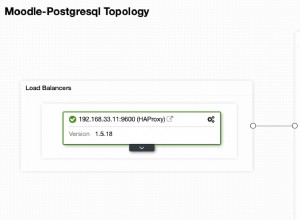
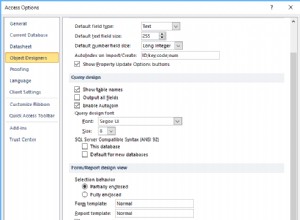
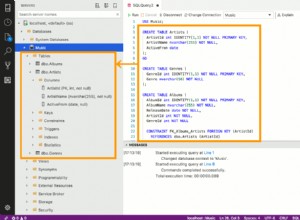
Parece estar interesado en:
-- a and b are related by the association of interest
Foo(a, b)
-- foo(a, b) but not foo(a2, b) for some a2 <> a
Boring(a, b)
unique(b)
FK (a, b) references Foo
-- foo(a, b) and foo(a2, b) for some a2 <> a
Rare(a, b)
FK (a, b) references foo
Si desea consultas para estar libre de obstáculos, basta con definir Foo. Puedes consultarlo por Raro.
Rare = select * from Foo f join Foo f2
where f.a <> f2.a and f.b = f2.b
Cualquier otro diseño sufre de la complejidad de la actualización para mantener la base de datos consistente.
Tienes cierta preocupación acerca de que Rare sea mucho más pequeño que Foo. Pero, ¿cuál es su requisito hay solo n en un millón de discos de Foo siendo muchos:¿muchos por los cuales elegirías algún otro diseño?
El siguiente nivel de complejidad es tener Foo y Rare. Las actualizaciones deben mantener verdadera la ecuación anterior.
Parece extremadamente improbable que haya un beneficio en reducir la redundancia de 2 o 3 en un millón de Foo + Rare teniendo solo Boring + Rare y reconstruyendo Foo a partir de ellos. Pero puede ser beneficioso definir un índice único (b) para Boring que mantendrá que una b en él tiene solo una a. Cuando necesites Foo:
Foo = select * from Boring union select * from Rare
Pero tus actualizaciones deben mantener eso
not exists (select * from Boring b join Rare r where b.b = r.b)