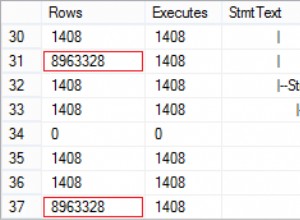
Establecer el valor adecuado para cur.arraysize podría ayudar a ajustar el rendimiento de búsqueda .Necesitas determinar el valor más adecuado para ello. El valor predeterminado es 100 . Se puede ejecutar un código con diferentes tamaños de matriz para determinar ese valor, como
arr=[100,1000,10000,100000,1000000]
for size in arr:
try:
cur.prefetchrows = 0
cur.arraysize = size
start = datetime.now()
cur.execute("SELECT * FROM mytable").fetchall()
elapsed = datetime.now() - start
print("Process duration for arraysize ", size," is ", elapsed, " seconds")
except Exception as err:
print("Memory Error ", err," for arraysize ", size)
y luego establezca como cur.arraysize =10000 antes de llamar a db_select de su código original