MySQL es fácil de instalar y usar, siempre ha sido popular entre los desarrolladores y administradores de sistemas. Por otro lado, implementar un entorno MySQL listo para producción para una carga de trabajo empresarial crítica para el negocio es una historia diferente. Puede ser un desafío y requiere un conocimiento profundo de la base de datos. En esta publicación de blog, analizaremos algunos de los pasos que deben tomarse antes de que podamos considerar que nuestra implementación de MySQL está lista para la producción.
Alta disponibilidad

Si pertenece a esos afortunados que pueden aceptar horas de inactividad, puede dejar de leer aquí y pasar al siguiente párrafo. Para el 99,999 % de los sistemas críticos para el negocio, no sería aceptable. Por lo tanto, una implementación lista para producción debe incluir medidas de alta disponibilidad. La conmutación por error automatizada de las instancias de la base de datos, así como una capa de proxy que detecta cambios en la topología y el estado de MySQL y enruta el tráfico en consecuencia, sería un requisito principal. Existen numerosas herramientas que se pueden utilizar para crear dichos entornos, por ejemplo, MHA, MRM o ClusterControl.
Capa de proxy
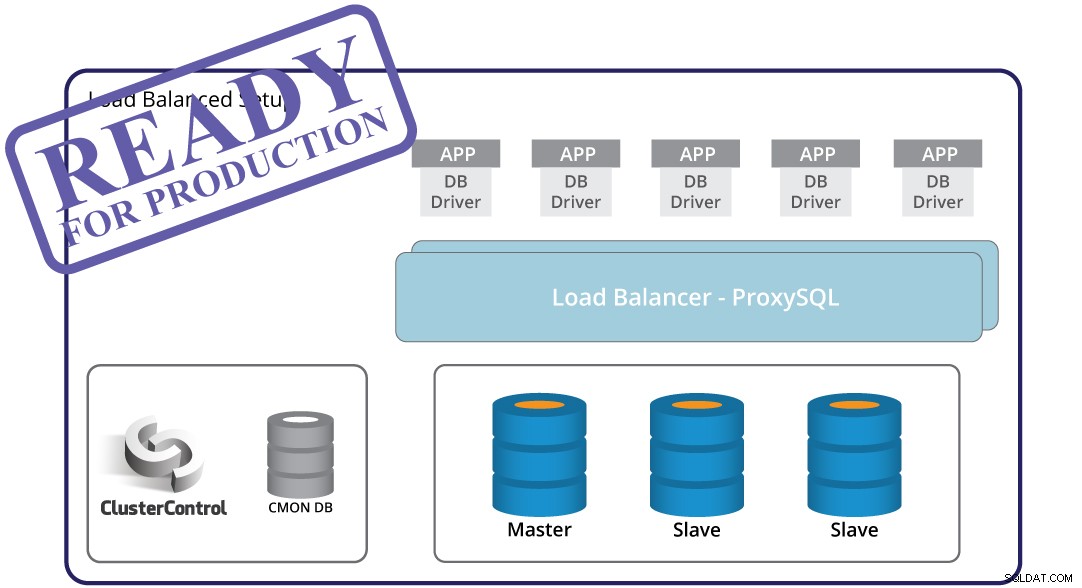
Detección de fallas maestras, conmutación por error automatizada y recuperación:estos son cruciales al construir una infraestructura lista para la producción. Pero por sí solos, no es suficiente. Todavía hay una aplicación que tendrá que adaptarse al cambio de topología desencadenado por la conmutación por error. Por supuesto, es posible codificar la aplicación para que esté al tanto de las fallas de las instancias. Sin embargo, esta es una forma engorrosa e inflexible de manejar los cambios de topología. Aquí viene el proxy de la base de datos:una capa intermedia entre la aplicación y la base de datos. Un proxy puede ocultar la complejidad de la capa de su base de datos de la aplicación:todo lo que hace la aplicación es conectarse al proxy y el proxy se encargará del resto. El proxy enrutará las consultas a una instancia de la base de datos, manejará los cambios de topología y redirigirá según sea necesario. También se puede usar un proxy para implementar la división de lectura y escritura, liberando a la aplicación de un caso más complejo para cubrir. Esto crea otro desafío:¿qué proxy usar? ¿Cómo configurarlo? ¿Cómo monitorearlo? ¿Cómo hacer que esté altamente disponible para que no se convierta en un SPOF?
ClusterControl puede ayudar aquí. Se puede usar para implementar diferentes proxies para formar una capa de proxy:ProxySQL, HAProxy y MaxScale. Preconfigura proxies para asegurarse de que manejarán el tráfico correctamente. También facilita la implementación de cualquier cambio de configuración si necesita personalizar la configuración del proxy para su aplicación. La división de lectura y escritura se puede configurar utilizando cualquiera de los proxies compatibles con ClusterControl. ClusterControl también monitorea los proxies y los recuperará en caso de fallas. La capa de proxy puede convertirse en un único punto de falla, ya que la recuperación automatizada puede no ser suficiente; para abordar eso, ClusterControl puede implementar Keepalived y configurar IP virtual para automatizar la conmutación por error.
Copias de seguridad
Incluso si no necesita implementar una alta disponibilidad, probablemente deba preocuparse por sus datos. La copia de seguridad es imprescindible para casi todas las bases de datos de producción. Nada más que una copia de seguridad puede salvarlo de un DROP TABLE o DROP SCHEMA accidental (bueno, tal vez un esclavo de replicación retrasado, pero solo por un período de tiempo). MySQL ofrece múltiples métodos para realizar copias de seguridad:mysqldump, xtrabackup, diferentes tipos de instantáneas (algunas disponibles solo con hardware particular o proveedor de nube). No es fácil diseñar la estrategia de copia de seguridad correcta, decidir qué herramientas usar y luego crear un script para todo el proceso para que se ejecute correctamente. Tampoco es ciencia espacial y requiere una planificación y pruebas cuidadosas. Una vez que se realiza una copia de seguridad, no ha terminado. ¿Está seguro de que la copia de seguridad se puede restaurar y que los datos no son basura? Verificar sus copias de seguridad lleva mucho tiempo y quizás no sea lo más emocionante que tendrá en su lista de tareas pendientes. Pero sigue siendo importante y debe hacerse con regularidad.
ClusterControl tiene una amplia funcionalidad de copia de seguridad y restauración. Admite mysqldump para copias de seguridad lógicas y Percona Xtrabackup para copias de seguridad físicas; estas herramientas se pueden usar en casi todos los entornos, ya sea en la nube o en las instalaciones. Es posible crear una estrategia de copia de seguridad con una combinación de copias de seguridad lógicas y físicas, incrementales o completas, en línea.
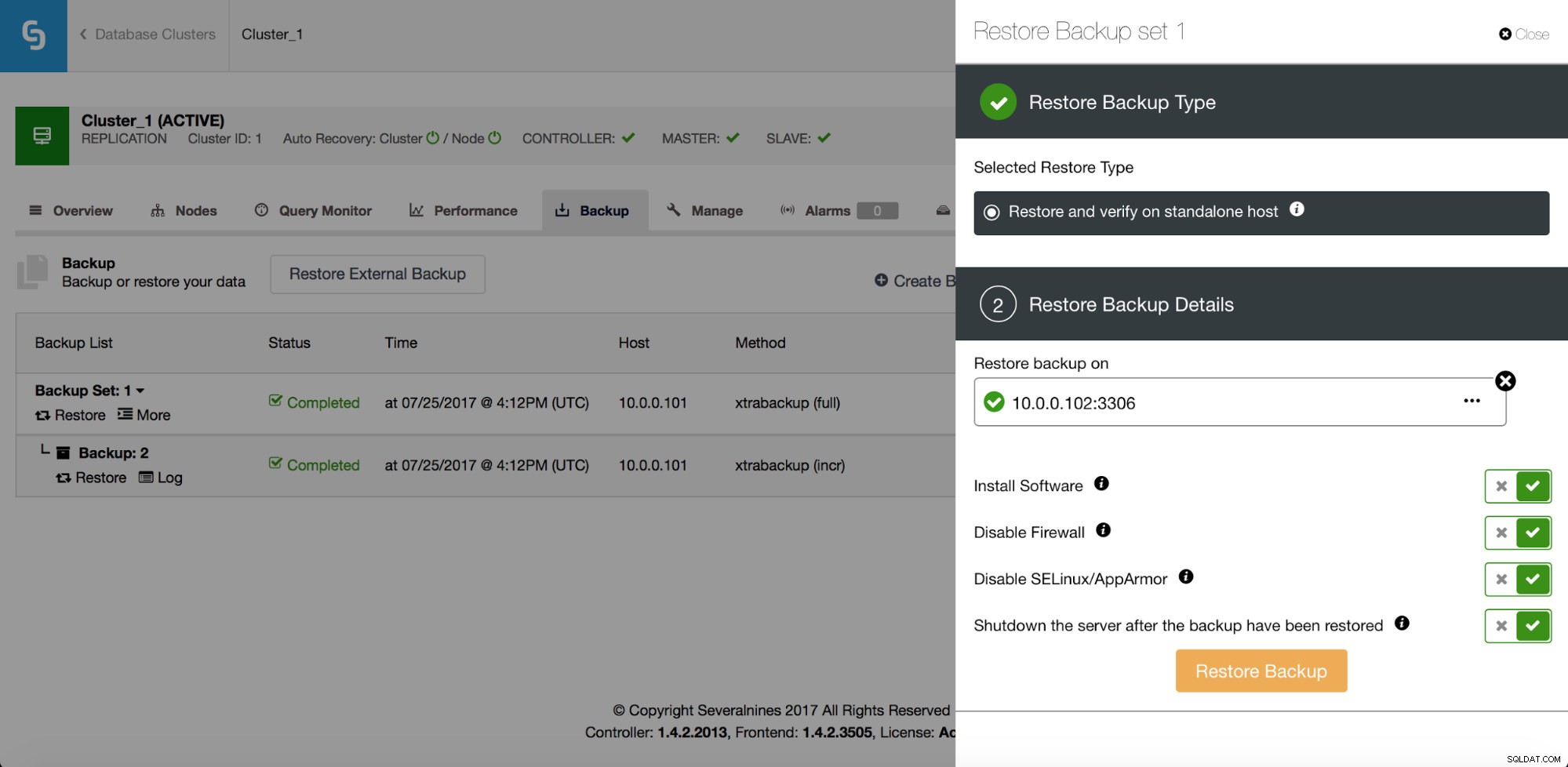
Además de la recuperación, también tiene opciones para verificar una copia de seguridad; por ejemplo, restaurarla en un host separado para verificar si el proceso de copia de seguridad funciona bien o no.
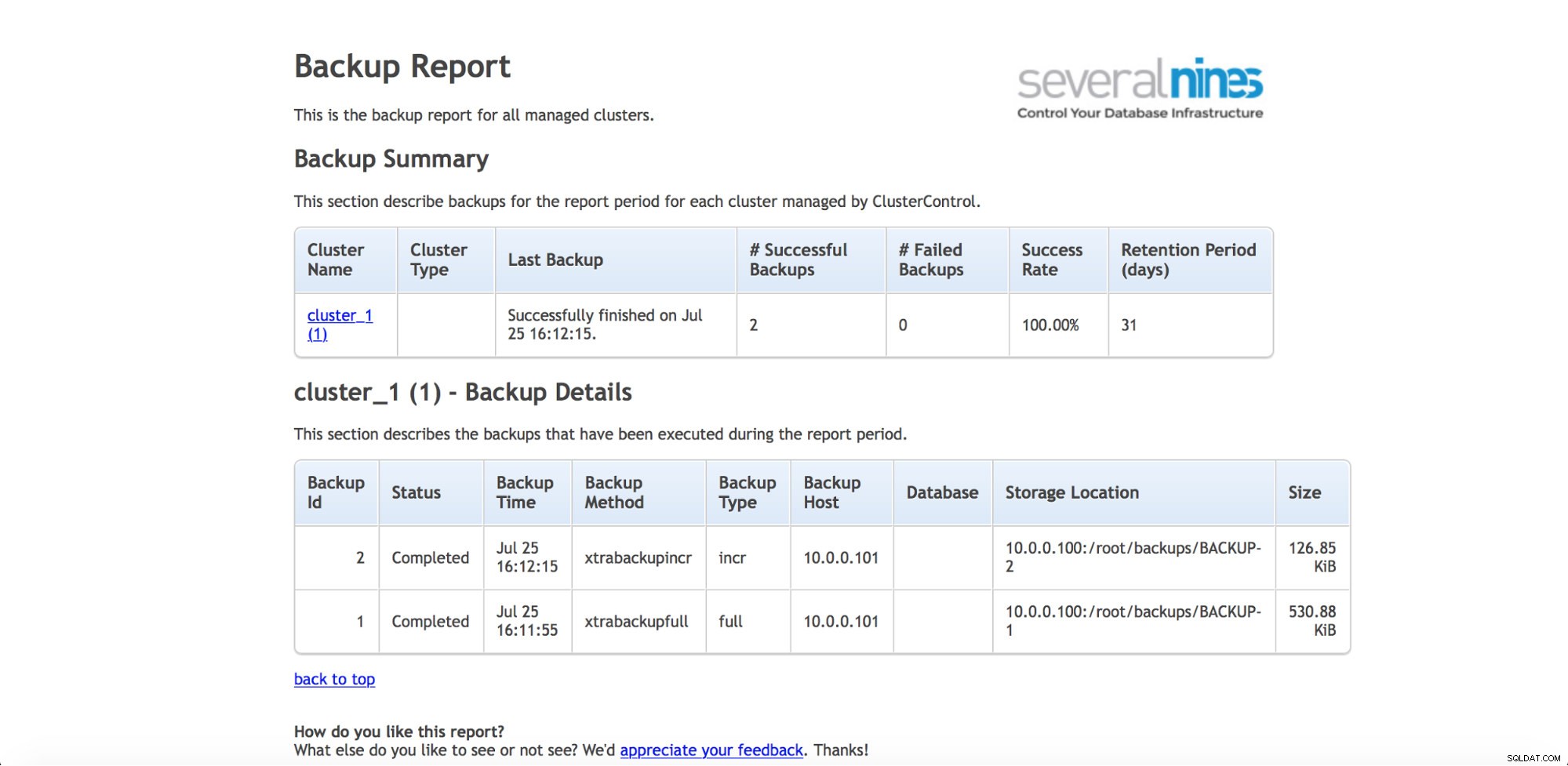
Si desea vigilar regularmente las copias de seguridad (y probablemente quiera hacerlo), ClusterControl tiene la capacidad de generar informes operativos. El informe de copia de seguridad lo ayuda a realizar un seguimiento de las copias de seguridad ejecutadas e informa si hubo algún problema al realizarlas.
Guía de DevOps para la gestión de bases de datos de VariousninesConozca lo que necesita saber para automatizar y gestionar sus bases de datos de código abiertoDescargar gratisSupervisión y tendencias

Ninguna implementación está lista para la producción sin una supervisión adecuada de los servicios. Desea asegurarse de que recibirá una alerta si algunos servicios no están disponibles para que pueda tomar medidas, investigar o iniciar procedimientos de recuperación. Por supuesto, también desea tener una solución de tendencia. No se puede enfatizar lo suficiente lo importante que es tener datos de monitoreo para evaluar el estado de la infraestructura o para cualquier investigación, ya sea post mortem o monitoreo en tiempo real del estado de los servicios. Las métricas no tienen la misma importancia:si no está muy familiarizado con un producto de base de datos en particular, lo más probable es que no sepa cuáles son las métricas más importantes para recopilar y observar. Claro, es posible que pueda recopilar todo, pero cuando se trata de revisar datos, es casi imposible revisar cientos de métricas por host; necesita saber en cuál de ellos debe concentrarse.
El mundo del código abierto está lleno de herramientas diseñadas para monitorear y recopilar métricas de diferentes bases de datos; la mayoría de ellas requieren que las integres con tu infraestructura de monitoreo general, plataforma de chatops o herramientas de soporte de guardia (como PagerDuty). También puede ser necesario instalar e integrar varios componentes:almacenamiento (algún tipo de base de datos de series temporales), capa de presentación y herramientas de recopilación de datos.
ClusterControl es un enfoque un poco diferente, ya que es un solo producto con monitoreo en tiempo real, tendencias y paneles que muestran los detalles más importantes. Los asesores de bases de datos, que pueden ser cualquier cosa, desde simples consejos de configuración, advertencias sobre umbrales o reglas más complejas para predicciones, generalmente producen recomendaciones integrales.
Capacidad de ampliación

Las bases de datos tienden a crecer en tamaño y no es improbable que crezcan en términos de volúmenes de transacciones o número de usuarios. La capacidad de escalar horizontal o verticalmente puede ser fundamental para la producción. Incluso si hace un gran trabajo al estimar sus requisitos de hardware al comienzo del ciclo de vida del producto, probablemente tendrá que manejar una fase de crecimiento, siempre que su producto tenga éxito, es decir (pero eso es lo que todos planeamos, ¿verdad? ?). Debe tener los medios para escalar fácilmente su infraestructura para hacer frente a la carga entrante. Para los servicios sin estado como los servidores web, esto es bastante fácil:solo necesita aprovisionar más instancias utilizando la imagen o el código de producción más reciente de su herramienta de control de versiones. Para servicios con estado como bases de datos, es más complicado. Debe aprovisionar nuevas instancias utilizando sus datos de producción actuales, configurar la replicación o alguna forma de agrupación entre las instancias actuales y las nuevas. Este puede ser un proceso complejo y para hacerlo bien, debe tener un conocimiento más profundo del modelo de agrupación o replicación elegido.
ClusterControl, como sugiere el nombre, brinda un amplio soporte para crear configuraciones de bases de datos replicadas o en clúster. Los métodos utilizados se prueban en batalla a través de miles de implementaciones. Viene con una interfaz de línea de comandos (CLI) para que pueda integrarse fácilmente con los sistemas de gestión de configuración. Sin embargo, tenga en cuenta que es posible que no desee realizar cambios en su conjunto de bases de datos con demasiada frecuencia:el aprovisionamiento de una nueva instancia lleva tiempo y agrega algunos gastos generales en las bases de datos existentes. Por lo tanto, es posible que desee permanecer un poco en el lado "sobreaprovisionado" para tener algo de tiempo para activar una nueva instancia antes de que su clúster se sobrecargue.
En general, hay varios pasos que debe seguir después de la implementación inicial para asegurarse de que su entorno esté listo para la producción. Con las herramientas adecuadas, es mucho más fácil llegar allí.