Actualización:en PostgreSQL 9.4 esto mejora mucho con la introducción de to_json , json_build_object , json_object y json_build_array , aunque es detallado debido a la necesidad de nombrar todos los campos explícitamente:
select
json_build_object(
'id', u.id,
'name', u.name,
'email', u.email,
'user_role_id', u.user_role_id,
'user_role', json_build_object(
'id', ur.id,
'name', ur.name,
'description', ur.description,
'duty_id', ur.duty_id,
'duty', json_build_object(
'id', d.id,
'name', d.name
)
)
)
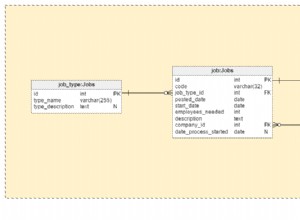
from users u
inner join user_roles ur on ur.id = u.user_role_id
inner join role_duties d on d.id = ur.duty_id;
Para versiones anteriores, sigue leyendo.
No se limita a una sola fila, es solo un poco doloroso. No puede alias tipos de filas compuestas usando AS , por lo que debe usar una expresión de subconsulta con alias o CTE para lograr el efecto:
select row_to_json(row)
from (
select u.*, urd AS user_role
from users u
inner join (
select ur.*, d
from user_roles ur
inner join role_duties d on d.id = ur.duty_id
) urd(id,name,description,duty_id,duty) on urd.id = u.user_role_id
) row;
produce, a través de https://jsonprettyprint.com/:
{
"id": 1,
"name": "Dan",
"email": "example@sqldat.com",
"user_role_id": 1,
"user_role": {
"id": 1,
"name": "admin",
"description": "Administrative duties in the system",
"duty_id": 1,
"duty": {
"id": 1,
"name": "Script Execution"
}
}
}
Querrás usar array_to_json(array_agg(...)) cuando tienes una relación de 1:muchos, por cierto.
Idealmente, la consulta anterior debería poder escribirse como:
select row_to_json(
ROW(u.*, ROW(ur.*, d AS duty) AS user_role)
)
from users u
inner join user_roles ur on ur.id = u.user_role_id
inner join role_duties d on d.id = ur.duty_id;
... pero ROW de PostgreSQL el constructor no acepta AS alias de columna. Tristemente.
Afortunadamente, optimizan lo mismo. Compara los planes:
- La versión de la subconsulta anidada; contra
- El último
ROWanidado versión del constructor con los alias eliminados para que se ejecute
Dado que los CTE son barreras de optimización, reformular la versión de la subconsulta anidada para usar CTE encadenados (WITH expresiones) pueden no funcionar tan bien y no darán como resultado el mismo plan. En este caso, está atascado con subconsultas anidadas feas hasta que obtengamos algunas mejoras en row_to_json o una forma de anular los nombres de las columnas en un ROW constructor más directamente.
De todos modos, en general, el principio es que donde quieras crear un objeto json con columnas a, b, c , y desearía poder escribir la sintaxis ilegal:
ROW(a, b, c) AS outername(name1, name2, name3)
en su lugar, puede usar subconsultas escalares que devuelvan valores de tipo fila:
(SELECT x FROM (SELECT a AS name1, b AS name2, c AS name3) x) AS outername
O:
(SELECT x FROM (SELECT a, b, c) AS x(name1, name2, name3)) AS outername
Además, tenga en cuenta que puede componer json valores sin cotizaciones adicionales, p. si pones la salida de un json_agg dentro de un row_to_json , el json_agg interno El resultado no se citará como una cadena, se incorporará directamente como json.
p.ej. en el ejemplo arbitrario:
SELECT row_to_json(
(SELECT x FROM (SELECT
1 AS k1,
2 AS k2,
(SELECT json_agg( (SELECT x FROM (SELECT 1 AS a, 2 AS b) x) )
FROM generate_series(1,2) ) AS k3
) x),
true
);
la salida es:
{"k1":1,
"k2":2,
"k3":[{"a":1,"b":2},
{"a":1,"b":2}]}
Tenga en cuenta que json_agg producto, [{"a":1,"b":2}, {"a":1,"b":2}] , no se ha vuelto a escapar, como text sería.
Esto significa que puedes componer json para construir filas, no siempre tiene que crear tipos compuestos de PostgreSQL enormemente complejos y luego llamar a row_to_json en la salida.