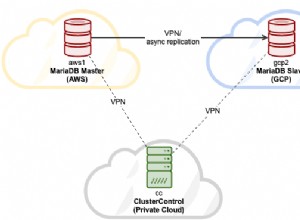
Un entorno de múltiples nubes es una buena opción para un Plan de recuperación ante desastres (DRP), pero puede ser una tarea que requiere mucho tiempo, ya que necesita configurar la conectividad entre los diferentes proveedores de la nube y luego necesita implementar y administrar su clúster de base de datos en dos lugares diferentes.
En este blog, mostraremos cómo realizar una implementación de múltiples nubes para PostgreSQL en dos de los proveedores de nube más populares en este momento, AWS y Google Cloud. Para esta tarea, utilizaremos algunas de las funciones que ClusterControl puede ofrecerle, como el escalado y la replicación de clúster a clúster.
Supondremos que tiene una instalación de ClusterControl ejecutándose y que ya ha creado dos cuentas de proveedor de nube diferentes.
Preparación de su entorno en la nube
Primero, debe crear su entorno en su proveedor de nube principal. En este caso, usaremos AWS con 2 nodos PostgreSQL:

Asegúrese de tener permitido el tráfico SSH y PostgreSQL desde su servidor ClusterControl mediante editando su grupo de seguridad:

Luego, vaya al proveedor de nube secundario y cree al menos una máquina virtual ese será el nodo esclavo. Usaremos Google Cloud Platform con 1 nodo PostgreSQL.

Y nuevamente, asegúrese de permitir el tráfico SSH y PostgreSQL desde su ClusterControl servidor:

En este caso, estamos permitiendo el tráfico sin ninguna restricción en la fuente , pero es solo un ejemplo y no se recomienda en la vida real.
Implemente un clúster de PostgreSQL en la nube
Usaremos ClusterControl para esta tarea, por lo que asumimos que lo tiene instalado.
Vaya a su servidor ClusterControl y seleccione la opción “Implementar”. Si ya tiene una instancia de PostgreSQL ejecutándose, debe seleccionar "Importar servidor/base de datos existente".
Al seleccionar PostgreSQL, debe especificar Usuario, Clave o Contraseña y puerto para conectarse por SSH a sus nodos PostgreSQL. También necesita el nombre de su nuevo clúster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
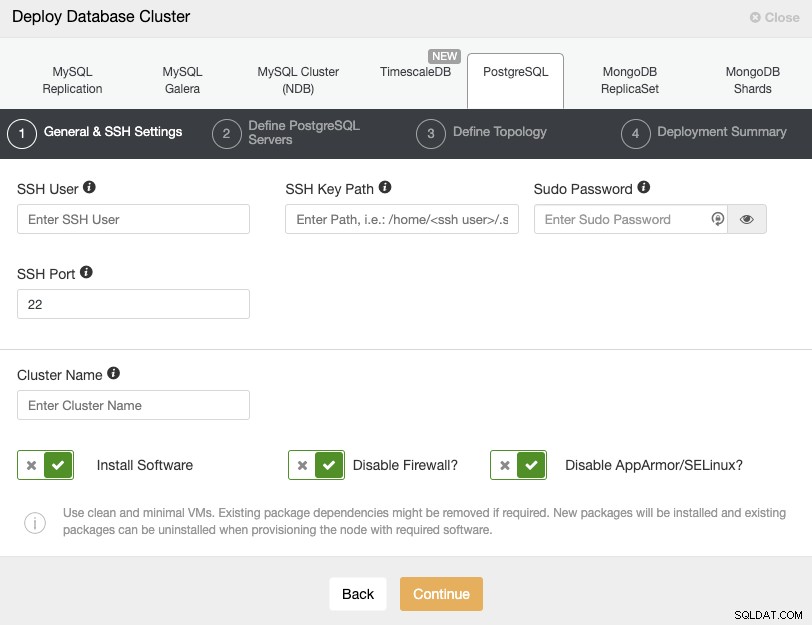
Consulte los requisitos de usuario de ClusterControl para obtener más información sobre este paso.
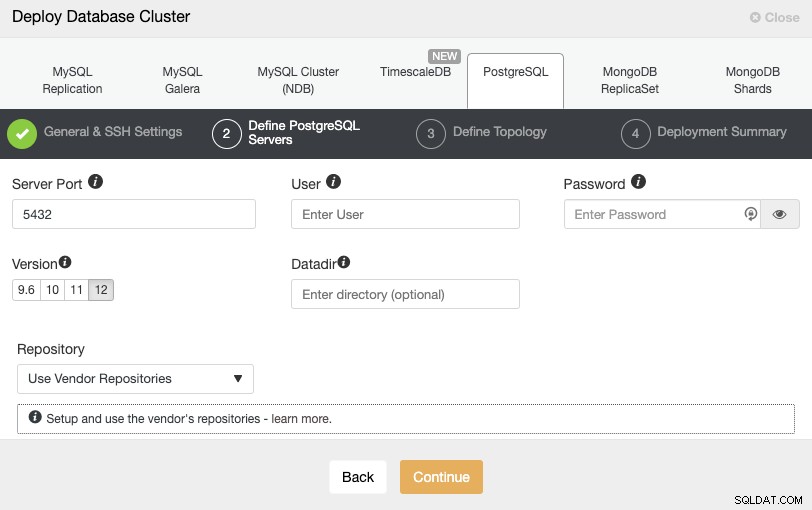
Después de configurar la información de acceso SSH, debe definir el usuario de la base de datos, versión y datadir (opcional). También puede especificar qué repositorio usar. En el siguiente paso, debe agregar sus servidores al clúster que va a crear.
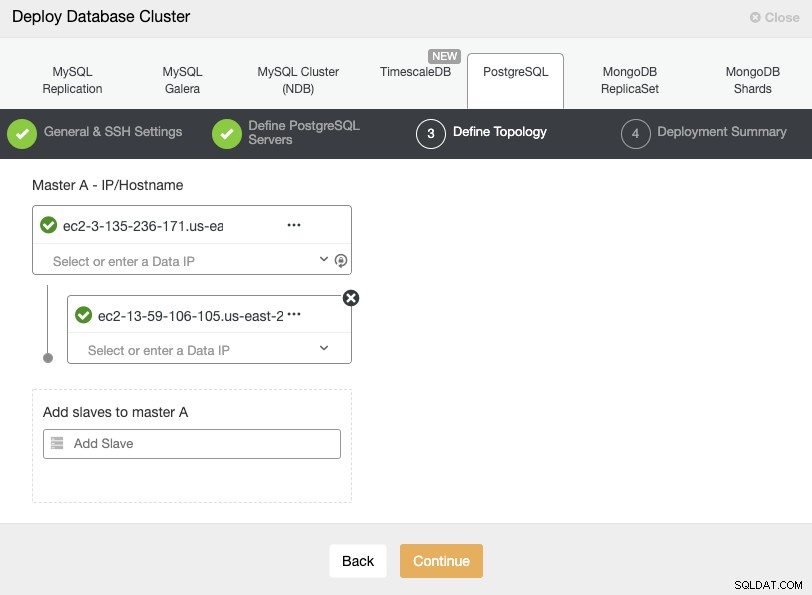
Al agregar sus servidores, puede ingresar la IP o el nombre de host. En este paso, también podría agregar el nodo ubicado en el proveedor de la nube secundario, ya que ClusterControl no tiene ninguna limitación sobre la red que se utilizará, pero para que quede más claro, lo agregaremos en la siguiente sección. El único requisito aquí es tener acceso SSH al nodo.
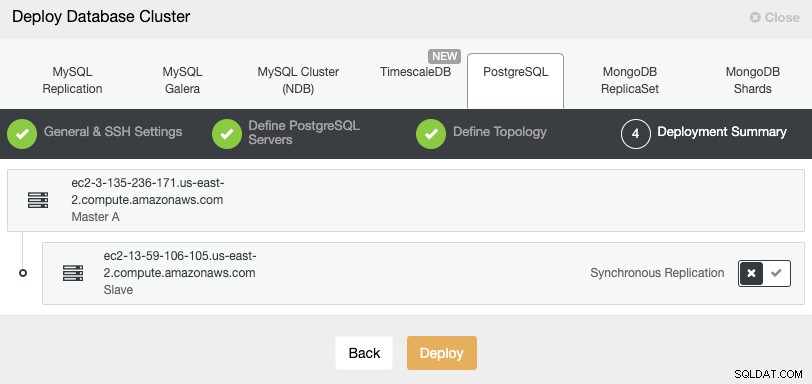
En el último paso, puede elegir si su replicación será Síncrona o Asíncrono.
En caso de que esté agregando su nodo remoto aquí, es importante usar la replicación asíncrona, de lo contrario, su clúster podría verse afectado por la latencia o problemas de red.
Puede monitorear el estado de creación en el monitor de actividad de ClusterControl.
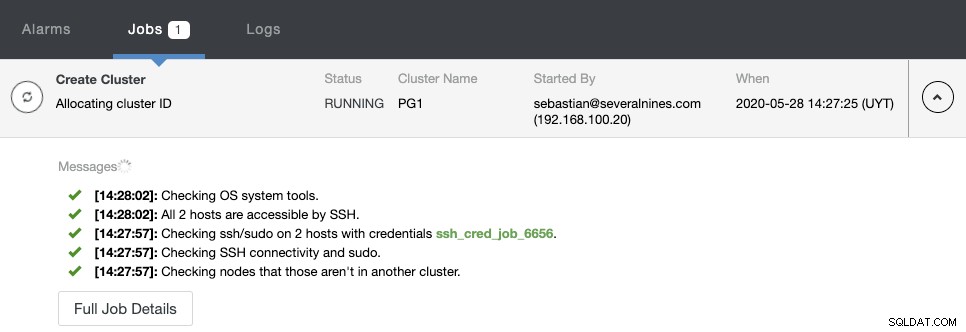
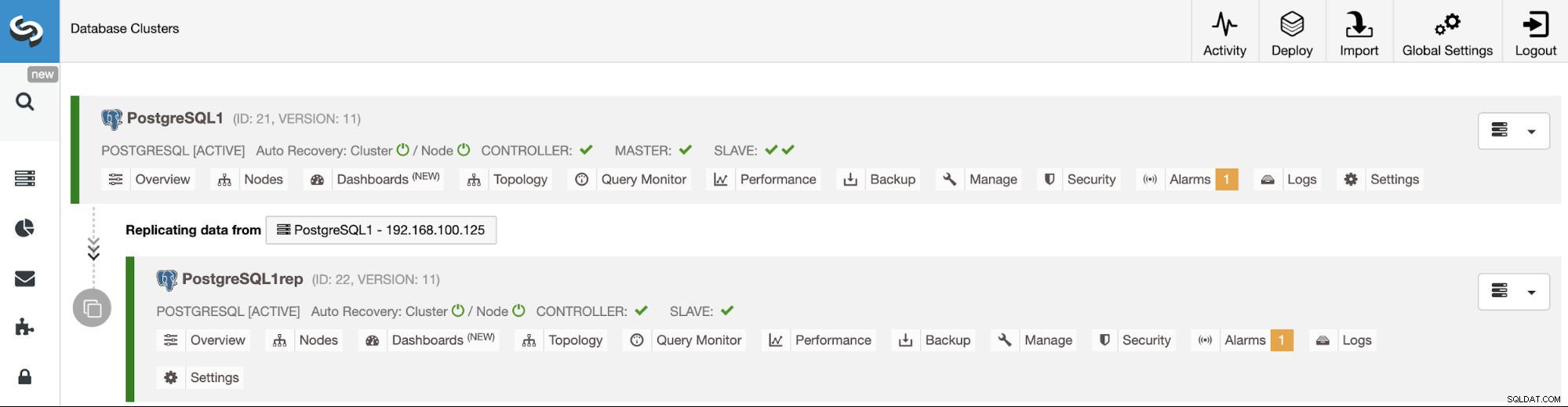
Una vez finalizada la tarea, puede ver su nuevo clúster de PostgreSQL en la pantalla principal de ClusterControl.

Agregar un nodo esclavo remoto en la nube
Una vez que haya creado su clúster, puede realizar varias tareas en él, como implementar/importar un balanceador de carga o un nodo esclavo de replicación.
Vaya a las acciones del clúster y seleccione "Agregar esclavo de replicación":
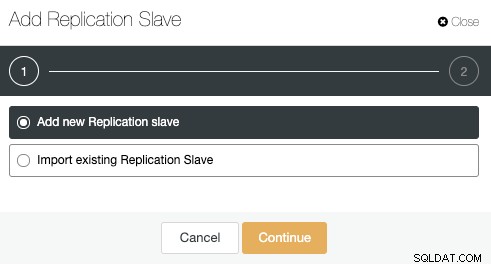
Utilicemos la opción "Agregar nuevo esclavo de replicación" ya que suponemos que el nodo remoto es una instalación nueva, si no, puede usar la opción "Importar esclavo de replicación existente" en su lugar.
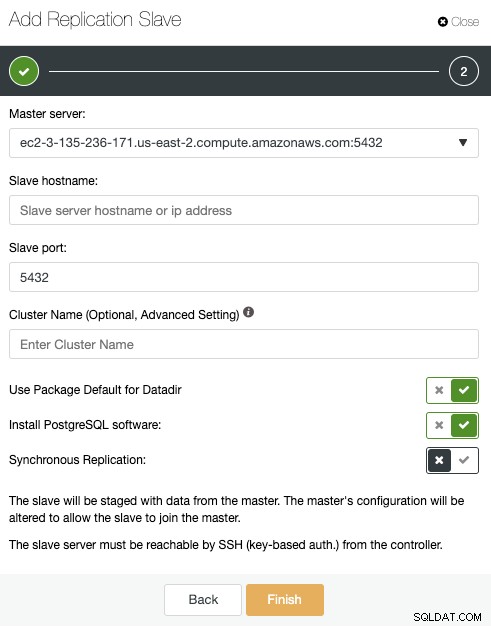
Aquí, solo necesita elegir su servidor Master, ingrese la dirección IP para su nuevo servidor esclavo y el puerto de la base de datos. Luego, puede elegir si desea que ClusterControl instale el software y si el esclavo de replicación debe ser síncrono o asíncrono. Nuevamente, si está agregando un nodo en un centro de datos diferente, debe usar la replicación asincrónica para evitar problemas relacionados con el rendimiento de la red.
De esta manera, puede agregar tantas réplicas como desee y distribuir el tráfico de lectura entre ellas mediante un balanceador de carga, que también puede implementar con ClusterControl.
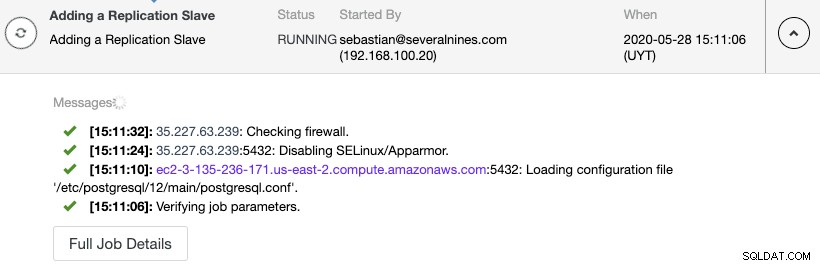
Puede monitorear la creación del esclavo de replicación en el monitor de actividad de ClusterControl.
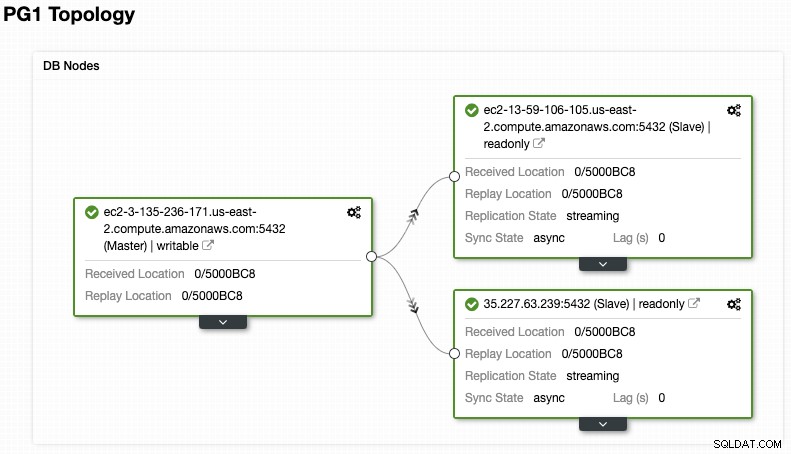
Y verifique su topología final en la sección Vista de topología.
Replicación de clúster a clúster en la nube
En lugar de usar la opción "Agregar esclavo de replicación" para tener un entorno de múltiples nubes, puede usar la función de replicación de clúster a clúster de ClusterControl para agregar un clúster remoto. Por el momento, esta característica tiene una limitación para PostgreSQL que le permite tener solo un nodo remoto, por lo que es bastante similar a la forma anterior, pero estamos trabajando para eliminar esa limitación pronto en una versión futura.
Para crear un nuevo clúster esclavo, vaya a ClusterControl -> Seleccionar clúster -> Acciones del clúster -> Crear clúster esclavo.
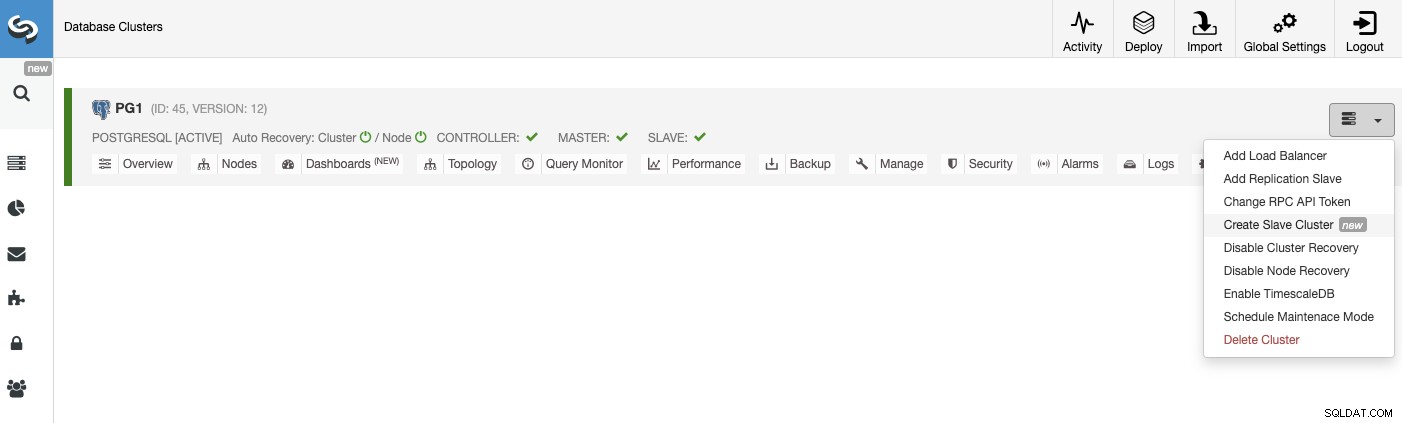
El clúster esclavo se creará mediante la transmisión de datos del clúster maestro actual.
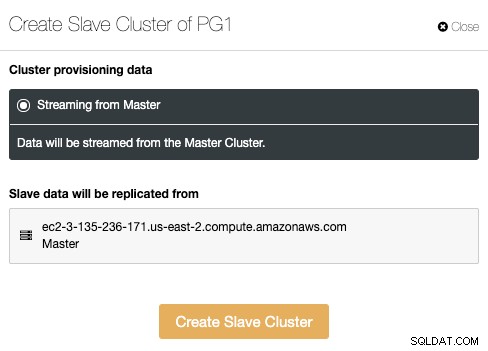
En esta sección, debe elegir el nodo maestro del clúster actual de que se replicarán los datos.
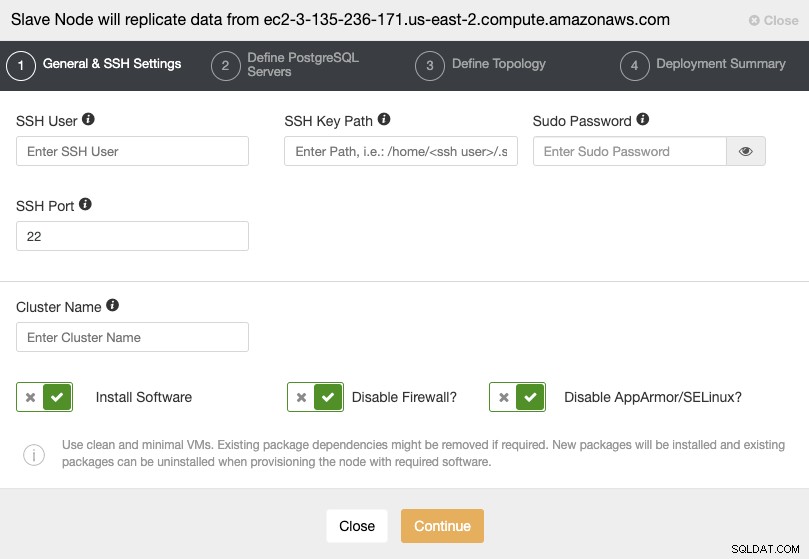
Cuando vaya al siguiente paso, debe especificar Usuario, Clave o Contraseña y puerto para conectarte por SSH a tus servidores. También necesita un nombre para su Slave Cluster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
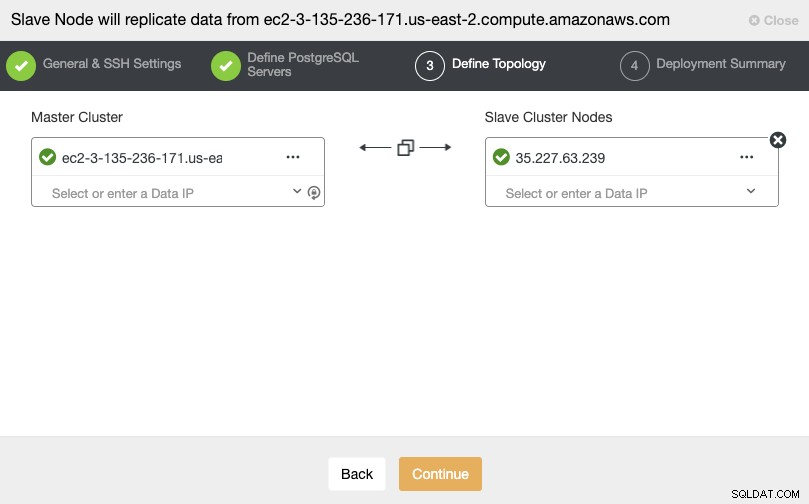
Después de configurar la información de acceso SSH, debe definir la versión de la base de datos, datadir, puerto y credenciales de administrador. Como usará la replicación de transmisión, asegúrese de usar la misma versión de la base de datos y las mismas credenciales que se usan en el clúster principal. También puede especificar qué repositorio usar.
En este paso, debe agregar el servidor para el nuevo clúster esclavo . Para esta tarea, puede ingresar tanto la dirección IP como el nombre de host del nodo de la base de datos.
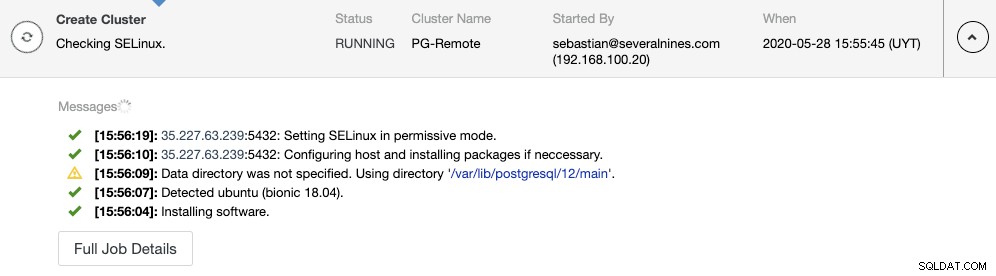
Puede monitorear la creación del clúster esclavo en el monitor de actividad de ClusterControl. Una vez finalizada la tarea, puede ver el clúster en la pantalla principal de ClusterControl.
Conclusión
Estas características de ClusterControl le permitirán configurar rápidamente la replicación entre diferentes proveedores de la nube para una base de datos PostgreSQL (y diferentes tecnologías) y administrar la configuración de una manera fácil y amigable. Acerca de la comunicación entre los proveedores de la nube, por razones de seguridad, debe restringir el tráfico solo de fuentes conocidas, es decir, solo del proveedor de la nube 1 al proveedor de la nube 2 y viceversa.