El siguiente es un extracto de nuestro documento técnico "Cómo diseñar entornos de bases de datos de código abierto de alta disponibilidad" que se puede descargar de forma gratuita.
Un par de palabras sobre la "alta disponibilidad"
En estos días, la alta disponibilidad es imprescindible para cualquier implementación seria. Atrás quedaron los días en los que podía programar un tiempo de inactividad de su base de datos durante varias horas para realizar un mantenimiento. Si sus servicios no están disponibles, está perdiendo clientes y dinero. Por lo tanto, hacer que un entorno de base de datos esté altamente disponible suele ser una de las principales prioridades.
Esto plantea un desafío importante para los administradores de bases de datos. En primer lugar, ¿cómo sabe si su entorno tiene alta disponibilidad o no? ¿Cómo lo medirías? ¿Cuáles son los pasos que debe seguir para mejorar la disponibilidad? ¿Cómo diseñar tu configuración para que esté altamente disponible desde el principio?
Hay muchas soluciones HA disponibles en el ecosistema MySQL (y MariaDB), pero ¿cómo sabemos en cuáles podemos confiar? Algunas soluciones pueden funcionar bajo ciertas condiciones específicas, pero pueden causar más problemas cuando se aplican fuera de estas condiciones. Incluso una funcionalidad básica como la replicación de MySQL, que se puede configurar de muchas maneras, puede causar un daño significativo, por ejemplo, la replicación circular con varios maestros grabables. Aunque es fácil configurar una "configuración multimaestro" mediante la replicación, puede romperse muy fácilmente y dejarnos con conjuntos de datos divergentes en diferentes servidores. Para una base de datos, que a menudo se considera la única fuente de verdad, la integridad de los datos comprometida puede tener consecuencias catastróficas.
En los siguientes capítulos, analizaremos los requisitos para la alta disponibilidad en las configuraciones de bases de datos
y cómo diseñar el sistema desde cero.
Medición de alta disponibilidad
¿Qué es la alta disponibilidad? Para poder decidir si un entorno determinado tiene alta disponibilidad o no, se deben tener algunas métricas para ello. Existen numerosas formas de medir la alta disponibilidad, nos centraremos en algunas de las cosas más básicas.
Primero, sin embargo, pensemos de qué se trata toda esta alta disponibilidad. ¿Cual es su propósito? Se trata de asegurarse de que su entorno cumpla su propósito. El propósito se puede definir de muchas maneras pero, por lo general, se tratará de brindar algún servicio. En el mundo de las bases de datos, normalmente está algo relacionado con los datos. Podría estar sirviendo datos a su aplicación interna. Puede ser para almacenar datos y hacerlos consultables mediante procesos analíticos. Puede ser almacenar algunos datos para sus usuarios y proporcionarlos cuando se soliciten. Una vez que tenemos claro el propósito, podemos establecer los factores de éxito involucrados. Esto nos ayudará a definir qué significa alta disponibilidad en nuestro caso específico.
SLA
Acuerdo de nivel de servicio (SLA). También es bastante común definir SLA para servicios internos. ¿Qué es un SLA? Es una definición del nivel de servicio que planea brindar a sus clientes. Esto es para que entiendan mejor qué nivel de estabilidad planeas para un servicio que compraron o planean comprar. Existen numerosos métodos que puede aprovechar para preparar un SLA, pero los típicos son:
- Disponibilidad del servicio (porcentaje)
- Capacidad de respuesta del servicio:latencia (promedio, máx., percentil 95, percentil 99)
- Pérdida de paquetes en la red (porcentaje)
- Rendimiento (promedio, mínimo, percentil 95, percentil 99)
Sin embargo, puede ser más complejo que eso. En un entorno multiusuario fragmentado, puede definir, digamos, su SLA como:“El servicio estará disponible el 99,99 % del tiempo, el tiempo de inactividad se declara cuando más del 2 % de los usuarios se ven afectados. Ninguna incidencia puede tardar más de 15 minutos en resolverse”. Dicho SLA también se puede ampliar para incorporar el tiempo de respuesta de la consulta:"se llama el tiempo de inactividad si el percentil 99 de latencia para las consultas supera los 200 milisegundos".
Nueves
La disponibilidad generalmente se mide en "nueves", veamos qué garantiza exactamente una cantidad determinada de "nueves". La siguiente tabla está tomada de Wikipedia:
| % de disponibilidad | Tiempo de inactividad por año | Tiempo de inactividad por mes | Tiempo de inactividad por semana | Tiempo de inactividad por día |
|---|---|---|---|---|
| 90% ("uno nueve") | 36,5 días | 72 horas | 16,8 horas | 2,4 horas |
| 95 % ("uno y medio nueves") | 18,25 días | 36 horas | 8,4 horas | 1,2 horas |
| 97 % | 10,96 días | 21,6 horas | 5,04 horas | 43,2 minutos |
| 98 % | 7,30 días | 14,4 horas | 3,36 horas | 28,8 minutos |
| 99% ("dos nueves") | 3,65 días | 7.20 horas | 1,68 horas | 14,4 minutos |
| 99,5 % ("dos nueves y medio") | 1,83 días | 3,60 horas | 50,4 minutos | 7,2 minutos |
| 99,8 % | 17.52 horas | 86,23 minutos | 20,16 minutos | 2,88 minutos |
| 99,9% ("tres nueves") | 8,76 horas | 43,8 minutos | 10,1 minutos | 1,44 minutos |
| 99,95 % ("tres nueves y medio") | 4,38 horas | 21,56 minutos | 5,04 minutos | 43,2 s |
| 99,99% ("cuatro nueves") | 52,56 minutos | 4,38 minutos | 1,01 min | 8,64 s |
| 99,995 % ("cuatro nueves y medio") | 26,28 minutos | 2,16 minutos | 30,24 s | 4,32 s |
| 99,999% ("cinco nueves") | 5,26 minutos | 25,9 s | 6,05 s | 864,3ms |
| 99,9999% ("seis nueves") | 31,5 s | 2,59 s | 604,8ms | 86,4ms |
| 99,99999% ("siete nueves") | 3,15 s | 262,97ms | 60,48ms | 8,64 ms |
| 99,999999% ("ocho nueves") | 315,569ms | 26,297ms | 6,048ms | 0,864ms |
| 99,9999999% ("nueve nueves") | 31,5569ms | 2,6297ms | 0,6048ms | 0,0864 ms |
Como podemos ver, se intensifica rápidamente. Cinco nueves (99,999 % de disponibilidad) equivalen a 5,26 minutos de tiempo de inactividad en el transcurso de un año. La disponibilidad también se puede calcular en diferentes rangos más pequeños:por mes, por semana, por día. Tenga en cuenta esos números, ya que serán útiles cuando comencemos a discutir los costos asociados con el mantenimiento de diferentes niveles de disponibilidad.
Medición de la disponibilidad
Para saber si hay un tiempo de inactividad o no, uno debe tener una idea del entorno. Debe realizar un seguimiento de las métricas que definen la disponibilidad de sus sistemas. Es importante tener en cuenta que debe medirlo desde el punto de vista del cliente, considerando el panorama más amplio. No importa si sus bases de datos están activas si, digamos, debido a un problema de red, ninguna aplicación no puede acceder a ellas. Cada bloque de construcción de su configuración tiene su impacto en la disponibilidad.
Uno de los buenos lugares donde buscar datos de disponibilidad son los registros del servidor web. Todas las solicitudes que terminaron con errores significan que algo sucedió. Podría ser el error HTTP 500 devuelto por la aplicación, porque falló la conexión a la base de datos. Esos podrían ser errores de programación que apuntan a algunos problemas de la base de datos y que terminaron en el registro de errores de Apache. También puede usar una métrica simple como el tiempo de actividad de los servidores de la base de datos, aunque, con SLA más complejos, puede ser complicado determinar cómo la falta de disponibilidad de una base de datos afectó a su base de usuarios. Independientemente de lo que haga, debe usar más de una métrica; esto es necesario para capturar problemas que podrían haber ocurrido en diferentes capas de su entorno.
Número Mágico:“Tres”
Aunque la alta disponibilidad también tiene que ver con la redundancia, en el caso de los clústeres de bases de datos, tres es un número mágico. No es suficiente tener dos nodos para la redundancia; dicha configuración no proporciona ninguna alta disponibilidad integrada. Claro, podría ser mejor que un solo nodo, pero se requiere la intervención humana para recuperar los servicios. Veamos por qué es así.
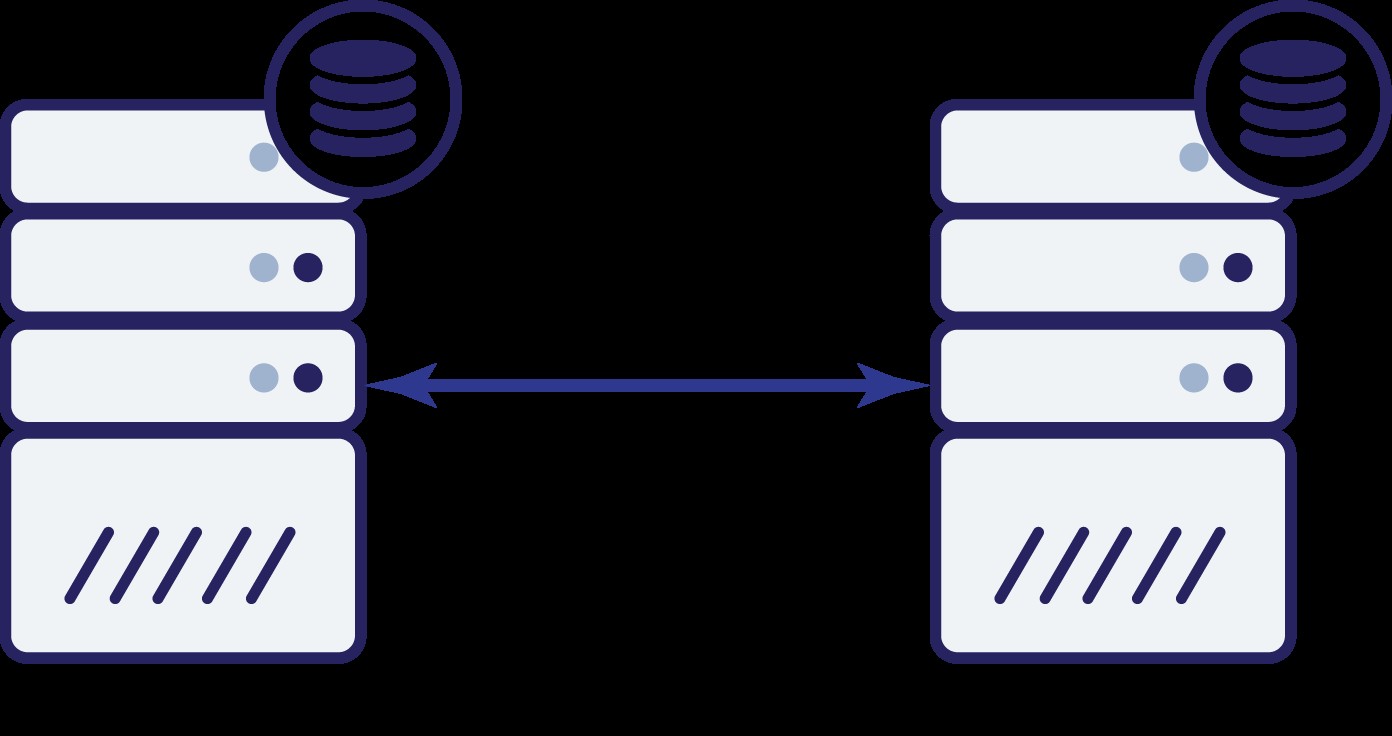
Supongamos que tenemos dos nodos, A y B. Hay un enlace de red entre ellos. Supongamos que tanto A como B sirven escrituras y la aplicación elige aleatoriamente dónde conectarse (lo que significa que parte de la aplicación se conectará al nodo A y la otra parte se conectará al nodo B). Ahora, imaginemos que tenemos un problema de red que resulta en la pérdida de conectividad de red entre A y B.
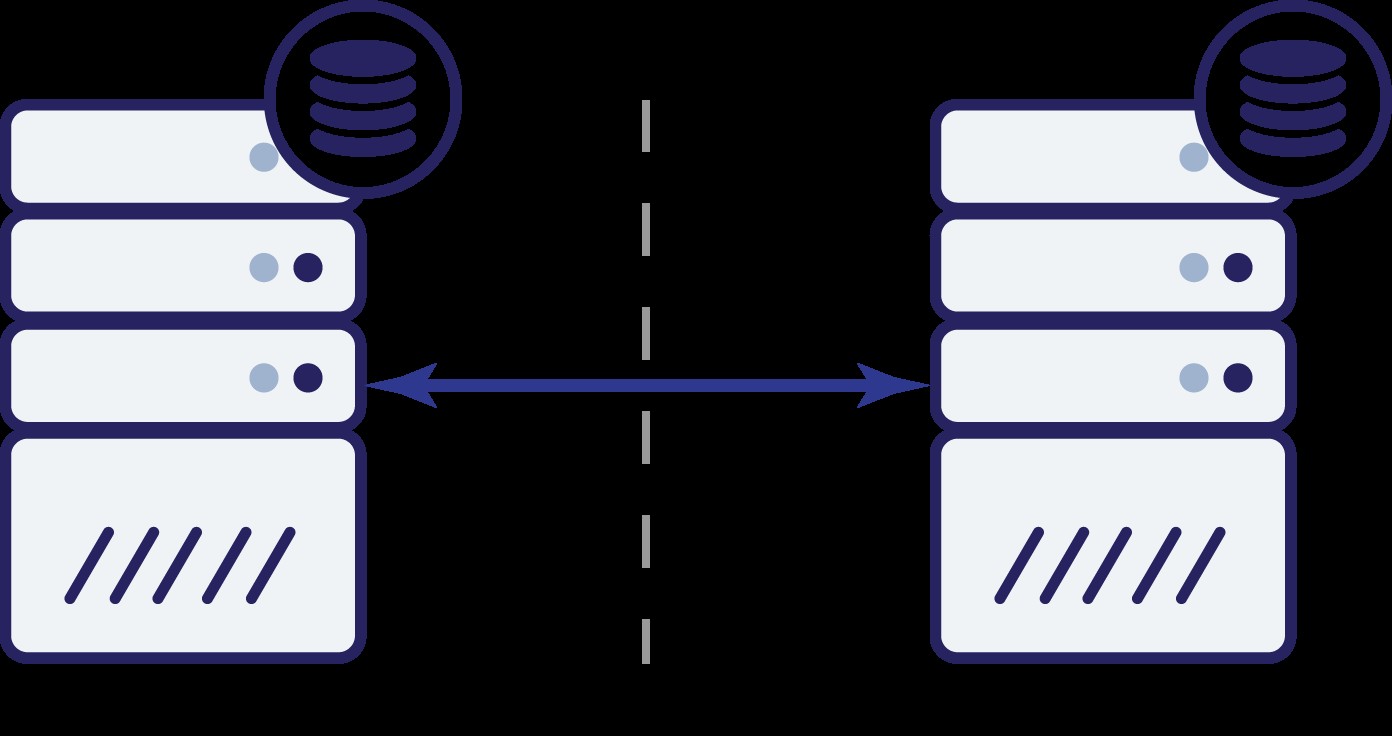
¿Ahora que? Ni A ni B pueden conocer el estado del otro nodo. Hay dos acciones que pueden realizar ambos nodos:
- Pueden seguir aceptando tráfico
- Pueden dejar de operar y negarse a atender cualquier tráfico
Pensemos en la primera opción. Siempre que el otro nodo esté inactivo, esta es la acción preferida:queremos que nuestra base de datos continúe sirviendo tráfico. Después de todo, esta es la idea principal detrás de la alta disponibilidad. Sin embargo, ¿qué pasaría si ambos nodos continuaran aceptando tráfico mientras están desconectados entre sí? Se agregarán nuevos datos en ambos lados y los conjuntos de datos no estarán sincronizados. Cuando se resuelva el problema de la red, será una tarea abrumadora fusionar esos dos conjuntos de datos. Por lo tanto, no es aceptable mantener ambos nodos en funcionamiento. El problema es:¿cómo puede el nodo A saber si el nodo B está vivo o no (y viceversa)? La respuesta es - no puede. Si toda la conectividad está inactiva, no hay forma de distinguir un nodo fallido de una red fallida. Como resultado, la única acción segura es que ambos nodos detengan todas las operaciones y se nieguen a
servir tráfico.
Pensemos ahora cómo un tercer nodo puede ayudarnos en tal situación.
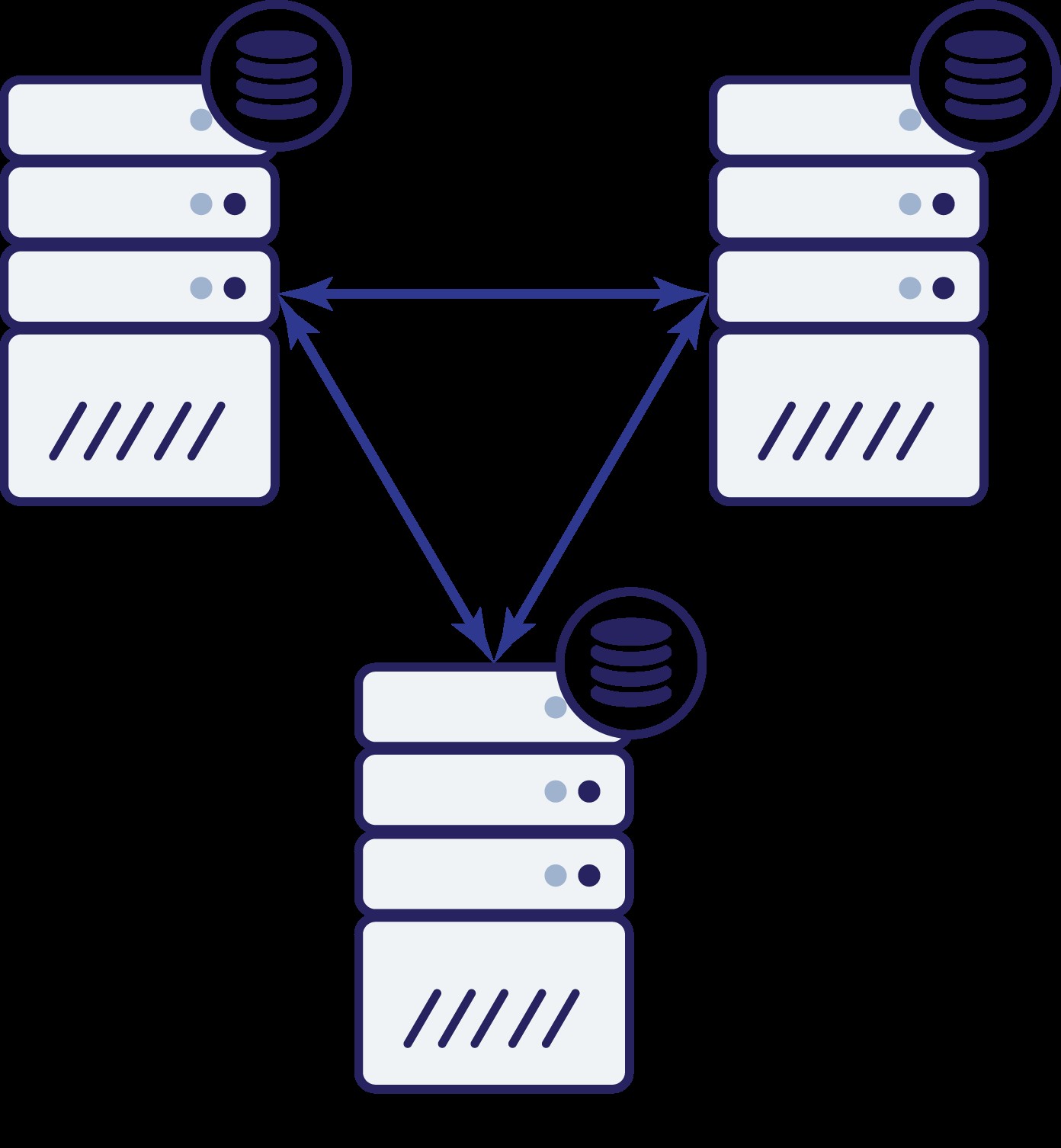
Así que ahora tenemos tres nodos:A, B y C. Todos están interconectados, todos manejan lecturas y escrituras.
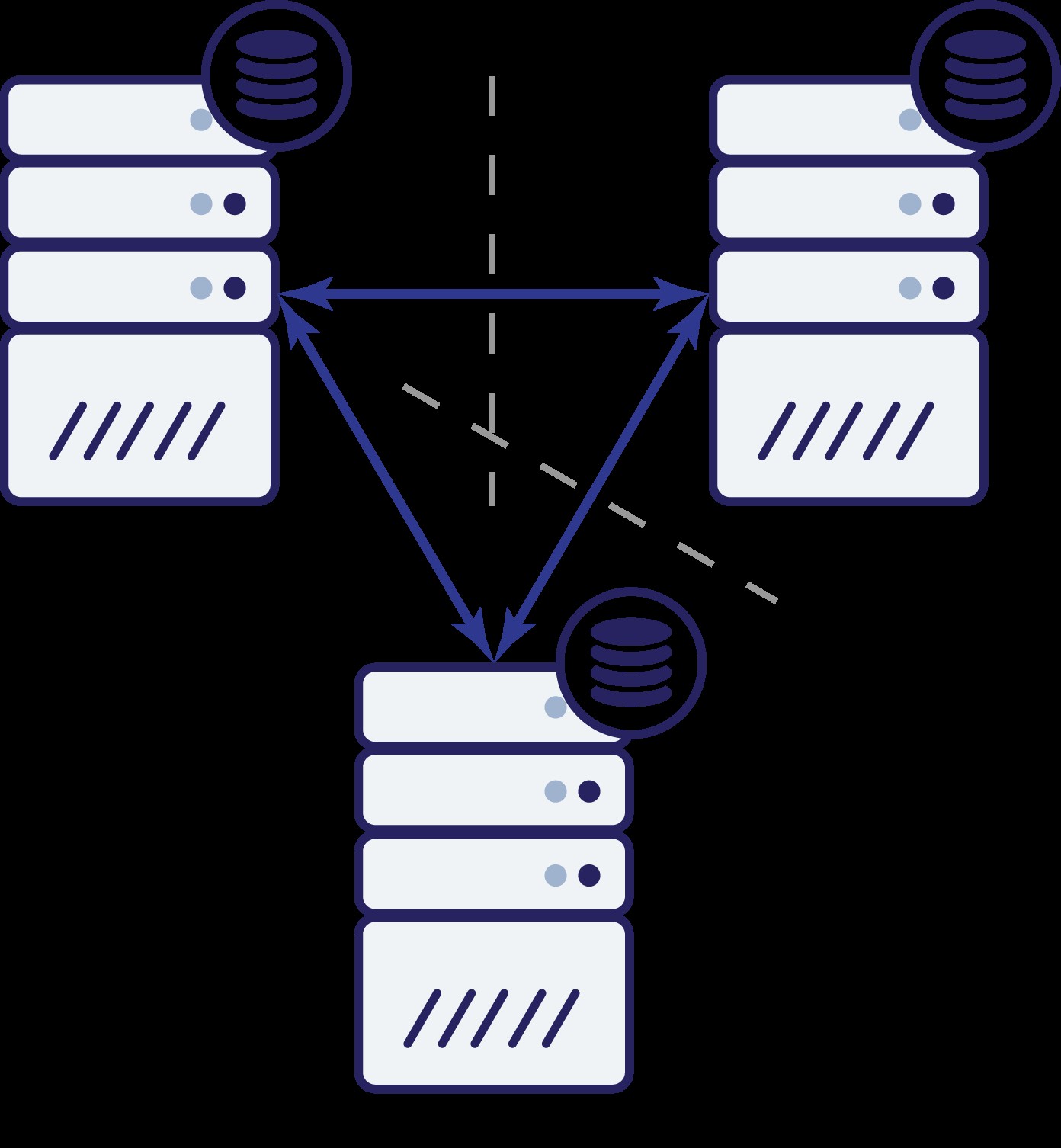
Nuevamente, como en el ejemplo anterior, el nodo B se separó del resto del clúster debido a problemas de red. ¿Qué puede pasar después? Bueno, la situación es bastante similar a lo que discutimos anteriormente. Dos opciones:el nodo B puede estar inactivo (y el resto del clúster debe continuar) o puede estar activo, en cuyo caso no se le debe permitir manejar ningún tráfico. ¿Podemos decir ahora cuál es el estado del clúster? Actualmente, si. Podemos ver que los nodos A y C pueden comunicarse entre sí y, como resultado, pueden estar de acuerdo en que el nodo B no está disponible. No podrán decir por qué sucedió, pero lo que saben es que de tres nodos en el clúster, dos todavía tienen conectividad entre sí. Dado que esos dos nodos forman la mayoría del clúster, es posible continuar manejando el tráfico. Al mismo tiempo, el nodo B también puede deducir que el problema está de su parte. No puede acceder ni al nodo A ni al nodo C, por lo que el nodo B está separado del resto del clúster. Como está aislado y no es parte de una mayoría (1 de 3), la única acción segura que puede tomar es dejar de atender el tráfico y negarse a aceptar cualquier consulta, asegurándose de que no ocurra la deriva de datos.
Por supuesto, eso no significa que solo pueda tener tres nodos en el clúster. Si desea una mejor tolerancia a fallas, es posible que desee agregar más. Sin embargo, tenga en cuenta que debe ser un número impar si desea mejorar la alta disponibilidad. Además, estábamos hablando de "nodos" en los ejemplos anteriores. Tenga en cuenta que esto también se aplica a los centros de datos, las zonas de disponibilidad, etc. Si tiene dos centros de datos, cada uno con la misma cantidad de nodos (digamos tres nodos cada uno), y pierde la conectividad entre esos dos DC, se aplican los mismos principios aquí. - no puede saber qué mitad del clúster debe comenzar a manejar el tráfico. Para poder decir eso, debe tener un observador en un tercer centro de datos. Puede ser otro conjunto de nodos, o simplemente un único host, con la tarea
de observar el estado de los centros de datos restantes y participar en la toma de decisiones (un ejemplo aquí sería el árbitro de Galera).
Puntos únicos de falla
La alta disponibilidad consiste en eliminar los puntos únicos de falla (SPOF) y no introducir otros nuevos en el proceso. ¿Qué son los SPOF? Cualquier parte de su infraestructura que, cuando falla, genera tiempo de inactividad según lo definido en SLA, se denomina SPOF. El diseño de infraestructura requiere un enfoque holístico, los diferentes componentes no pueden diseñarse independientemente unos de otros. Lo más probable es que usted no sea responsable de todo el diseño;
los administradores de bases de datos tienden a centrarse en las bases de datos y no, por ejemplo, en la capa de red. Aún así, debe tener en cuenta las otras partes y trabajar con los equipos que son responsables de ellas, para asegurarse de que no solo la parte de la que es responsable esté diseñada correctamente, sino también que las partes restantes de la infraestructura se diseñaron utilizando el mismos principios. Además de eso, tal conocimiento de cómo se diseña toda la infraestructura, también lo ayuda a diseñar la pila de la base de datos. Saber qué problemas pueden ocurrir ayuda a construir algunos mecanismos para evitar que afecten la disponibilidad de la base de datos.