Así es como estos dos enfoques se representarán físicamente en la base de datos:
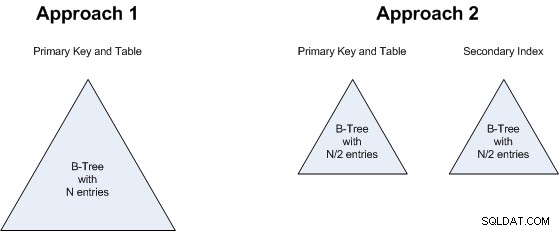
Analicemos ambos enfoques...
Enfoque 1 (ambas direcciones almacenadas en la tabla):
- PRO:Consultas más simples.
- CON:Los datos se pueden corromper insertando/actualizando/eliminando solo una dirección.
- MINOR PRO:no requiere restricciones adicionales para garantizar que una amistad no se pueda duplicar.
- Se necesita más análisis:
- TIE:un índice cubiertas ambas direcciones, por lo que no necesita un índice secundario.
- TIE:requisitos de almacenamiento.
- TIE:Rendimiento.
Enfoque 2 (solo una dirección almacenada en la tabla):
- CON:Consultas más complicadas.
- PRO:No se pueden corromper los datos al olvidar manejar la dirección opuesta, ya que no hay dirección opuesta .
- CONTROL MENOR:Requiere
CHECK(UID < FriendID), por lo que una misma amistad nunca se puede representar de dos formas diferentes, y la clave en(UID, FriendID)puede hacer su trabajo. - Se necesita más análisis:
- TIE:Se necesitan dos índices para cubrir
ambas direcciones de consulta (índice compuesto en
{UID, FriendID}e índice compuesto en{FriendID, UID}). - TIE:requisitos de almacenamiento.
- TIE:Rendimiento.
- TIE:Se necesitan dos índices para cubrir
ambas direcciones de consulta (índice compuesto en
El punto 1 es de especial interés. MySQL/InnoDB siempre clústeres los datos y los índices secundarios pueden ser costosos en las tablas agrupadas (consulte "Desventajas de la agrupación en clústeres" en este artículo ), por lo que podría parecer que el índice secundario en el enfoque 2 consumiría todas las ventajas de tener menos filas. Sin embargo , el índice secundario contiene exactamente los mismos campos que el principal (solo en el orden opuesto), por lo que no hay sobrecarga de almacenamiento en este caso particular. Tampoco hay un puntero al montón de tablas (ya que no hay ningún montón de tablas), por lo que probablemente sea incluso más económico en términos de almacenamiento que un índice normal basado en un montón. Y suponiendo que la consulta esté cubierta con el índice, tampoco habrá una búsqueda doble normalmente asociada con un índice secundario en una tabla agrupada. Entonces, esto es básicamente un empate (ni el enfoque 1 ni el enfoque 2 tienen una ventaja significativa).
El punto 2 está relacionado con el punto 1:no importa si tendremos un B-Tree de N valores o dos B-Tree, cada uno con N/2 valores. Así que esto también es un empate:ambos enfoques consumirán aproximadamente la misma cantidad de almacenamiento.
El mismo razonamiento se aplica al punto 3 :ya sea que busquemos un B-Tree más grande o 2 más pequeños, no hay mucha diferencia, así que esto también es un empate.
Entonces, por la robustez, y a pesar de las consultas algo más feas y la necesidad de CHECK adicional , me quedaría con el enfoque 2.