El hecho de que la cadena afirme ser UTF-8 no significa que sea UTF-8. \xe9 es é en ISO-8859-1
(AKA Latin-1) pero no es válido en UTF-8; de manera similar, \xf1 es ñ en ISO-8859-1 pero no válido en UTF-8. Eso sugiere que la cadena en realidad está codificada en ISO-8859-1 en lugar de UTF-8. Puede solucionarlo con una combinación de force_encoding
para corregir la confusión de Ruby sobre la codificación actual y encode
para recodificarlo como UTF-8:
> "Tweets en Ingl\xE9s y en Espa\xF1ol".force_encoding('iso-8859-1').encode('utf-8')
=> "Tweets en Inglés y en Español"
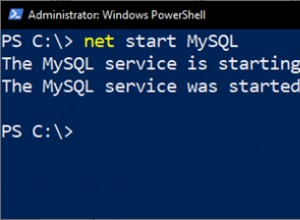
Entonces, antes de enviar esa cadena a la base de datos, desea:
name = name.force_encoding('iso-8859-1').encode('utf-8')
Desafortunadamente, no hay forma de detectar de manera confiable la codificación real de una cadena. Las diversas codificaciones se superponen y no hay forma de saber si è (\xe8 en ISO-8859-1) o č (\xe8 en ISO-8859-2) es el carácter correcto sin verificación de cordura manual.