Inmediatamente después de publicar esto, realicé otra consulta para verificar una sospecha:
SELECT * FROM pg_timezone_abbrevs
WHERE abbrev IN ('CEST', 'CET');
abbrev | utc_offset | is_dst
--------+------------+--------
CEST | 02:00:00 | t
CET | 01:00:00 | f
Resulta que hay también una abreviatura de zona horaria llamado CET (lo cual tiene sentido, "CET" es una abreviatura). Y parece que PostgreSQL elige la abreviatura sobre el nombre completo. Entonces, aunque encontré CET en la zona horaria nombres , la expresión '2012-01-18 1:0 CET'::timestamptz se interpreta de acuerdo con las reglas sutilmente diferentes para las abreviaturas de zona horaria .
SELECT '2012-01-18 1:0 CEST'::timestamptz(0)
,'2012-01-18 1:0 CET'::timestamptz(0)
,'2012-01-18 1:0 Europe/Vienna'::timestamptz(0);
timestamptz | timestamptz | timestamptz
------------------------+------------------------+------------------------
2012-01-18 00:00:00+01 | 2012-01-18 01:00:00+01 | 2012-01-18 01:00:00+01
SELECT '2012-08-18 1:0 CEST'::timestamptz(0)
,'2012-08-18 1:0 CET'::timestamptz(0)
,'2012-08-18 1:0 Europe/Vienna'::timestamptz(0);
timestamptz | timestamptz | timestamptz
------------------------+------------------------+------------------------
2012-08-18 01:00:00+02 | 2012-08-18 02:00:00+02 | 2012-08-18 01:00:00+02
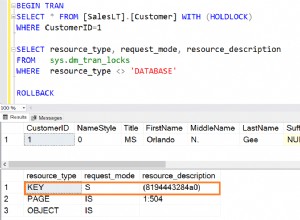
Encuentro 10 casos de zonas horarias abreviaturas en la zona horaria nombres y no entiendo por qué están ahí. ¿Cuál es el propósito?
Entre ellos, el desplazamiento de tiempo (utc_offset ) no está de acuerdo en cuatro casos debido a la configuración del horario de verano:
SELECT n.*, a.*
FROM pg_timezone_names n
JOIN pg_timezone_abbrevs a ON a.abbrev = n.name
WHERE n.utc_offset <> a.utc_offset;
name | abbrev | utc_offset | is_dst | abbrev | utc_offset | is_dst
------+--------+------------+--------+--------+------------+--------
CET | CEST | 02:00:00 | t | CET | 01:00:00 | f
EET | EEST | 03:00:00 | t | EET | 02:00:00 | f
MET | MEST | 02:00:00 | t | MET | 01:00:00 | f
WET | WEST | 01:00:00 | t | WET | 00:00:00 | f
En estos casos, las personas pueden ser engañadas (como yo lo fui), buscando el tz nombre y encontrar un desplazamiento de tiempo que no se aplica realmente. Ese es un diseño desafortunado:si no es un error, al menos es un error de documentación. .
No encuentro nada en el manual sobre cómo las ambigüedades entre los nombres de la zona horaria y abreviaturas se resuelven. Obviamente, las abreviaturas tienen prioridad.
Apéndice B.1. La interpretación de entrada de fecha/hora menciona la búsqueda de abreviaturas de zona horaria, pero sigue siendo poco clara cómo la zona horaria nombres están identificados y cuál de ellos tiene prioridad en caso de un token ambiguo.
Si el token es una cadena de texto, haga coincidir con cadenas posibles:
Haga una búsqueda en la tabla de búsqueda binaria para el token como una abreviatura de zona horaria.
Bueno, hay un ligero indicio en esta oración de que las abreviaturas van primero, pero nada definitivo. Además, hay una columna abbrev en ambas tablas, pg_timezone_names y pg_timezone_abbrevs ...