Su segunda consulta es de la forma:
q1 -- PK user_id
LEFT JOIN (...
GROUP BY user_id, t.tag
) AS q2
ON q2.user_id = q1.user_id
LEFT JOIN (...
GROUP BY user_id, c.category
) AS q3
ON q3.user_id = q1.user_id
GROUP BY -- group_concats
Los GROUP BY internos dan como resultado (user_id, t.tag) &(user_id, c.category) siendo claves/ÚNICOS. Aparte de eso, no me referiré a esos GROUP BY.
TL;RD Cuando se une (q1 JOIN q2) a q3 no está en una clave/ÚNICO de uno de ellos, por lo que para cada ID de usuario obtiene una fila para cada combinación posible de etiqueta y categoría. Entonces, las entradas finales de GROUP BY se duplican por (user_id, etiqueta) y por (user_id, categoría) y, de manera inapropiada, GROUP_CONCATs duplica etiquetas y categorías por user_id. Lo correcto sería (q1 JOIN q2 GROUP BY) JOIN (q1 JOIN q3 GROUP BY) en el que todas las uniones están en clave común/ÚNICO (user_id) &no hay agregación espuria. Aunque a veces puedes deshacer esa agregación espuria.
Un enfoque de INNER JOIN simétrico correcto:LEFT JOIN q1 &q2--1:many--then GROUP BY &GROUP_CONCAT (que es lo que hizo su primera consulta); luego por separado de manera similar LEFT JOIN q1 &q3--1:many--then GROUP BY &GROUP_CONCAT; luego INNER JOIN los dos resultados EN user_id--1:1.
Un enfoque correcto de subconsulta escalar simétrica:SELECCIONE los GROUP_CONCAT de q1 como subconsultas escalares cada uno con un GROUP BY.
Un enfoque LEFT JOIN acumulativo correcto:LEFT JOIN q1 &q2--1:many--then GROUP BY &GROUP_CONCAT; luego LEFT JOIN that &q3--1:many--then GROUP BY &GROUP_CONCAT.
Un enfoque correcto como su segunda consulta:primero LEFT JOIN q1 y q2--1:muchos. Luego, DEJÓ ÚNASE a eso y q3--muchos:1:muchos. Da una fila para cada combinación posible de una etiqueta y una categoría que aparece con un ID de usuario. Luego, después de GROUP BY usted GROUP_CONCAT, sobre pares duplicados (user_id, etiqueta) y pares duplicados (user_id, categoría). Es por eso que tiene elementos de lista duplicados. Pero agregar DISTINCT a GROUP_CONCAT da un resultado correcto. (Por wchiquito comentario de.)
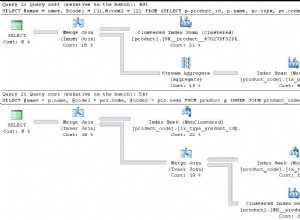
Lo que prefiere es, como de costumbre, una compensación de ingeniería para estar informado por planes y tiempos de consulta, por datos/uso/estadísticas reales. entrada y estadísticas para la cantidad esperada de duplicación), el tiempo de las consultas reales, etc. Un problema es si las filas adicionales del enfoque many:1:many JOIN compensan el ahorro de un GROUP BY.
-- cumulative LEFT JOIN approach
SELECT
q1.user_id, q1.user_name, q1.score, q1.reputation,
top_two_tags,
substring_index(group_concat(q3.category ORDER BY q3.category_reputation DESC SEPARATOR ','), ',', 2) AS category
FROM
-- your 1st query (less ORDER BY) AS q1
(SELECT
q1.user_id, q1.user_name, q1.score, q1.reputation,
substring_index(group_concat(q2.tag ORDER BY q2.tag_reputation DESC SEPARATOR ','), ',', 2) AS top_two_tags
FROM
(SELECT
u.id AS user_Id,
u.user_name,
coalesce(sum(r.score), 0) as score,
coalesce(sum(r.reputation), 0) as reputation
FROM
users u
LEFT JOIN reputations r
ON r.user_id = u.id
AND r.date_time > 1500584821 /* unix_timestamp(DATE_SUB(now(), INTERVAL 1 WEEK)) */
GROUP BY
u.id, u.user_name
) AS q1
LEFT JOIN
(
SELECT
r.user_id AS user_id, t.tag, sum(r.reputation) AS tag_reputation
FROM
reputations r
JOIN post_tag pt ON pt.post_id = r.post_id
JOIN tags t ON t.id = pt.tag_id
WHERE
r.date_time > 1500584821 /* unix_timestamp(DATE_SUB(now(), INTERVAL 1 WEEK)) */
GROUP BY
user_id, t.tag
) AS q2
ON q2.user_id = q1.user_id
GROUP BY
q1.user_id, q1.user_name, q1.score, q1.reputation
) AS q1
-- finish like your 2nd query
LEFT JOIN
(
SELECT
r.user_id AS user_id, c.category, sum(r.reputation) AS category_reputation
FROM
reputations r
JOIN post_category ct ON ct.post_id = r.post_id
JOIN categories c ON c.id = ct.category_id
WHERE
r.date_time > 1500584821 /* unix_timestamp(DATE_SUB(now(), INTERVAL 1 WEEK)) */
GROUP BY
user_id, c.category
) AS q3
ON q3.user_id = q1.user_id
GROUP BY
q1.user_id, q1.user_name, q1.score, q1.reputation
ORDER BY
q1.reputation DESC, q1.score DESC ;