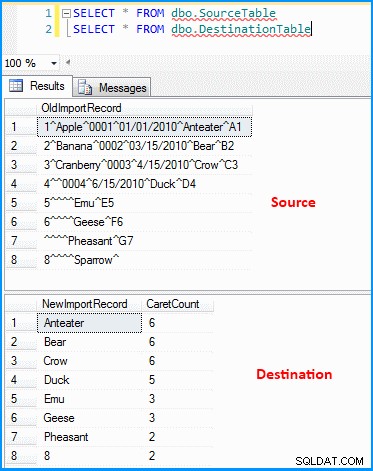
Creé un paquete simple con una tarea de flujo de datos. La fuente OLE DB recupera los datos y la transformación derivada analiza y divide los datos según la captura de pantalla a continuación. A continuación, la salida se inserta en la tabla de destino. Puede ver las tablas de origen y destino en la última captura de pantalla. La tabla de destino tiene dos columnas. La primera columna almacena los datos del penúltimo segmento y el recuento de segmentos se basa en el delimitador (que de nuevo no es correcto). Puede notar que el último registro no obtuvo los resultados correctos. Si el último registro no tuviera el valor 8 , entonces la expresión anterior fallará porque la expresión se evaluará como índice cero.
Espero que ayude a simplificar su expresión.
Si no tiene noticias de nadie más, recomendaría registrar este problema en sitio web de Microsoft Connect .
Crear tabla y completar scripts :
CREATE TABLE [dbo].[SourceTable](
[OldImportRecord] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DestinationTable](
[NewImportRecord] [varchar](50) NOT NULL,
[CaretCount] [int] NOT NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.SourceTable (OldImportRecord) VALUES
('1^Apple^0001^01/01/2010^Anteater^A1'),
('2^Banana^0002^03/15/2010^Bear^B2'),
('3^Cranberry^0003^4/15/2010^Crow^C3'),
('4^^0004^6/15/2010^Duck^D4'),
('5^^^^Emu^E5'),
('6^^^^Geese^F6'),
('^^^^Pheasant^G7'),
('8^^^^Sparrow^');
GO
Transformación de columna derivada dentro de la tarea de flujo de datos :
Datos en tablas de origen y destino :