Teniendo en cuenta el principal caso de uso actual de una base de datos para recuperar datos, se vuelve muy importante que su rendimiento sea muy alto y solo se puede lograr si los datos se obtienen del almacenamiento de la manera más eficiente posible. Se han realizado muchas invenciones e implementaciones exitosas para lograr lo mismo. Uno de los enfoques bien conocidos adoptados por la mayoría de las bases de datos es tener un índice en la tabla.
¿Qué es un índice de base de datos?
El índice de la base de datos, como sugiere su nombre, mantiene un índice de los datos reales y, por lo tanto, mejora el rendimiento para recuperar datos de la tabla real. En una terminología más de base de datos, el índice permite obtener una página que contiene datos indexados en un recorrido mínimo, ya que los datos se clasifican en un orden específico. El beneficio del índice tiene el costo de espacio de almacenamiento adicional para escribir datos adicionales. Los índices son específicos de la tabla subyacente y constan de una o más claves (es decir, una o más columnas de la tabla especificada). Existen principalmente dos tipos de arquitectura de índice
- Índice agrupado:los datos del índice se almacenan junto con otra parte de los datos y los datos se ordenan según la clave del índice. Como máximo, solo puede haber un índice en esta categoría para una tabla específica.
- Índice no agrupado:los datos del índice se almacenan por separado y tienen un puntero al almacenamiento donde se almacena otra parte de los datos. Esto también se conoce como índice secundario. Puede haber tantos índices de esta categoría como desee en una tabla específica.
Hay varias estructuras de datos que se utilizan para implementar índices, algunas de las ampliamente adoptadas por la mayoría de las bases de datos son B-Tree y Hash.
¿Qué es un índice de PostgreSQL?
PostgreSQL solo admite índices no agrupados. Eso significa datos de índice y datos completos (de aquí en adelante denominados datos del montón ) se almacenan en un almacenamiento separado. Los índices no agrupados son como "Tabla de contenido" en cualquier documento, en el que primero verificamos el número de página y luego verificamos esos números de página para leer todo el contenido. Para obtener los datos completos basados en un índice, mantiene un puntero a los datos del montón correspondientes. Es lo mismo que después de conocer el número de página, debe ir a esa página y obtener el contenido real de la página.
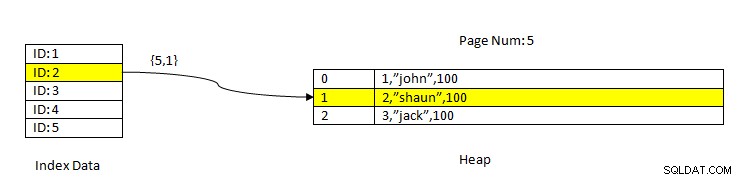 PostgreSQL:lectura de datos mediante índice
PostgreSQL:lectura de datos mediante índice Por ejemplo, considere una tabla con tres columnas y un índice en la columna ID . Para LEER los datos basados en la clave ID=2, primero, se buscan los datos indexados con el valor de ID 2. Este contiene un puntero (llamado puntero de elemento) en términos del número de página (es decir, el número de bloque) y el desplazamiento de los datos dentro de esa página. En el ejemplo actual, el índice apunta a la página número 5 y al segundo elemento de línea de la página que, a su vez, mantiene la compensación de todos los datos (2, "Shaun", 100). Observe que los datos completos también contienen los datos indexados, lo que significa que los mismos datos se repiten en dos almacenamientos.
¿Cómo ayuda INDEX a mejorar el rendimiento? Bueno, para seleccionar cualquier registro de ÍNDICE, no escanea todas las páginas secuencialmente, sino que solo necesita escanear parcialmente algunas de las páginas utilizando la estructura de datos del Índice subyacente. Pero hay un giro, ya que cada registro que se encuentra a partir de los datos del índice, necesita buscar datos completos en los datos del montón, lo que provoca una gran cantidad de E/S aleatorias y se considera que funciona más lentamente que la E/S secuencial. Entonces, solo si se selecciona un pequeño porcentaje de registros (lo que se decidió en función del costo del optimizador de PostgreSQL), solo PostgreSQL elige el escaneo de índice; de lo contrario, aunque haya un índice en la tabla, continúa usando el escaneo de secuencia.
En resumen, aunque la creación de índices acelera el rendimiento, debe elegirse con cuidado ya que tiene una sobrecarga en términos de almacenamiento y rendimiento degradado de INSERT.
Ahora podemos preguntarnos, en caso de que solo necesitemos la parte del índice de los datos, ¿podemos obtener solo de la página de almacenamiento del índice? Bueno, la respuesta a esto está directamente relacionada con cómo funciona MVCC en el almacenamiento de índice, como se explica a continuación.
Uso de MVCC para la indexación
Al igual que las páginas Heap, la página de índice mantiene varias versiones de la tupla de índice, pero no mantiene la información de visibilidad. Como se explica en mi anterior MVCC blog, para decidir la versión visible adecuada de las tuplas, requiere comparar transacciones. La transacción que insertó/actualizó/eliminó la tupla se mantiene junto con la tupla del montón, pero no se mantiene lo mismo con la tupla del índice. Esto se hace puramente para ahorrar almacenamiento y es una compensación entre espacio y rendimiento.
Ahora, volviendo a la pregunta original, dado que la información de visibilidad en la tupla de índice no está allí, debe consultar la tupla de montón correspondiente para ver si los datos seleccionados son visibles. Entonces, aunque no se requieren otras partes de los datos de la tupla del montón, aún necesita acceder a las páginas del montón para verificar la visibilidad. Pero nuevamente, hay un giro en caso de que todas las tuplas en una página determinada (página señalada por índice, es decir, ItemPointer) estén visibles, entonces no es necesario consultar cada elemento de la página Heap para "comprobación de visibilidad" y, por lo tanto, los datos solo se pueden devolver de la página de índice. Este caso especial se denomina “Escaneo de índice solamente”. Para respaldar esto, PostgreSQL mantiene un mapa de visibilidad para cada página para verificar la visibilidad a nivel de página.
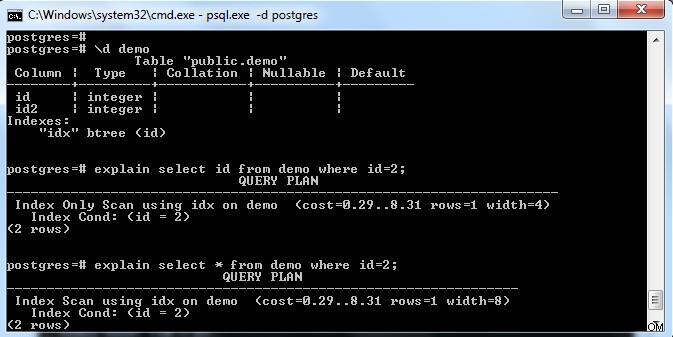
Como se muestra en la imagen de arriba, hay un índice en la tabla "demo" con una clave en la columna "id". Si tratamos de seleccionar solo el campo de índice (es decir, id), entonces elige el "Escaneo de solo índice" (considerando la página de referencia completamente visible).
Índice agrupado
No hay soporte de índice agrupado directo en PostgreSQL, pero hay una forma indirecta de lograrlo parcialmente. Esto se logra con los siguientes comandos SQL:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]El primer comando le indica a la base de datos que agrupe una tabla (es decir, que ordene la tabla) usando el índice dado. Este índice ya debería haber sido creado. Esta agrupación es una sola operación y su impacto no permanece después de la operación posterior en esta tabla, es decir, si se insertan/actualizan más registros, es posible que la tabla no permanezca ordenada. Si el usuario necesita mantener la tabla agrupada (ordenada), puede usar el primer comando sin dar un nombre de índice.
El segundo comando solo es útil para volver a agrupar la tabla (es decir, la tabla que ya estaba agrupada usando algún índice). Este comando vuelve a agrupar todas las tablas en la base de datos actual visible para el usuario conectado actual.
Por ejemplo, en la figura a continuación, el primer SELECT devuelve registros en orden desordenado ya que no hay un índice agrupado. Aunque ya existe un índice no agrupado, los registros se seleccionan del área del montón donde los registros no están ordenados.
El segundo SELECT devuelve los registros ordenados por columna "id" tal como se ha agrupado usando el índice que contiene la columna "id".
El tercer SELECT devuelve registros parciales ordenados, pero los registros recién insertados no están ordenados. El cuarto SELECT nuevamente devuelve todos los registros en orden ya que la tabla se ha agrupado nuevamente
 Comando de clúster de PostgreSQL
Comando de clúster de PostgreSQL Tipo de índice
PostgreSQL proporciona varios tipos de índices como se muestra a continuación:
- Árbol B
- hachís
- GiST
- GINEBRA
- BRIN
Cada tipo de índice implementa diferentes tipos de estructura de datos subyacente, que es la más adecuada para diferentes tipos de consultas. De forma predeterminada, se crea el índice B-Tree, que es un índice ampliamente utilizado. Los detalles de cada tipo de índice se cubrirán en un blog futuro.
Misc:índice parcial y de expresión
Solo hemos discutido sobre índices en una o más columnas de una tabla, pero hay otras dos formas de crear índices en PostgreSQL
- Índice parcial: Índice parcial es un índice creado utilizando el subconjunto de una columna clave para una tabla en particular. El subconjunto está definido por la expresión condicional proporcionada durante la creación del índice. Entonces, con el índice parcial, se ahorra espacio de almacenamiento para almacenar datos de índice. Por lo tanto, el usuario debe elegir la condición de tal manera que esos valores no sean muy comunes, ya que para los valores más frecuentes (comunes) de todos modos, no se elegirá el escaneo de índice. El resto de la funcionalidad sigue siendo la misma que para un índice normal. Ejemplo:Índice parcial
- Índice de expresión: Los índices de expresión brindan otro tipo de flexibilidad en PostgreSQL. Todos los índices discutidos hasta ahora, incluidos los índices parciales, se encuentran en un conjunto particular de columnas. Pero, ¿qué sucede si una consulta implica el acceso a una tabla basada en la expresión (expresión que involucra una o más columnas), sin un índice de expresión, no elegirá el escaneo de índice? Entonces, para acceder rápidamente a este tipo de consultas, PostgreSQL permite crear un índice en una expresión. El resto de la funcionalidad sigue siendo la misma que para un índice normal.
 Ejemplo:índice de expresión
Ejemplo:índice de expresión
Almacenamiento de índices en InnoDB
El uso y la funcionalidad de Index son básicamente los mismos que en PostgreSQL con una gran diferencia en términos de Clustered Index.
InnoDB admite dos categorías de índices:
- Índice agrupado
- Índice secundario
Índice agrupado
El índice agrupado es un tipo especial de índice en InnoDB. Aquí, los datos indexados no se almacenan por separado, sino que son parte de los datos de la fila completa. En otras palabras, el índice agrupado solo obliga a que los datos de la tabla se ordenen físicamente utilizando la columna clave del índice. Se puede considerar como un "Diccionario", donde los datos se ordenan según el alfabeto.
Dado que el índice agrupado ordena las filas mediante una clave de índice, solo puede haber un índice agrupado. Además, debe haber un índice agrupado, ya que InnoDB lo usa para manipular de manera óptima los datos durante varias operaciones de datos.
Los índices agrupados se crean automáticamente (como parte de la creación de la tabla) usando una de las columnas de la tabla según la siguiente prioridad:
- Utilizar la clave principal si la clave principal se menciona como parte de la creación de la tabla.
- Elige cualquier columna única en la que todas las columnas clave NO sean NULAS.
- De lo contrario, genera internamente un índice agrupado oculto en una columna del sistema que contiene el ID de fila de cada fila.
A diferencia del índice no agrupado de PostgreSQL, InnoDB accede a una fila usando el índice agrupado más rápido porque la búsqueda del índice conduce directamente a la página con todos los datos de la fila y, por lo tanto, evita la E/S aleatoria.
Además, obtener los datos de la tabla en orden mediante el índice agrupado es muy rápido, ya que todos los datos ya están ordenados y también están disponibles todos los datos.
Índice secundario
El índice creado explícitamente en InnoDB se considera un índice secundario, que es similar al índice no agrupado de PostgreSQL. Cada registro en el almacenamiento del índice secundario contiene columnas de clave principal de las filas (que se usaron para crear el índice agrupado) y también las columnas especificadas para crear un índice secundario.
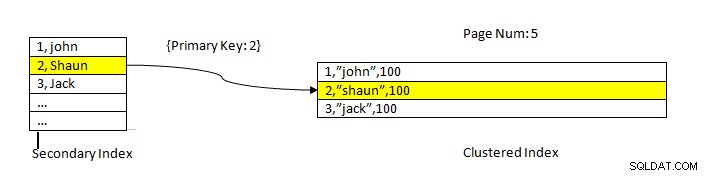 InnoDB:Lectura de datos usando índice
InnoDB:Lectura de datos usando índice La obtención de datos mediante un índice secundario es similar al caso de PostgreSQL, excepto que la búsqueda del índice secundario de InnoDB proporciona una clave principal como indicador para obtener los datos restantes del índice agrupado.
Por ejemplo, como se muestra en la imagen de arriba, el índice agrupado está en la columna ID, por lo que los datos de la tabla se ordenan de la misma manera. El índice secundario está en la columna "nombre ”, entonces, como podemos ver, el índice secundario tiene tanto ID como valor de nombre. Una vez que buscamos usando el índice secundario, encuentra la ranura apropiada con el valor clave correspondiente. Luego, la clave principal correspondiente se usa para hacer referencia a la parte restante de los datos del índice agrupado.
MVCC para índice
El índice agrupado MVCC utiliza el modelo tradicional de deshacer de InnoDB (en realidad, lo mismo que el MVCC de datos completos, ya que el índice agrupado no es más que datos completos).
Pero el índice secundario MVCC usa un enfoque un poco diferente para mantener MVCC. En la actualización del índice secundario, la entrada del índice antiguo se marca para eliminar y los nuevos registros se insertan en el mismo almacenamiento, es decir, la ACTUALIZACIÓN no está en su lugar. Finalmente, las entradas de índice antiguas se eliminan. A estas alturas, es posible que haya notado que el índice secundario MVCC de InnoDB es casi el mismo que el del modelo MVCC de PostgreSQL.
Tipo de índice
InnoDB solo admite el tipo de índice B-Tree y, por lo tanto, no es necesario especificarlo al crear el índice.
Miscelánea:índices hash adaptables
Como se mencionó en la sección anterior, InnoDB solo admite el índice de tipo B-Tree, pero hay un giro. InnoDB tiene la funcionalidad para detectar automáticamente si la consulta puede beneficiarse de la creación de un índice hash y también los datos completos de la tabla pueden caber en la memoria, entonces lo hace automáticamente.
El índice hash se crea utilizando el índice B-Tree existente según la consulta. Si hay varios índices B-Tree secundarios, elegirá el que califique según la consulta. El índice hash creado no está completo, solo genera un índice parcial según el patrón de uso de datos.
Esta es una de las características realmente poderosas para mejorar dinámicamente el rendimiento de las consultas.
Conclusión
El uso de cualquier índice en cualquier base de datos es realmente útil para mejorar el rendimiento de LECTURA pero, al mismo tiempo, degrada el rendimiento de INSERCIÓN/ACTUALIZACIÓN, ya que necesita escribir datos adicionales. Por lo tanto, el índice debe elegirse con mucha prudencia y debe crearse solo si las claves del índice se utilizan como predicado para obtener datos.
InnoDB proporciona una característica muy buena en términos de índice agrupado, que puede ser muy útil según los casos de uso. Además, su indexación hash adaptativa es muy poderosa.
Mientras que PostgreSQL proporciona varios tipos de índices, que realmente pueden brindar opciones de alcance de funciones y uno o todos pueden usarse según el caso de uso comercial. Además, los índices parcial y de expresión son bastante útiles según el caso de uso.