Cuando necesita trabajar con una base de datos con la que no está 100% familiarizado, puede sentirse abrumado por los cientos de métricas disponibles. ¿Cuáles son los más importantes? ¿Qué debo monitorear y por qué? ¿Qué patrones en las métricas deberían hacer sonar algunas alarmas? En esta publicación de blog, intentaremos presentarle algunas de las métricas más importantes que debe vigilar mientras ejecuta MySQL o MariaDB en producción.
Contadores de estado Com_*
Comenzaremos con los contadores Com_*, que definen el número y los tipos de consultas que ejecuta MySQL. Estamos hablando aquí de tipos de consulta como SELECCIONAR, INSERTAR, ACTUALIZAR y muchos más. Es muy importante vigilarlos, ya que los picos repentinos o las caídas inesperadas pueden sugerir que algo salió mal en el sistema.
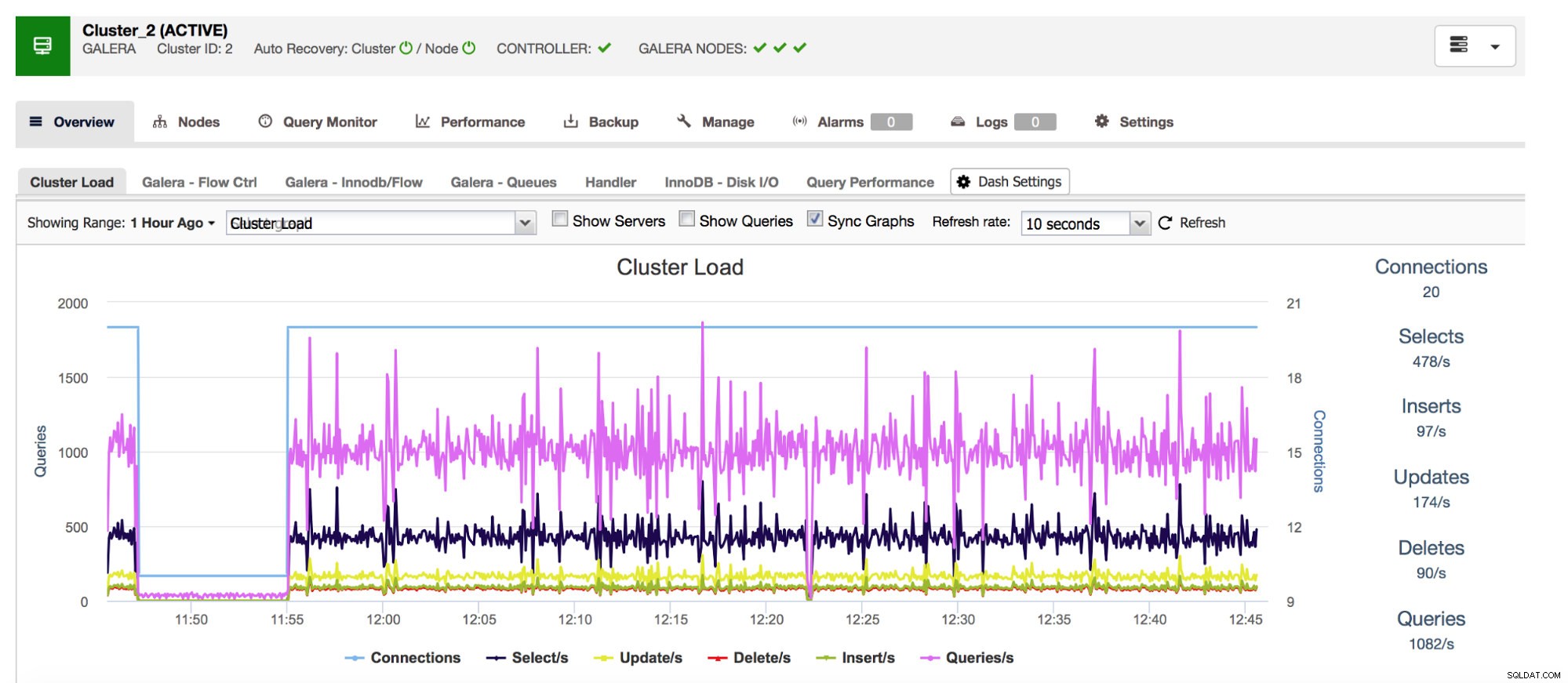
Nuestro sistema de administración de bases de datos todo incluido, ClusterControl, le muestra estos datos relacionados con los tipos de consultas más comunes en la sección "Descripción general".
Contadores de estado de Handler_*
Una categoría de métricas que debe vigilar son los contadores Handler_* en MySQL. Los contadores Com_* le dicen qué tipo de consultas está ejecutando su instancia de MySQL, pero un SELECT puede ser totalmente diferente a otro:SELECT podría ser una búsqueda de clave principal, también puede ser un escaneo de tabla si no se puede usar un índice. Los controladores le indican cómo accede MySQL a los datos almacenados; esto es muy útil para investigar los problemas de rendimiento y evaluar si existe una posible ganancia en la revisión de consultas y la indexación adicional.
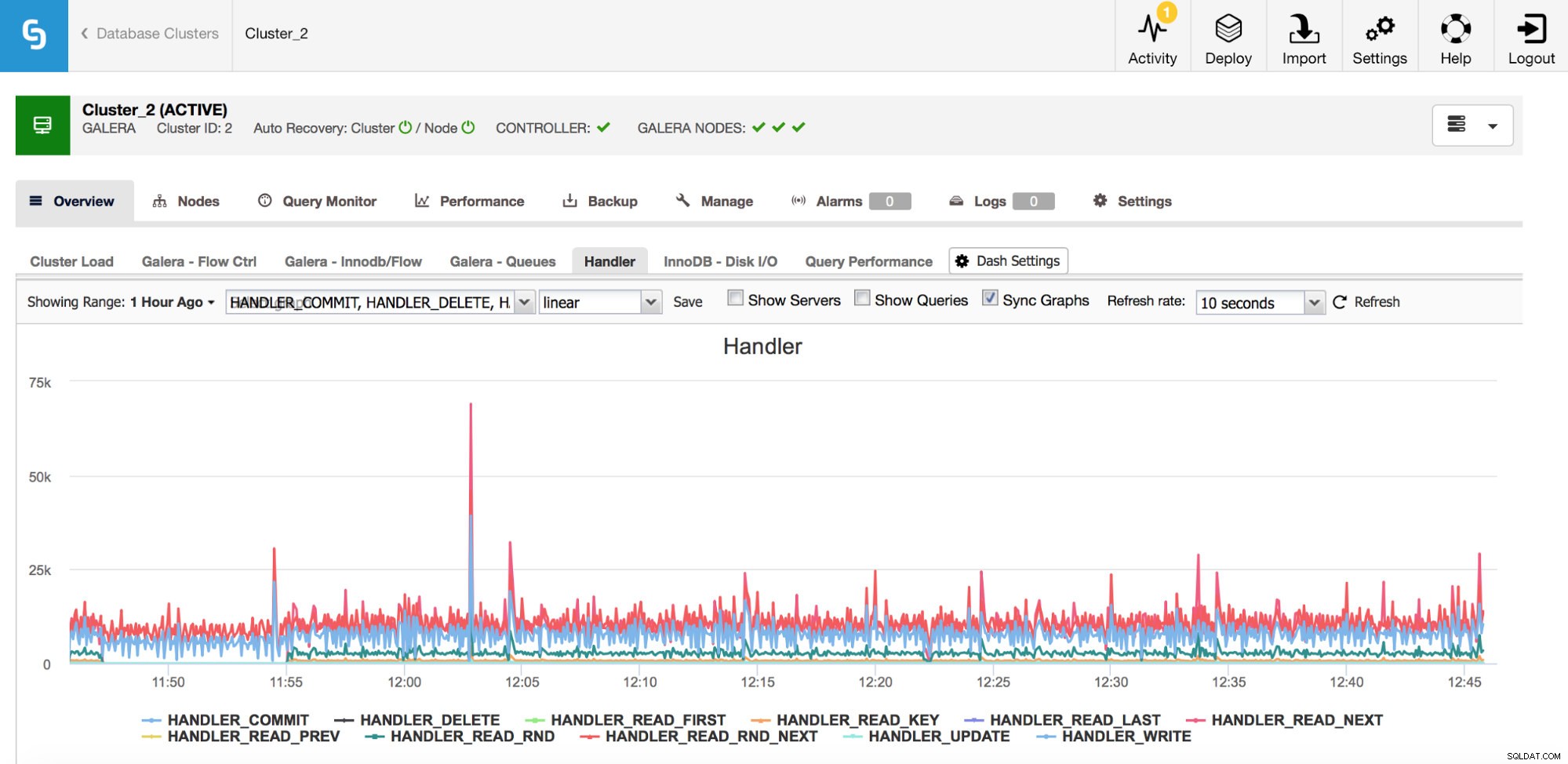
Como puede ver en el gráfico anterior, hay muchas métricas para rastrear (y los gráficos de ClusterControl son las más importantes); no las cubriremos todas aquí (puede encontrar descripciones en la documentación de MySQL), pero nos gustaría resaltar las los más importantes.
Handler_read_rnd_next:siempre que MySQL acceda a una fila sin una búsqueda de índice, en orden secuencial, este contador aumentará. Si en su carga de trabajo handler_read_rnd_next es responsable de un alto porcentaje de todo el tráfico, significa que sus tablas, muy probablemente, podrían usar algunos índices adicionales porque MySQL realiza muchas exploraciones de tablas.
Handler_read_next y handler_read_prev:esos dos contadores se actualizan cada vez que MySQL realiza un escaneo de índice, hacia adelante o hacia atrás. Handler_read_first y handler_read_last pueden arrojar algo más de luz sobre qué tipo de escaneos de índice son:si estamos hablando de un escaneo de índice completo (hacia adelante o hacia atrás), esos dos contadores se actualizarán.
Handler_read_key:este contador, por otro lado, si su valor es alto, le indica que sus tablas están bien indexadas ya que se accedió a muchas de las filas a través de una búsqueda de índice.
Retraso de replicación
Si está trabajando con la replicación de MySQL, el retraso de la replicación es una métrica que definitivamente desea monitorear. El retraso en la replicación es inevitable y tendrá que lidiar con él, pero para lidiar con eso, debe comprender por qué sucede. Para eso, el primer paso será saber _cuándo_ apareció.
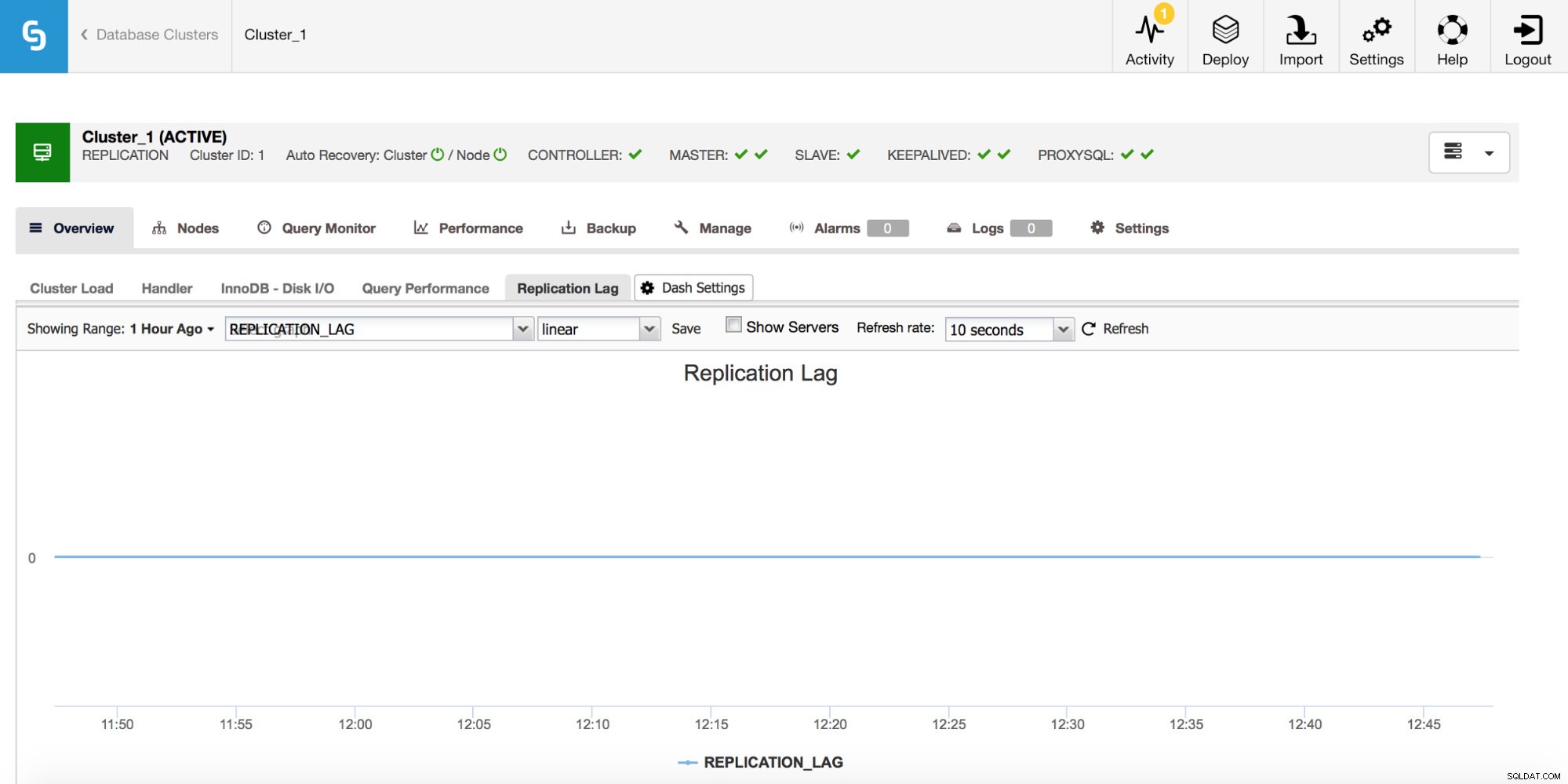
Cada vez que vea un pico en el retraso de la replicación, querrá consultar otros gráficos para obtener más pistas. ¿Por qué sucedió? ¿Qué pudo haberlo causado? Las razones pueden ser diferentes:DML largos y pesados, aumento significativo en la cantidad de DML ejecutados en un período corto de tiempo, limitaciones de E/S o CPU.
E/S InnoDB
Hay una serie de métricas importantes para monitorear las relacionadas con la E/S.
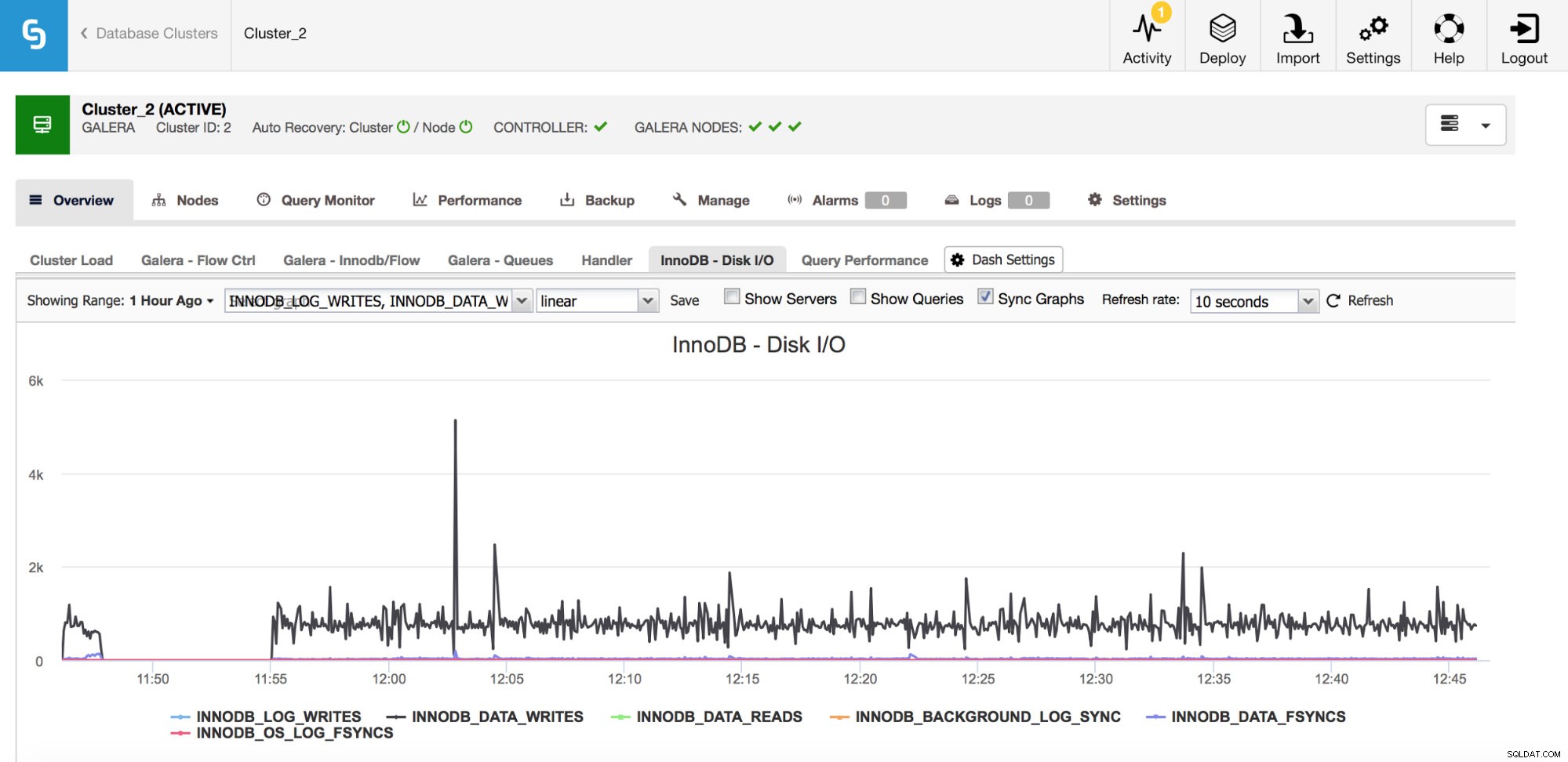
En el gráfico anterior, puede ver un par de métricas que le indican qué tipo de E/S hace InnoDB:escrituras y lecturas de datos, escrituras de registros de rehacer, fsyncs. Esas métricas lo ayudarán a decidir, por ejemplo, si el retraso de la replicación fue causado por un pico de E/S o tal vez por algún otro motivo. También es importante realizar un seguimiento de esas métricas y compararlas con las limitaciones de su hardware; si se está acercando a los límites de hardware de sus discos, tal vez sea hora de analizar esto antes de que tenga efectos más graves en el rendimiento de su base de datos.
Guía de DevOps para la gestión de bases de datos de VariousninesConozca lo que necesita saber para automatizar y gestionar sus bases de datos de código abiertoDescargar gratisMétricas de Galera:control de flujo y colas
Si usa Galera Cluster (sin importar qué sabor use), hay un par de métricas más que le gustaría monitorear de cerca, estas están unidas. El primero de ellos son las métricas relacionadas con el control de flujo.
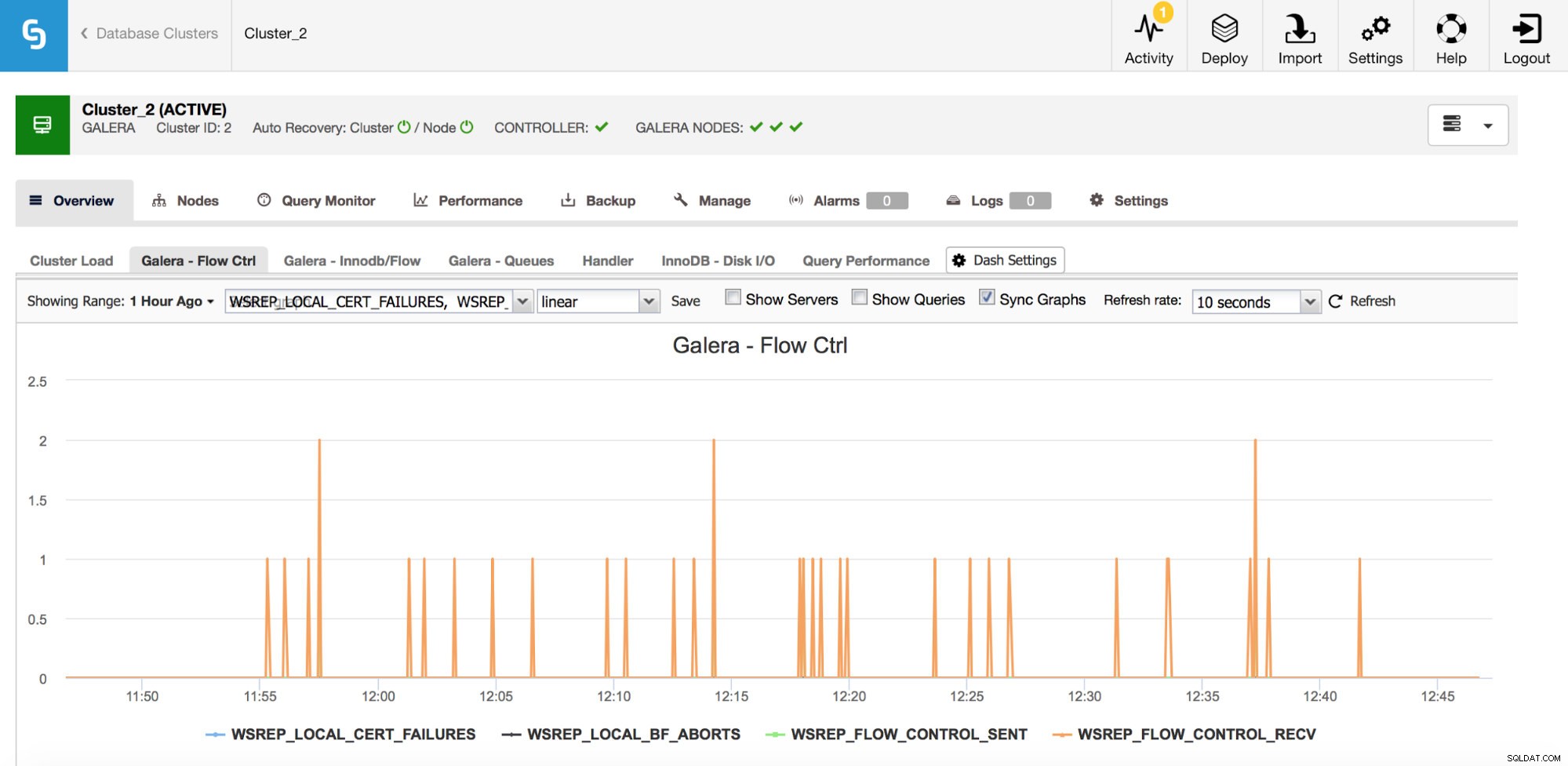
El control de flujo, en Galera, es un medio para mantener el clúster sincronizado. Cada vez que un nodo se detiene y no puede seguir el ritmo del resto del clúster, comienza a enviar mensajes de control de flujo solicitando a los nodos restantes del clúster que reduzcan la velocidad. Esto le permite ponerse al día. Esto reduce el rendimiento del clúster, por lo que es importante saber qué nodo y cuándo comenzó a enviar mensajes de control de flujo. Esto puede explicar algunas de las ralentizaciones experimentadas por los usuarios o limitar la ventana de tiempo y el host que se usará para una mayor investigación.
El segundo conjunto de métricas a monitorear son las relacionadas con las colas de envío y recepción en Galera.
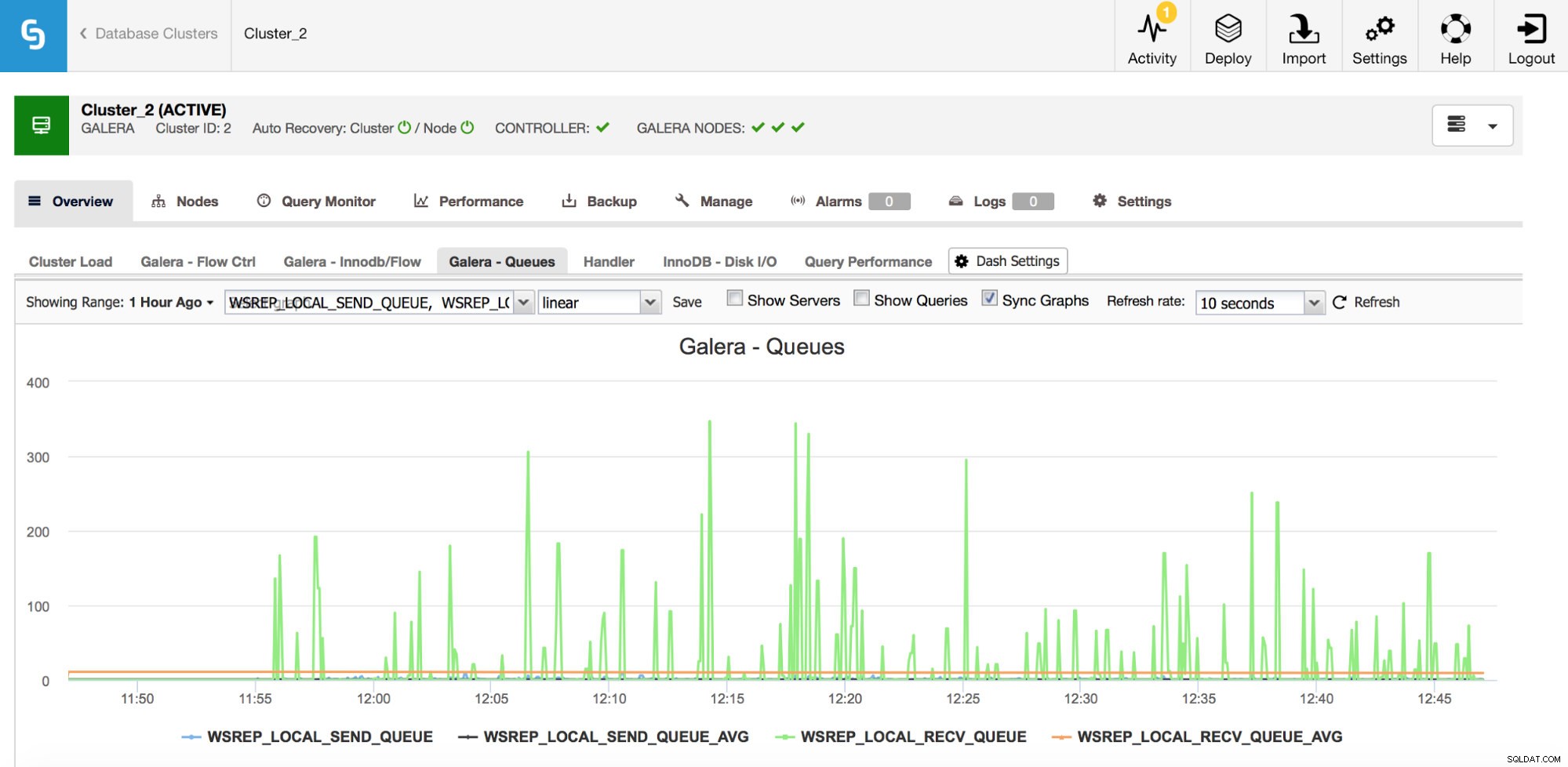
Los nodos de Galera pueden almacenar en caché conjuntos de escritura (transacciones) si no pueden aplicarlos todos de inmediato. Si es necesario, también pueden almacenar en caché conjuntos de escritura que están a punto de enviarse a otros nodos (si un nodo determinado recibe escrituras de la aplicación). Ambos casos son síntomas de una ralentización que, muy probablemente, dará como resultado el envío de mensajes de control de flujo y requerirá alguna investigación:¿por qué sucedió, en qué nodo, a qué hora?
Esto es, por supuesto, solo la punta del iceberg cuando consideramos todas las métricas que MySQL pone a disposición; aún así, no puede equivocarse si comienza a ver las que cubrimos aquí, además de las métricas regulares de SO/hardware como CPU. , memoria, utilización del disco y estado de los servicios.



