Como no ha proporcionado el esquema para results , asumiré que es esto o algo muy similar (tal vez columnas adicionales):
create table results (
id int primary key,
user int,
foreign key (user) references <some_other_table>(id),
keyword varchar(<30>)
);
keyword/user como en su consulta de ejemplo, pero para todas las palabras clave:
create view user_keyword as (
select
keyword,
user,
count(*) as magnitude
from results
group by keyword, user
);
create view keyword_user_ranked as (
select
keyword,
user,
magnitude,
(select count(*)
from user_keyword
where l.keyword = keyword and magnitude >= l.magnitude
) as rank
from
user_keyword l
);
Paso 3: seleccione solo las filas donde el rango es menor que algún número:
select *
from keyword_user_ranked
where rank <= 3;
Ejemplo:
Datos base utilizados:
mysql> select * from results;
+----+------+---------+
| id | user | keyword |
+----+------+---------+
| 1 | 1 | mysql |
| 2 | 1 | mysql |
| 3 | 2 | mysql |
| 4 | 1 | query |
| 5 | 2 | query |
| 6 | 2 | query |
| 7 | 2 | query |
| 8 | 1 | table |
| 9 | 2 | table |
| 10 | 1 | table |
| 11 | 3 | table |
| 12 | 3 | mysql |
| 13 | 3 | query |
| 14 | 2 | mysql |
| 15 | 1 | mysql |
| 16 | 1 | mysql |
| 17 | 3 | query |
| 18 | 4 | mysql |
| 19 | 4 | mysql |
| 20 | 5 | mysql |
+----+------+---------+
Agrupados por palabra clave y usuario:
mysql> select * from user_keyword order by keyword, magnitude desc;
+---------+------+-----------+
| keyword | user | magnitude |
+---------+------+-----------+
| mysql | 1 | 4 |
| mysql | 2 | 2 |
| mysql | 4 | 2 |
| mysql | 3 | 1 |
| mysql | 5 | 1 |
| query | 2 | 3 |
| query | 3 | 2 |
| query | 1 | 1 |
| table | 1 | 2 |
| table | 2 | 1 |
| table | 3 | 1 |
+---------+------+-----------+
Usuarios clasificados dentro de las palabras clave:
mysql> select * from keyword_user_ranked order by keyword, rank asc;
+---------+------+-----------+------+
| keyword | user | magnitude | rank |
+---------+------+-----------+------+
| mysql | 1 | 4 | 1 |
| mysql | 2 | 2 | 3 |
| mysql | 4 | 2 | 3 |
| mysql | 3 | 1 | 5 |
| mysql | 5 | 1 | 5 |
| query | 2 | 3 | 1 |
| query | 3 | 2 | 2 |
| query | 1 | 1 | 3 |
| table | 1 | 2 | 1 |
| table | 3 | 1 | 3 |
| table | 2 | 1 | 3 |
+---------+------+-----------+------+
Solo los 2 mejores de cada palabra clave:
mysql> select * from keyword_user_ranked where rank <= 2 order by keyword, rank asc;
+---------+------+-----------+------+
| keyword | user | magnitude | rank |
+---------+------+-----------+------+
| mysql | 1 | 4 | 1 |
| query | 2 | 3 | 1 |
| query | 3 | 2 | 2 |
| table | 1 | 2 | 1 |
+---------+------+-----------+------+
Tenga en cuenta que cuando hay empates (consulte los usuarios 2 y 4 para la palabra clave "mysql" en los ejemplos), todas las partes en el empate obtienen el "último" rango, es decir, si el segundo y el tercero están empatados, a ambos se les asigna el rango 3.
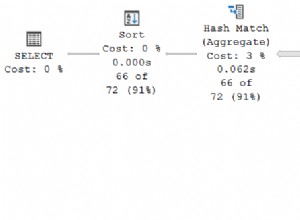
Rendimiento:será útil agregar un índice a las columnas de palabras clave y usuarios. Tengo una tabla consultada de manera similar con 4000 y 1300 valores distintos para las dos columnas (en una tabla de 600000 filas). Puede agregar el índice de esta manera:
alter table results add index keyword_user (keyword, user);
En mi caso, el tiempo de consulta se redujo de unos 6 segundos a unos 2 segundos.