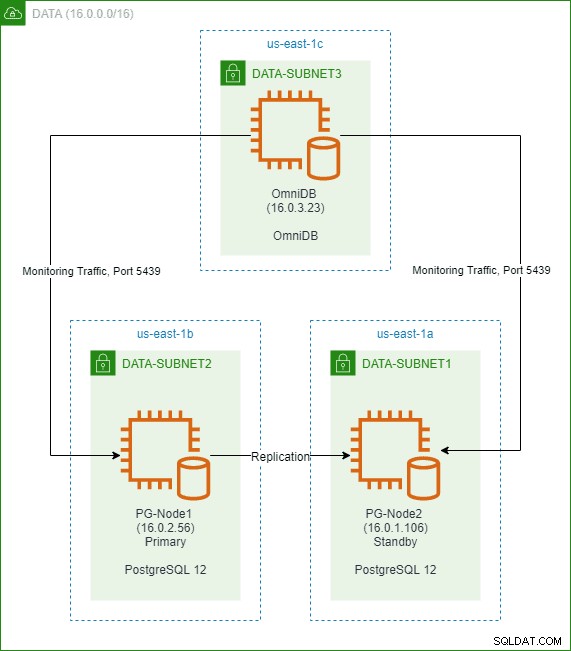
En un artículo anterior de esta serie, creamos un clúster PostgreSQL 12 de dos nodos en la nube de AWS. También instalamos y configuramos 2ndQuadrant OmniDB en un tercer nodo. La siguiente imagen muestra la arquitectura:
Podríamos conectarnos tanto al nodo principal como al nodo de reserva desde la interfaz de usuario basada en web de OmniDB. Luego restauramos una base de datos de muestra llamada "dvdrental" en el nodo principal que comenzó a replicarse en el modo de espera.
En esta parte de la serie, aprenderemos cómo crear y usar un panel de monitoreo en OmniDB. Los DBA y los equipos de operaciones a menudo prefieren herramientas gráficas en lugar de consultas complejas para inspeccionar visualmente el estado de la base de datos. OmniDB viene con una serie de widgets importantes que se pueden usar fácilmente en un panel de monitoreo. Como veremos más adelante, también permite a los usuarios escribir sus propios widgets de monitoreo.
Creación de un panel de control de rendimiento
Comencemos con el panel de control predeterminado que viene con OmniDB.
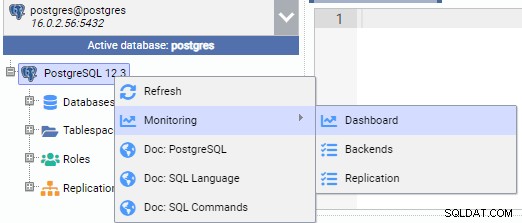
En la imagen a continuación, estamos conectados al nodo principal (PG-Node1). Hacemos clic con el botón derecho en el nombre de la instancia y luego, en el menú emergente, seleccionamos "Monitor" y luego seleccionamos "Panel".
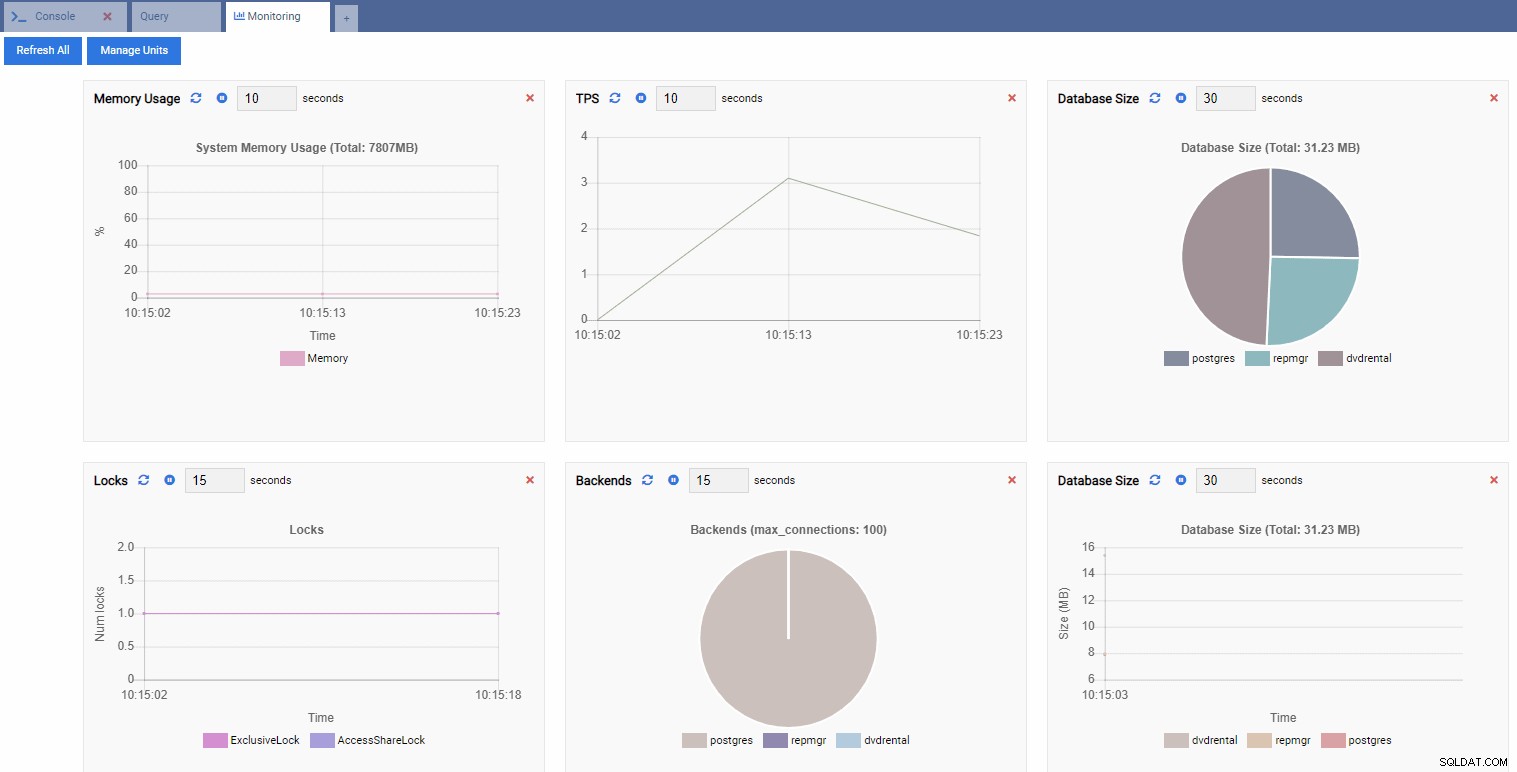
Esto abre un tablero con algunos widgets.
En términos de OmniDB, los widgets rectangulares en el tablero se denominan Unidades de monitoreo . Cada una de estas unidades muestra una métrica específica de la instancia de PostgreSQL a la que está conectada y actualiza dinámicamente sus datos.
Comprensión de las unidades de seguimiento
OmniDB viene con cuatro tipos de unidades de monitoreo:
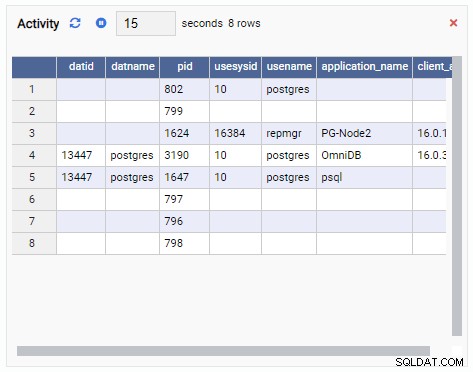
- Una Cuadrícula es una estructura tabular que muestra el resultado de una consulta. Por ejemplo, esta puede ser la salida de SELECT * FROM pg_stat_replication. Una cuadrícula se ve así:
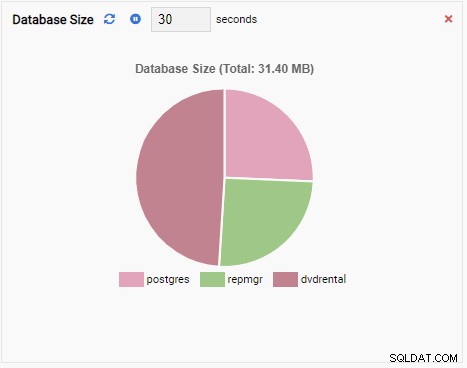
- Un gráfico muestra los datos en formato gráfico, como líneas o gráficos circulares. Cuando se actualiza, todo el gráfico se vuelve a dibujar en la pantalla con un valor nuevo y el valor anterior desaparece. Con estas Unidades de Monitoreo, solo podemos ver el valor actual de la métrica. Este es un ejemplo de un gráfico:
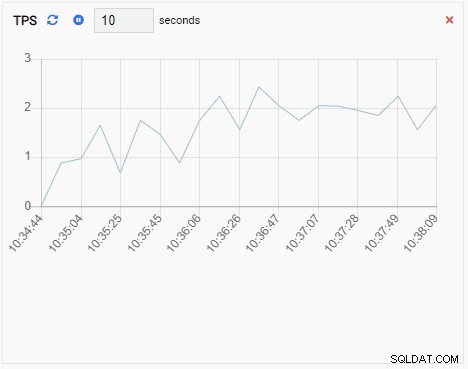
- Un gráfico adjunto también es una Unidad de Monitoreo de tipo Gráfico, excepto que cuando se actualiza, agrega el nuevo valor a la serie existente. Con Chart-Append, podemos ver fácilmente las tendencias a lo largo del tiempo. Aquí hay un ejemplo:
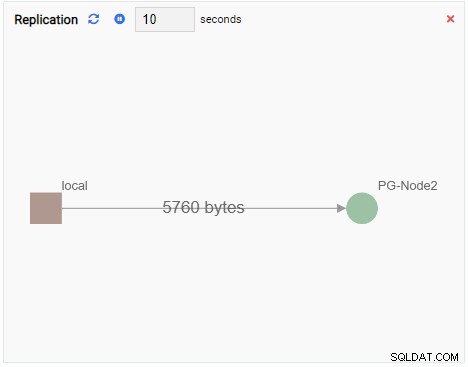
- Un Gráfico muestra las relaciones entre las instancias de clúster de PostgreSQL y una métrica asociada. Al igual que la Unidad de seguimiento de gráficos, una Unidad de seguimiento de gráficos también actualiza su valor anterior con uno nuevo. La siguiente imagen muestra que el nodo actual (PG-Node1) se está replicando en el PG-Node2:
Cada Unidad de Monitoreo tiene una serie de elementos comunes:
- El nombre de la Unidad de Monitoreo
- Un botón "actualizar" para actualizar manualmente la unidad
- Un botón de "pausa" para detener temporalmente la actualización de la unidad de monitoreo
- Un cuadro de texto que muestra el intervalo de actualización actual. Esto se puede cambiar
- Un botón de "cerrar" (marca de cruz roja) para retirar la Unidad de Monitoreo del tablero
- El área de dibujo real del Monitoreo
Unidades de monitoreo preconstruidas
OmniDB viene con una serie de unidades de monitoreo para PostgreSQL que podemos agregar a nuestro tablero. Para acceder a estas unidades, hacemos clic en el botón "Administrar unidades" en la parte superior del tablero:
Esto abre la lista "Administrar unidades":
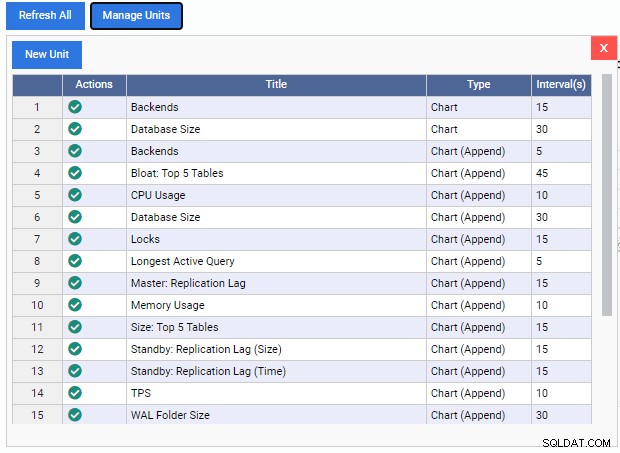
Como podemos ver, aquí hay pocas unidades de monitoreo preconstruidas. Los códigos para estas unidades de monitoreo se pueden descargar gratuitamente desde el repositorio de GitHub de 2ndQuadrant. Cada unidad enumerada aquí muestra su nombre, tipo (gráfico, anexo de gráfico, gráfico o cuadrícula) y la frecuencia de actualización predeterminada.
Para agregar una Unidad de Monitoreo al tablero, solo tenemos que hacer clic en la marca de verificación verde debajo de la columna "Acciones" para esa unidad. Podemos mezclar y combinar diferentes Unidades de Monitoreo para construir el tablero que queremos.
En la imagen a continuación, agregamos las siguientes unidades para nuestro panel de control de rendimiento y eliminamos todo lo demás:
TPS (transacción por segundo):
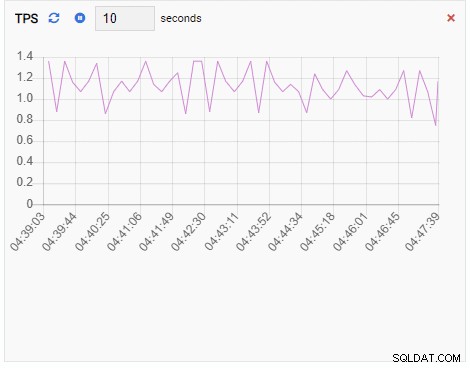
Número de candados:
Número de servidores:
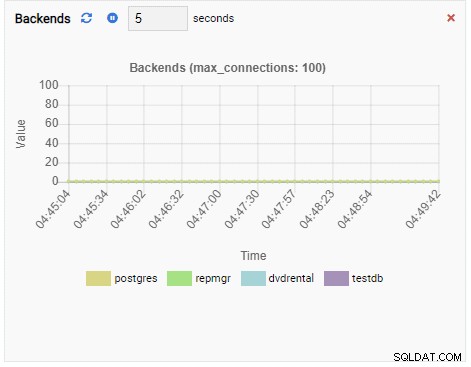
Dado que nuestra instancia está inactiva, podemos ver que los valores de TPS, bloqueos y backends son mínimos.
Prueba del panel de control
Ahora ejecutaremos pgbench en nuestro nodo principal (PG-Node1). pgbench es una herramienta de evaluación comparativa simple que se envía con PostgreSQL. Como la mayoría de las otras herramientas de este tipo, pgbench crea un esquema y tablas de sistemas OLTP de muestra en una base de datos cuando se inicializa. Después de eso, puede emular varias conexiones de clientes, cada una de las cuales ejecuta una serie de transacciones en la base de datos. En este caso, no evaluaremos el nodo principal de PostgreSQL; solo crearemos la base de datos para pgbench y veremos si nuestras Unidades de Monitoreo del tablero detectan el cambio en la salud del sistema.
Primero, estamos creando una base de datos para pgbench en el nodo principal:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb"; CREATE DATABASE
A continuación, estamos inicializando la base de datos "testdb" para pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdb dropping old tables... creating tables... generating data... 100000 of 2000000 tuples (5%) done (elapsed 0.02 s, remaining 0.43 s) 200000 of 2000000 tuples (10%) done (elapsed 0.05 s, remaining 0.41 s) … … 2000000 of 2000000 tuples (100%) done (elapsed 1.84 s, remaining 0.00 s) vacuuming... creating primary keys... done.
Con la base de datos inicializada, ahora comenzamos el proceso de carga real. En el fragmento de código a continuación, le pedimos a pgbench que comience con 50 conexiones de clientes simultáneas en la base de datos testdb, cada conexión ejecuta 100000 transacciones en sus tablas. La prueba de carga se ejecutará en dos subprocesos.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdb starting vacuum...end. … …
Si ahora volvemos a nuestro panel OmniDB, vemos que las unidades de monitoreo muestran resultados muy diferentes.
La métrica TPS muestra un valor bastante alto. Hay un salto repentino de menos de 2 a más de 2000:
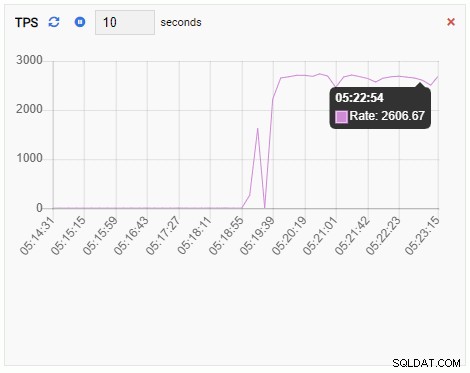
El número de backends ha aumentado. Como era de esperar, testdb tiene 50 conexiones mientras otras bases de datos están inactivas:
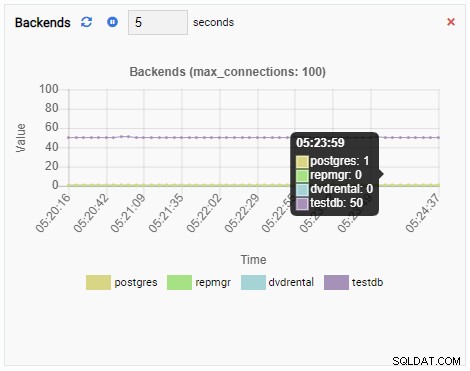
Y finalmente, la cantidad de bloqueos exclusivos de filas en la base de datos testdb también es alta:
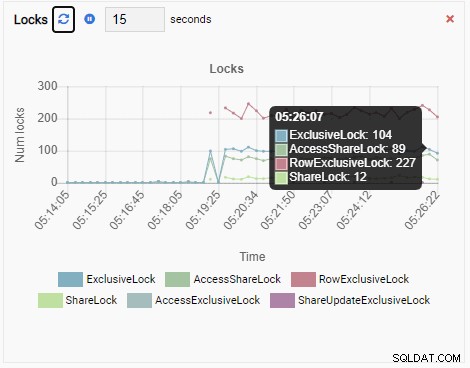
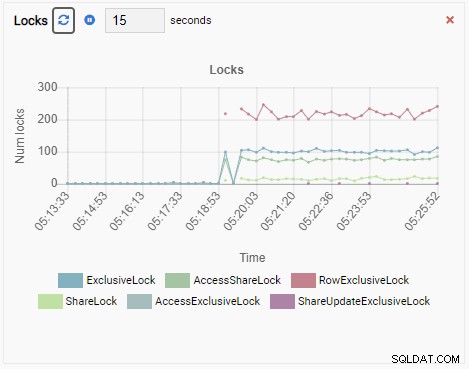
Ahora imagina esto. Es un DBA y usa OmniDB para administrar una flota de instancias de PostgreSQL. Recibe una llamada para investigar el rendimiento lento en una de las instancias.
Usando un tablero como el que acabamos de ver (aunque es muy simple), puede encontrar fácilmente la causa raíz. Puede verificar la cantidad de backends, bloqueos, memoria disponible, etc. para ver qué está causando el problema.
Y ahí es donde OmniDB puede ser una herramienta realmente útil.
Creación de unidades de seguimiento personalizadas
En ocasiones necesitaremos crear nuestras propias Unidades de Monitoreo. Para escribir una nueva Unidad de Monitoreo, hacemos clic en el botón "Nueva Unidad" en la lista "Gestionar Unidades". Esto abre una nueva pestaña con un lienzo vacío para escribir código:
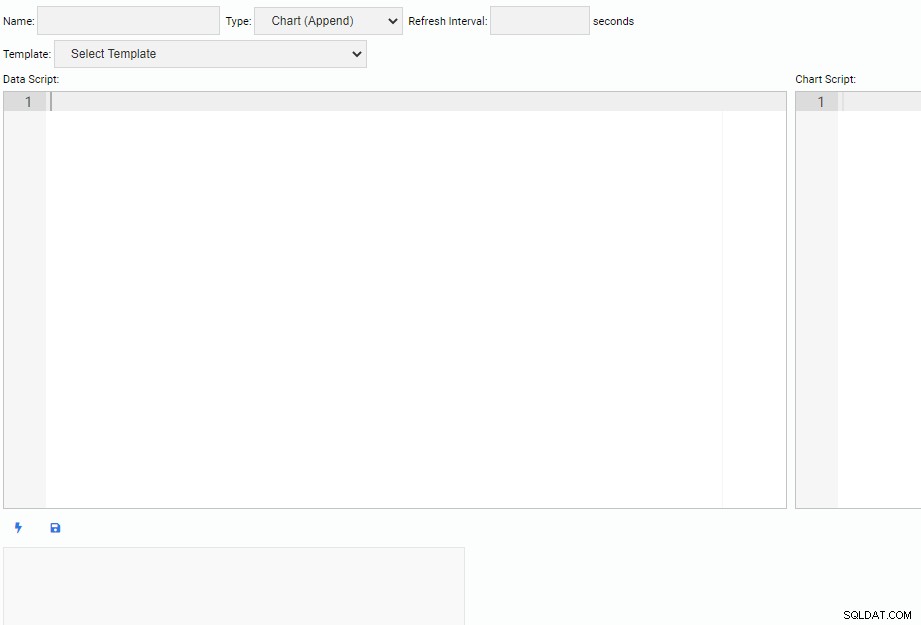
En la parte superior de la pantalla, tenemos que especificar un nombre para nuestra Unidad de Monitoreo, seleccionar su tipo y especificar su intervalo de actualización predeterminado. También podemos seleccionar una unidad existente como plantilla.
Debajo de la sección de encabezado, hay dos cuadros de texto. El editor “Data Script” es donde escribimos código para obtener datos para nuestra Unidad de Monitoreo. Cada vez que se actualiza una unidad, se ejecutará el código del script de datos. El editor "Chart Script" es donde escribimos el código para dibujar la unidad real. Esto se ejecuta cuando la unidad se extrae por primera vez.
Todo el código del script de datos está escrito en Python. Para la Unidad de Monitoreo de tipo Gráfico, OmniDB necesita que el script del gráfico esté escrito en Chart.js.
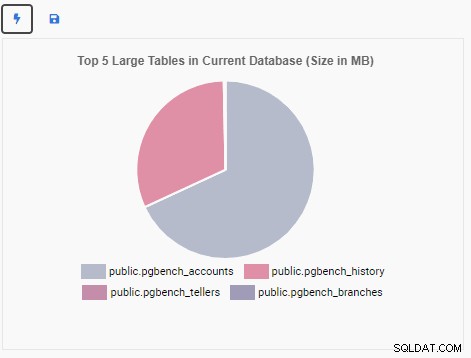
Ahora crearemos una Unidad de Monitoreo para mostrar las 5 tablas grandes principales en la base de datos actual. Según la base de datos seleccionada en OmniDB, la unidad de control cambiará su visualización para reflejar los nombres de las cinco tablas más grandes de esa base de datos.
Para escribir una nueva Unidad, es mejor comenzar con una plantilla existente y modificar su código. Esto ahorrará tiempo y esfuerzo. En la siguiente imagen, hemos denominado a nuestra Unidad de Monitoreo “Top 5 Large Tables”. Lo hemos elegido para que sea de tipo gráfico (sin anexar) y proporcionamos una frecuencia de actualización de 30 segundos. También hemos basado nuestra Unidad de Monitoreo en la plantilla de Tamaño de Base de Datos:
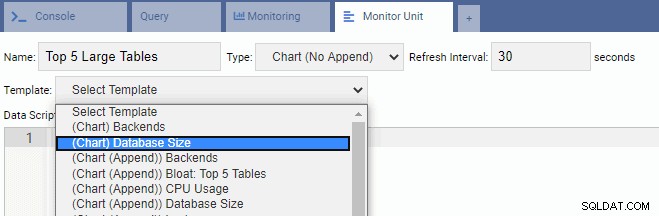
El cuadro de texto de la secuencia de comandos de datos se completa automáticamente con el código para la unidad de control del tamaño de la base de datos:
from datetime import datetime
from random import randint
databases = connection.Query('''
SELECT d.datname AS datname,
round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size
FROM pg_catalog.pg_database d
WHERE d.datname not in ('template0','template1')
''')
data = []
color = []
label = []
for db in databases.Rows:
data.append(db["size"])
color.append("rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")")
label.append(db["datname"])
total_size = connection.ExecuteScalar('''
SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)
FROM pg_catalog.pg_database
WHERE NOT datistemplate
''')
result = {
"labels": label,
"datasets": [
{
"data": data,
"backgroundColor": color,
"label": "Dataset 1"
}
],
"title": "Database Size (Total: " + str(total_size) + " MB)"
} Y el cuadro de texto Chart Script también se completa con el código:
total_size = connection.ExecuteScalar('''
SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)
FROM pg_catalog.pg_database
WHERE NOT datistemplate
''')
result = {
"type": "pie",
"data": None,
"options": {
"responsive": True,
"title":{
"display":True,
"text":"Database Size (Total: " + str(total_size) + " MB)"
}
}
} Podemos modificar el script de datos para obtener las 5 tablas más grandes de la base de datos. En el siguiente script, hemos conservado la mayor parte del código original, excepto la instrucción SQL:
from datetime import datetime
from random import randint
tables = connection.Query('''
SELECT nspname || '.' || relname AS "tablename",
round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS "table_size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY 2 DESC
LIMIT 5;
''')
data = []
color = []
label = []
for table in tables.Rows:
data.append(table["table_size"])
color.append("rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")")
label.append(table["tablename"])
result = {
"labels": label,
"datasets": [
{
"data": data,
"backgroundColor": color,
"label": "Top 5 Large Tables"
}
]
} Aquí obtenemos el tamaño combinado de cada tabla y sus índices en la base de datos actual. Estamos ordenando los resultados en orden descendente y seleccionando las cinco primeras filas.
A continuación, estamos completando tres matrices de Python iterando sobre el conjunto de resultados.
Finalmente, estamos creando una cadena JSON basada en los valores de las matrices.
En el cuadro de texto Chart Script, hemos modificado el código para eliminar el comando SQL original. Aquí, estamos especificando solo el aspecto cosmético del gráfico. Estamos definiendo el gráfico como tipo circular y dándole un título:
result = {
"type": "pie",
"data": None,
"options": {
"responsive": True,
"title":{
"display":True,
"text":"Top 5 Large Tables in Current Database (Size in MB)"
}
}
} Ahora podemos probar la unidad haciendo clic en el icono del rayo. Esto mostrará la nueva Unidad de Monitoreo en el área de dibujo de vista previa:
A continuación, guardamos la unidad haciendo clic en el icono del disco. Un cuadro de mensaje confirma que la unidad se ha guardado:

Ahora volvemos a nuestro panel de monitoreo y agregamos la nueva Unidad de Monitoreo:
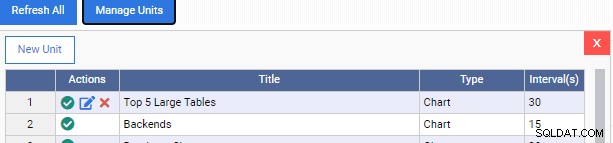
Observe cómo tenemos dos íconos más debajo de la columna "Acciones" para nuestra Unidad de Monitoreo personalizada. Uno es para editarlo, el otro es para eliminarlo de OmniDB.
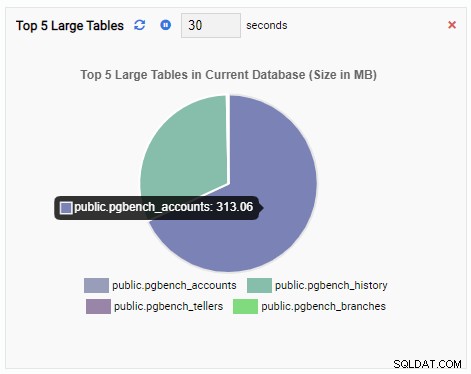
La Unidad de Monitoreo "Top 5 Large Tables" ahora muestra las cinco tablas más grandes en la base de datos actual:
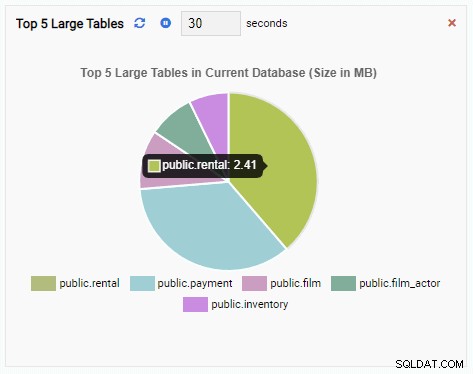
Si cerramos el tablero, cambiamos a otra base de datos desde el panel de navegación y abrimos el tablero nuevamente, veremos que la Unidad de monitoreo ha cambiado para reflejar las tablas de esa base de datos:
Palabras finales
Esto concluye nuestra serie de dos partes sobre OmniDB. Como vimos, OmniDB tiene algunas unidades de monitoreo ingeniosas que los DBA de PostgreSQL encontrarán útiles para el seguimiento del rendimiento. Vimos cómo podemos usar estas unidades para identificar posibles cuellos de botella en el servidor. También vimos cómo crear nuestras propias unidades personalizadas. Se anima a los lectores a crear y probar unidades de supervisión del rendimiento para sus cargas de trabajo específicas. 2ndQuadrant agradece cualquier contribución al repositorio de GitHub de la Unidad de Monitoreo de OmniDB.