Yo lo haría de la siguiente manera:
-
Cree una tabla temporal a partir de su tabla existente:
CREATE TEMPORARY TABLE data_to_keep LIKE table_with_dupes_in_it -
Rellene la tabla temporal solo con los registros que desee:
INSERT INTO data_to_keep SELECT DISTINCT * FROM table_with_dupes_in_it -
Vaciar la mesa
TRUNCATE TABLE table_with_dupes_in_it -
Devolver los datos de la tabla temporal a la tabla original
INSERT INTO table_with_dupes_in_it SELECT * FROM data_to_keep; -
Limpiar
DROP TEMPORARY TABLE data_to_keep
Tenga en cuenta que esto puede consumir una gran cantidad de memoria y/o almacenamiento si la tabla en cuestión es grande. Si se trata de una tabla grande, me inclinaría a usar una tabla real en lugar de una tabla temporal para no consumir cantidades excesivas de memoria en su servidor DB.
EDITAR PARA AÑADIR:
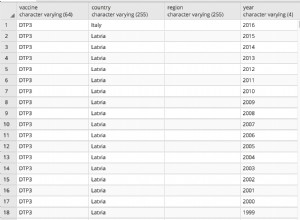
Si solo le preocupan los duplicados parciales (filas en las que solo algunos de los datos son idénticos a los datos ingresados anteriormente), querrá usar GROUP BY. Cuando usa GROUP BY, puede limitar MySQL para devolver solo una fila que contenga datos dados en lugar de todos ellos.
SELECT *
FROM table
GROUP BY column_name
También debe considerar usar índices ÚNICOS en las columnas que no desea que contengan datos duplicados, esto evitará que los usuarios inserten datos duplicados en primer lugar.