Uno de los requisitos principales para cualquier base de datos es lograr la escalabilidad. Solo se puede lograr si la contención (bloqueo) se minimiza tanto como sea posible, si no se elimina por completo. Dado que la lectura/escritura/actualización/eliminación son algunas de las principales operaciones frecuentes que ocurren en la base de datos, es muy importante que estas operaciones se realicen al mismo tiempo sin que se bloqueen. Para lograr esto, la mayoría de las principales bases de datos emplean un modelo de concurrencia llamado Control de concurrencia de múltiples versiones. lo que reduce la contención a un nivel mínimo.
¿Qué es MVCC?
El control de concurrencia de múltiples versiones (de aquí en adelante, MVCC) es un algoritmo que proporciona un control preciso de la concurrencia mediante el mantenimiento de múltiples versiones del mismo objeto para que las operaciones de LECTURA y ESCRITURA no entren en conflicto. Aquí ESCRIBIR significa ACTUALIZAR y ELIMINAR, ya que el registro recién INSERTADO de todos modos estará protegido según el nivel de aislamiento. Cada operación de ESCRITURA produce una nueva versión del objeto y cada operación de lectura simultánea lee una versión diferente del objeto según el nivel de aislamiento. Dado que la lectura y la escritura operan en diferentes versiones del mismo objeto, ninguna de estas operaciones requiere un bloqueo completo y, por lo tanto, ambas pueden operar simultáneamente. El único caso en el que la disputa aún puede existir es cuando dos transacciones simultáneas intentan ESCRIBIR el mismo registro.
La mayor parte de la base de datos principal actual es compatible con MVCC. La intención de este algoritmo es mantener múltiples versiones del mismo objeto, por lo que la implementación de MVCC difiere de una base de datos a otra solo en términos de cómo se crean y mantienen múltiples versiones. En consecuencia, la operación de base de datos correspondiente y el almacenamiento de cambios de datos.
El enfoque más reconocido para implementar MVCC es el utilizado por PostgreSQL y Firebird/Interbase y otro utilizado por InnoDB y Oracle. En secciones posteriores, discutiremos en detalle cómo se ha implementado en PostgreSQL e InnoDB.
MVCC en PostgreSQL
Para admitir múltiples versiones, PostgreSQL mantiene campos adicionales para cada objeto (Tupla en la terminología de PostgreSQL) como se menciona a continuación:
- xmin:ID de transacción de la transacción que insertó o actualizó la tupla. En caso de ACTUALIZAR, se asigna una versión más reciente de la tupla con este ID de transacción.
- xmax:ID de transacción de la transacción que eliminó o actualizó la tupla. En caso de ACTUALIZAR, se asigna este ID de transacción a una versión existente de la tupla. En una tupla recién creada, el valor predeterminado de este campo es nulo.
PostgreSQL almacena todos los datos en un almacenamiento primario llamado HEAP (página de tamaño predeterminado de 8 KB). Toda la tupla nueva obtiene xmin como una transacción que la creó y la tupla de la versión anterior (que se actualizó o eliminó) se asigna con xmax. Siempre hay un enlace desde la tupla de la versión anterior a la nueva versión. La tupla de la versión anterior se puede usar para recrear la tupla en caso de reversión y para leer una versión anterior de una tupla mediante la declaración READ según el nivel de aislamiento.
Considere que hay dos tuplas, T1 (con valor 1) y T2 (con valor 2) para una tabla, la creación de nuevas filas se puede demostrar en los siguientes 3 pasos:
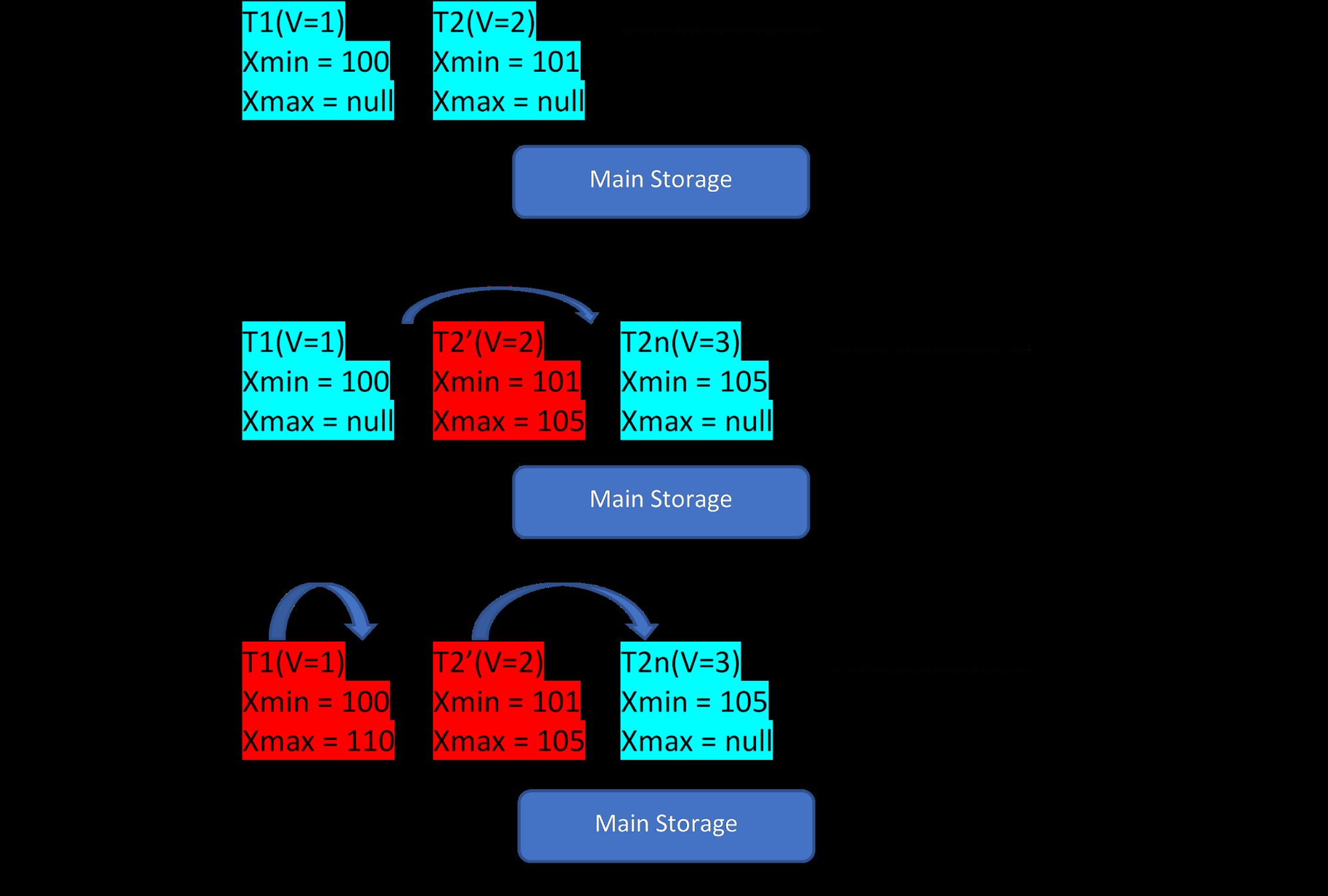 MVCC:Almacenamiento de múltiples versiones en PostgreSQL
MVCC:Almacenamiento de múltiples versiones en PostgreSQL Como se ve en la imagen, inicialmente hay dos tuplas en la base de datos con valores 1 y 2.
Luego, en el segundo paso, la fila T2 con el valor 2 se actualiza con el valor 3. En este punto, se crea una nueva versión con el nuevo valor y se almacena junto a la tupla existente en la misma área de almacenamiento. . Antes de eso, la versión anterior se asigna con xmax y apunta a la tupla de la última versión.
De manera similar, en el tercer paso, cuando se elimina la fila T1 con el valor 1, la fila existente se elimina virtualmente (es decir, solo se le asignó xmax con la transacción actual) en el mismo lugar. No se crea una nueva versión para esto.
A continuación, veamos cómo cada operación crea múltiples versiones y cómo se mantiene el nivel de aislamiento de la transacción sin bloqueo con algunos ejemplos reales. En todos los ejemplos a continuación, se usa el aislamiento "LECTURA COMPROMETIDA" de forma predeterminada.
INSERTAR
Cada vez que se inserte un registro, se creará una nueva tupla, que se agregará a una de las páginas pertenecientes a la tabla correspondiente.
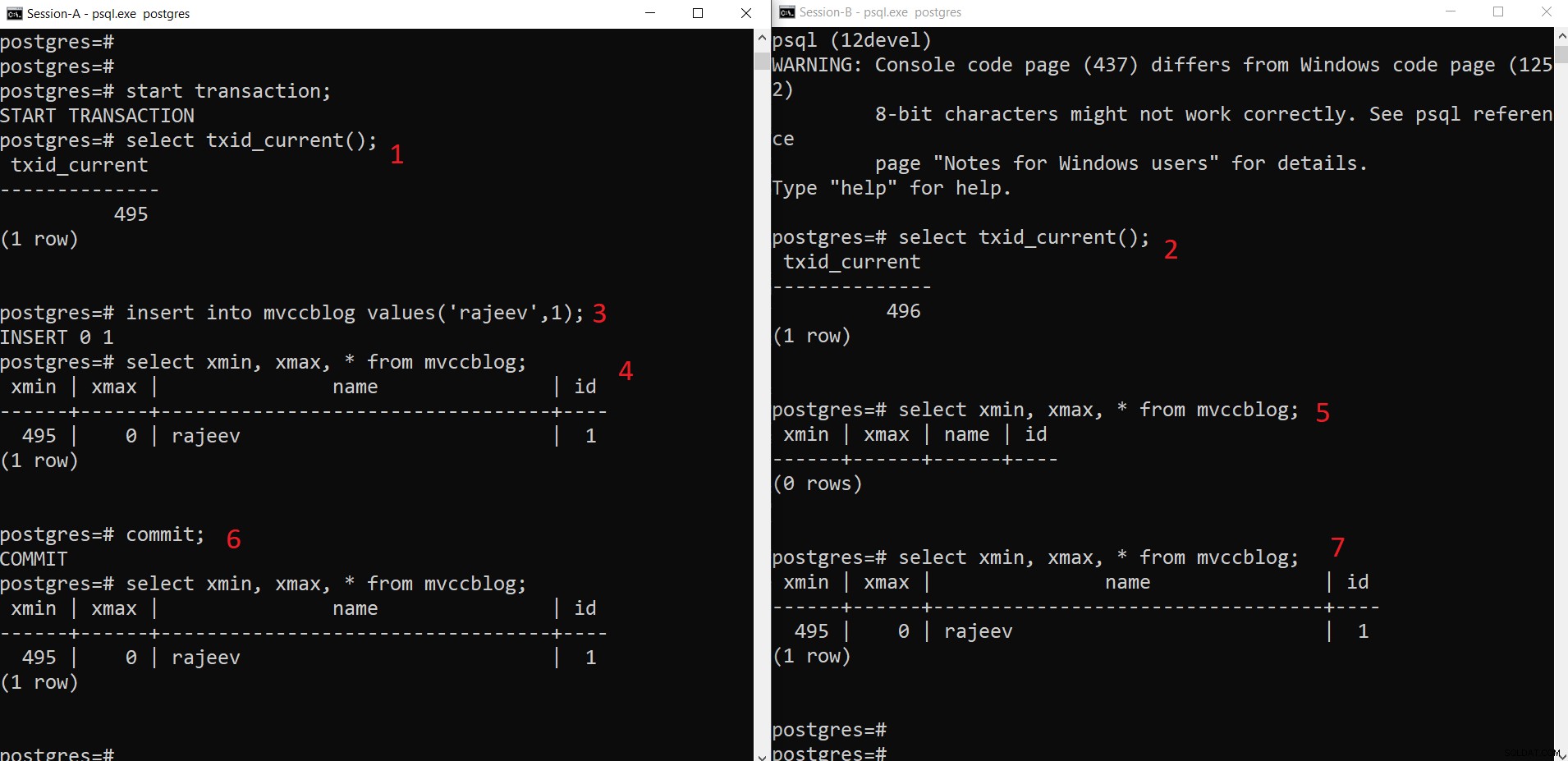 Operación INSERT simultánea de PostgreSQL
Operación INSERT simultánea de PostgreSQL Como podemos ver aquí paso a paso:
- La sesión A inicia una transacción y obtiene el ID de transacción 495.
- La sesión B inicia una transacción y obtiene el ID de transacción 496.
- Sesión-A inserta una nueva tupla (se almacena en HEAP)
- Ahora, se agrega la nueva tupla con xmin establecida en el ID de transacción actual 495.
- Pero lo mismo no es visible desde la Sesión-B ya que xmin (es decir, 495) aún no se ha confirmado.
- Una vez confirmado.
- Los datos son visibles para ambas sesiones.
ACTUALIZAR
La ACTUALIZACIÓN de PostgreSQL no es una actualización "EN EL LUGAR", es decir, no modifica el objeto existente con el nuevo valor requerido. En su lugar, crea una nueva versión del objeto. Por lo tanto, ACTUALIZAR implica en términos generales los siguientes pasos:
- Marca el objeto actual como eliminado.
- Luego agrega una nueva versión del objeto.
- Redirige la versión anterior del objeto a una nueva versión.
Entonces, aunque una cantidad de registros permanece igual, HEAP ocupa espacio como si se hubiera insertado un registro más.
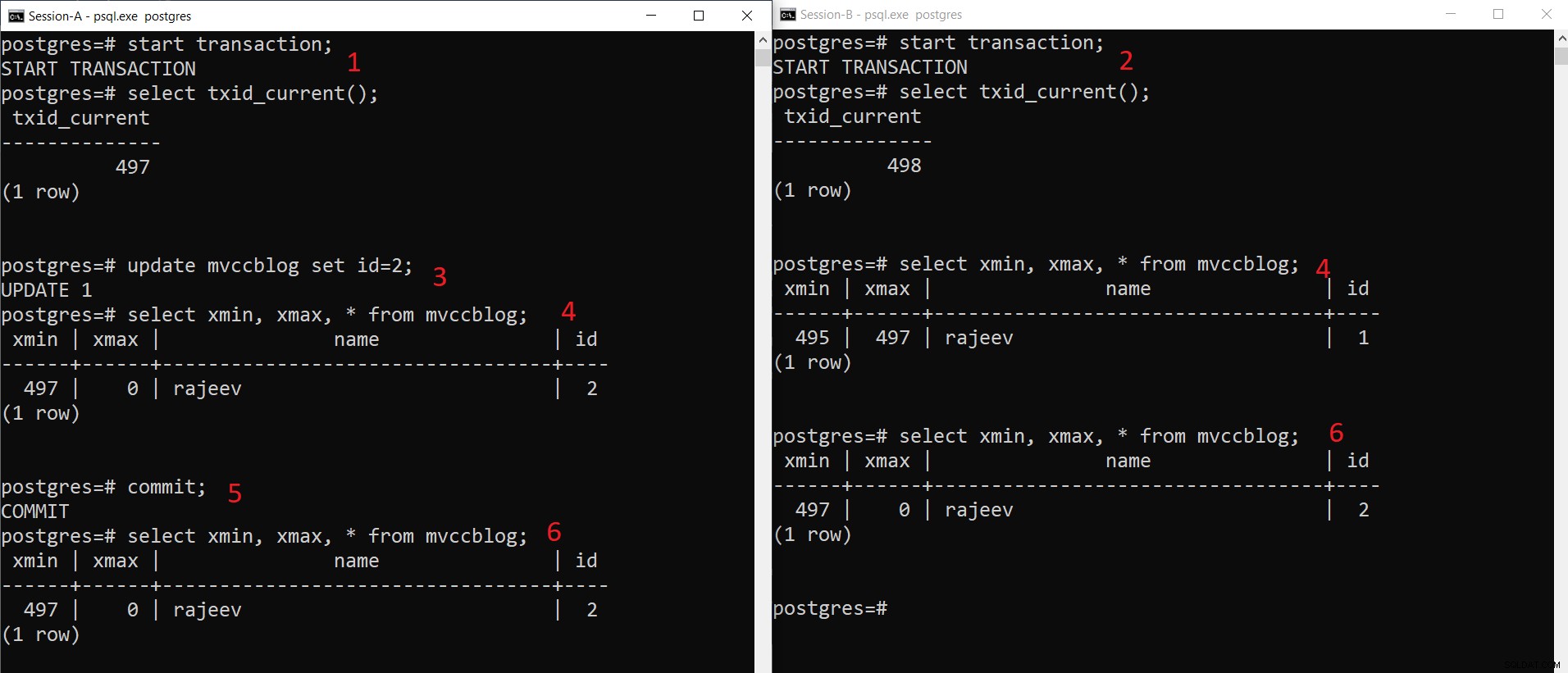 Operación INSERT simultánea de PostgreSQL
Operación INSERT simultánea de PostgreSQL Como podemos ver aquí paso a paso:
- La sesión A inicia una transacción y obtiene el ID de transacción 497.
- La sesión B inicia una transacción y obtiene el ID de transacción 498.
- La Sesión-A actualiza el registro existente.
- Aquí, la sesión A ve una versión de la tupla (tupla actualizada) mientras que la sesión B ve otra versión (tupla más antigua pero xmax establecido en 497). Ambas versiones de tupla se almacenan en el almacenamiento HEAP (incluso en la misma página dependiendo de la disponibilidad de espacio)
- Una vez que Session-A confirma la transacción, la tupla anterior caduca ya que se confirma xmax de la tupla anterior.
- Ahora ambas sesiones ven la misma versión del registro.
ELIMINAR
Eliminar es casi como la operación de ACTUALIZAR excepto que no tiene que agregar una nueva versión. Simplemente marca el objeto actual como ELIMINADO como se explica en el caso de ACTUALIZAR.
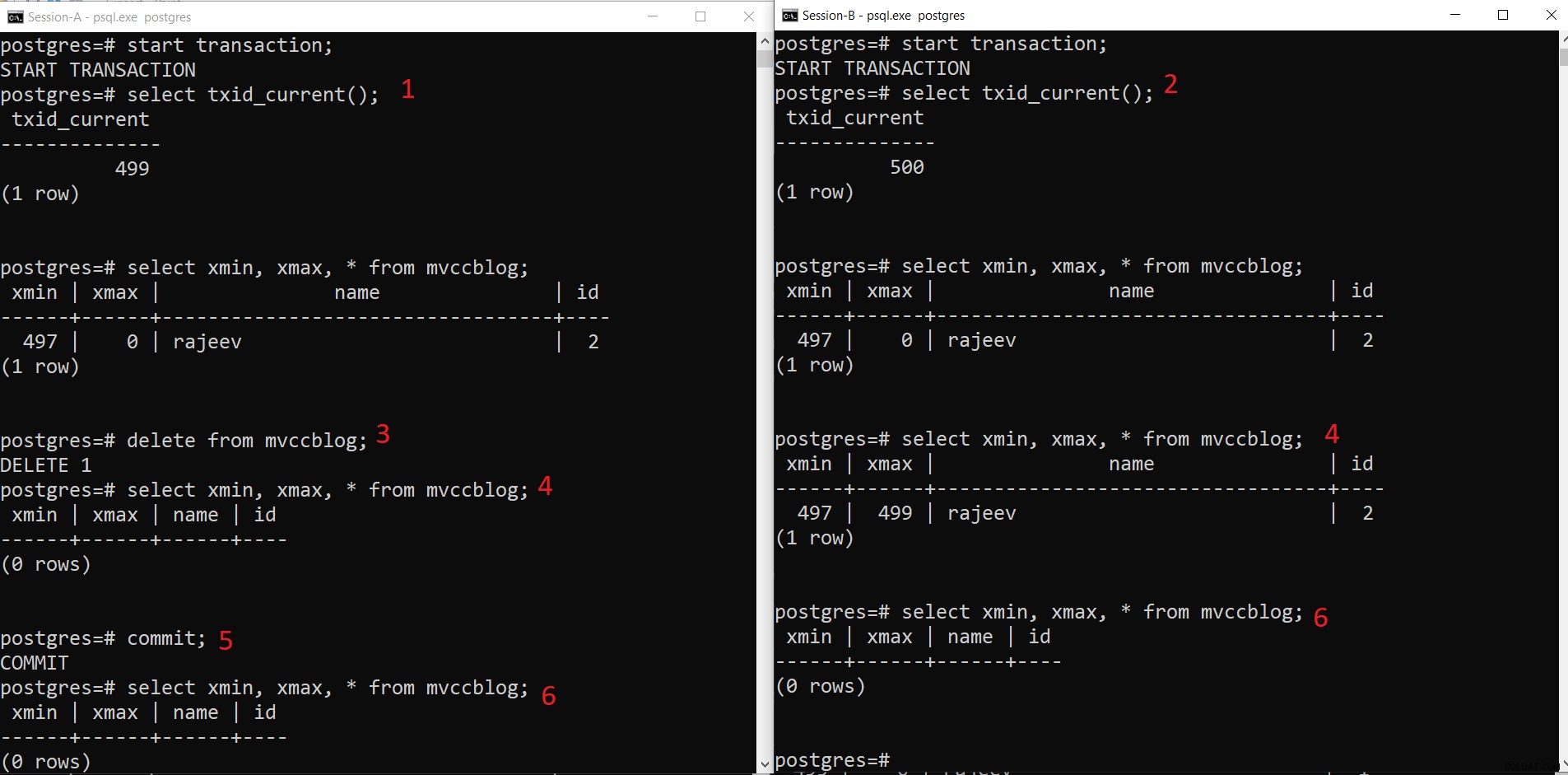 Operación de ELIMINACIÓN simultánea de PostgreSQL
Operación de ELIMINACIÓN simultánea de PostgreSQL - La sesión A inicia una transacción y obtiene el ID de transacción 499.
- La sesión B inicia una transacción y obtiene el ID de transacción 500.
- La Sesión-A elimina el registro existente.
- Aquí Session-A no ve ninguna tupla eliminada de la transacción actual. Mientras que Session-B ve una versión anterior de la tupla (con xmax como 499; la transacción que eliminó este registro).
- Una vez que Session-A confirma la transacción, la tupla anterior caduca ya que se confirma xmax de la tupla anterior.
- Ahora ambas sesiones no ven la tupla eliminada.
Como podemos ver, ninguna de las operaciones elimina la versión existente del objeto directamente y, donde sea necesario, agrega una versión adicional del objeto.
Ahora, veamos cómo se ejecuta la consulta SELECT en una tupla que tiene múltiples versiones:SELECT necesita leer todas las versiones de la tupla hasta que encuentre la tupla adecuada según el nivel de aislamiento. Supongamos que hubo una tupla T1, que se actualizó y creó una nueva versión T1’ y que a su vez creó T1’’ en la actualización:
- La operación SELECT pasará por el almacenamiento en montón para esta tabla y primero comprobará T1. Si se confirma la transacción T1 xmax, se mueve a la siguiente versión de esta tupla.
- Supongamos que ahora la tupla xmax de T1 también está confirmada, y luego vuelve a pasar a la siguiente versión de esta tupla.
- Finalmente, encuentra T1'' y ve que xmax no está comprometido (o es nulo) y T1'' xmin es visible para la transacción actual según el nivel de aislamiento. Finalmente, leerá la tupla T1''.
Como podemos ver, necesita atravesar las 3 versiones de la tupla para encontrar la tupla visible adecuada hasta que el recolector de elementos no utilizados (VACUUM) elimine la tupla caducada.
MVCC en InnoDB
Para admitir múltiples versiones, InnoDB mantiene campos adicionales para cada fila como se menciona a continuación:
- DB_TRX_ID:ID de transacción de la transacción que insertó o actualizó la fila.
- DB_ROLL_PTR:también se denomina puntero de rollo y apunta a deshacer el registro escrito en el segmento de retroceso (más sobre esto a continuación).
Al igual que PostgreSQL, InnoDB también crea varias versiones de la fila como parte de todas las operaciones, pero el almacenamiento de la versión anterior es diferente.
En el caso de InnoDB, la versión anterior de la fila modificada se mantiene en un espacio de tabla/almacenamiento separado (llamado segmento de deshacer). Entonces, a diferencia de PostgreSQL, InnoDB mantiene solo la última versión de las filas en el área de almacenamiento principal y la versión anterior se mantiene en el segmento de deshacer. Las versiones de fila del segmento de deshacer se utilizan para deshacer la operación en caso de reversión y para leer una versión anterior de filas mediante la instrucción READ según el nivel de aislamiento.
Considere que hay dos filas, T1 (con valor 1) y T2 (con valor 2) para una tabla, la creación de nuevas filas se puede demostrar en los siguientes 3 pasos:
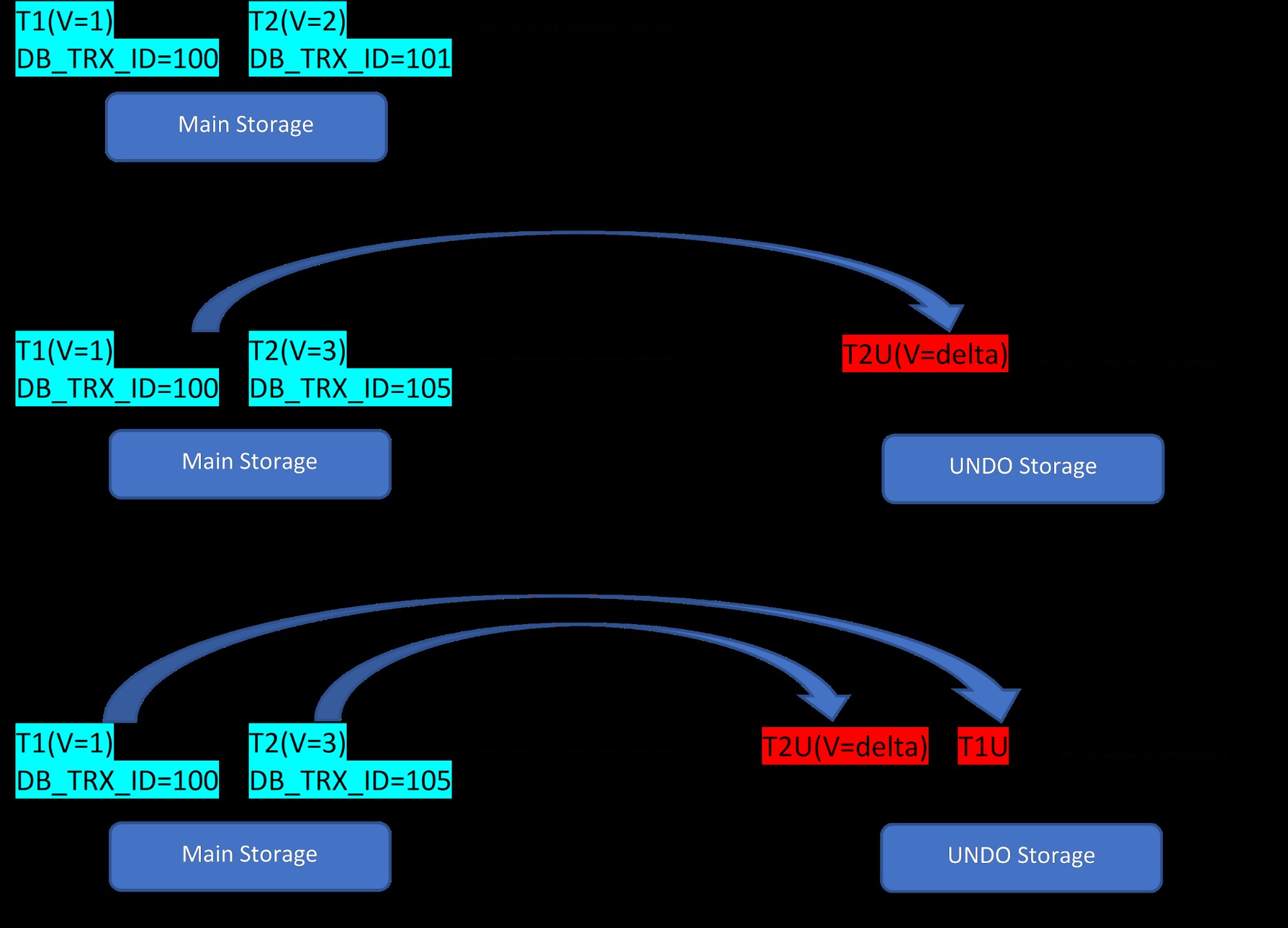 MVCC:Almacenamiento de múltiples versiones en InnoDB
MVCC:Almacenamiento de múltiples versiones en InnoDB Como se ve en la figura, inicialmente hay dos filas en la base de datos con valores 1 y 2.
Luego, según la segunda etapa, la fila T2 con el valor 2 se actualiza con el valor 3. En este punto, se crea una nueva versión con el nuevo valor y reemplaza la versión anterior. Antes de eso, la versión anterior se almacena en el segmento de deshacer (observe que la versión del segmento de DESHACER solo tiene un valor delta). Además, tenga en cuenta que hay un puntero de la nueva versión a la versión anterior en el segmento de reversión. Entonces, a diferencia de PostgreSQL, la actualización de InnoDB es "IN SITU".
De manera similar, en el tercer paso, cuando se elimina la fila T1 con el valor 1, la fila existente se elimina virtualmente (es decir, solo marca un bit especial en la fila) en el área de almacenamiento principal y se agrega una nueva versión correspondiente a esto. el segmento Deshacer. Una vez más, hay un puntero de rollo desde el almacenamiento principal hasta el segmento de deshacer.
Todas las operaciones se comportan de la misma manera que en el caso de PostgreSQL visto desde el exterior. Solo difiere el almacenamiento interno de varias versiones.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoMVCC:PostgreSQL frente a InnoDB
Ahora, analicemos cuáles son las principales diferencias entre PostgreSQL e InnoDB en términos de su implementación de MVCC:
-
Tamaño de una versión anterior
PostgreSQL solo actualiza xmax en la versión anterior de la tupla, por lo que el tamaño de la versión anterior sigue siendo el mismo para el registro insertado correspondiente. Esto significa que si tiene 3 versiones de una tupla anterior, todas tendrán el mismo tamaño (excepto la diferencia en el tamaño real de los datos, si la hay, en cada actualización).
Mientras que en el caso de InnoDB, la versión del objeto almacenada en el segmento Deshacer suele ser más pequeña que el registro insertado correspondiente. Esto se debe a que solo los valores modificados (es decir, diferenciales) se escriben en el registro UNDO.
-
Operación INSERTAR
InnoDB necesita escribir un registro adicional en el segmento DESHACER incluso para INSERTAR, mientras que PostgreSQL crea una nueva versión solo en caso de ACTUALIZAR.
-
Restaurar una versión anterior en caso de reversión
PostgreSQL no necesita nada específico para restaurar una versión anterior en caso de reversión. Recuerde que la versión anterior tiene xmax igual a la transacción que actualizó esta tupla. Por lo tanto, hasta que se confirme esta identificación de transacción, se considera una tupla activa para una instantánea simultánea. Una vez que se revierte la transacción, la transacción correspondiente se considerará activa automáticamente para todas las transacciones, ya que será una transacción abortada.
Mientras que en el caso de InnoDB, se requiere explícitamente reconstruir la versión anterior del objeto una vez que ocurre la reversión.
-
Recuperación del espacio ocupado por una versión anterior
En el caso de PostgreSQL, el espacio ocupado por una versión anterior puede considerarse muerto solo cuando no hay una instantánea paralela para leer esta versión. Una vez que la versión anterior está muerta, la operación VACÍO puede recuperar el espacio ocupado por ellos. VACUUM se puede activar manualmente o como una tarea en segundo plano según la configuración.
Los registros de UNDO de InnoDB se dividen principalmente en INSERT UNDO y UPDATE UNDO. El primero se descarta tan pronto como se confirma la transacción correspondiente. El segundo debe conservarse hasta que sea paralelo a cualquier otra instantánea. InnoDB no tiene una operación de VACÍO explícita, pero en una línea similar tiene una PURGA asíncrona para descartar los registros de DESHACER que se ejecutan como una tarea en segundo plano.
-
Impacto del vacío retardado
Como se discutió en un punto anterior, existe un gran impacto del vacío retrasado en el caso de PostgreSQL. Hace que la tabla comience a inflarse y que aumente el espacio de almacenamiento aunque los registros se eliminen constantemente. También puede llegar a un punto en el que sea necesario realizar VACUUM FULL, lo que es una operación muy costosa.
-
Escaneo secuencial en caso de tabla inflada
El escaneo secuencial de PostgreSQL debe atravesar todas las versiones anteriores de un objeto, aunque todas estén muertas (hasta que se eliminen mediante vacío). Este es el problema típico y más comentado en PostgreSQL. Recuerde que PostgreSQL almacena todas las versiones de una tupla en el mismo almacenamiento.
Mientras que en el caso de InnoDB, no necesita leer el registro Deshacer a menos que sea necesario. En caso de que todos los registros de deshacer estén muertos, solo será suficiente leer la última versión de los objetos.
-
Índice
PostgreSQL almacena el índice en un almacenamiento separado que mantiene un enlace a los datos reales en HEAP. Entonces, PostgreSQL también tiene que actualizar la parte INDEX aunque no hubo cambios en INDEX. Aunque más tarde, este problema se solucionó implementando la actualización HOT (Heap Only Tuple), pero aún tiene la limitación de que si una nueva tupla de montón no se puede acomodar en la misma página, entonces vuelve a la ACTUALIZACIÓN normal.
InnoDB no tiene este problema ya que usan índice agrupado.
Conclusión
PostgreSQL MVCC tiene algunos inconvenientes, especialmente en términos de almacenamiento inflado si su carga de trabajo tiene ACTUALIZAR/ELIMINAR con frecuencia. Entonces, si decide usar PostgreSQL, debe tener mucho cuidado de configurar VACUUM sabiamente.
La comunidad de PostgreSQL también ha reconocido esto como un problema importante y ya han comenzado a trabajar en el enfoque MVCC basado en UNDO (nombre provisional como ZHEAP) y es posible que veamos lo mismo en una versión futura.