Esta publicación de blog es una continuación de la parte 1 anterior, donde cubrimos los conceptos básicos de la integración de SNMP con ClusterControl.
En esta publicación de blog, nos centraremos en las trampas y alertas de SNMP. Las trampas de SNMP son los mensajes de alerta que se usan con más frecuencia y que se envían desde un dispositivo habilitado para SNMP remoto (un agente) a un recopilador central, el "administrador de SNMP". En el caso de ClusterControl, una trampa podría ser una alerta después de que la alarma crítica para un clúster no sea 0, lo que indica que algo malo está sucediendo.
Como se muestra en la publicación de blog anterior, para esta prueba de concepto, tenemos dos definiciones de notificaciones de trampas SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Las notificaciones (o trampas) son CriticalAlarmNotification y CriticalAlarmNotificationEnded. Ambos eventos de notificación se pueden usar para señalar nuestro servicio Nagios, ya sea que el clúster tenga alarmas críticas activas o no. En Nagios, el término para esto es verificación pasiva, mediante la cual Nagios no intenta determinar si el host/servicio está INACTIVO o INALCANCEABLE. También configuraremos las comprobaciones activas, donde la lógica de comprobación inicia las comprobaciones en el demonio de Nagios mediante el uso de la definición del servicio para monitorear también las alarmas críticas/de advertencia informadas por nuestro clúster.
Tenga en cuenta que esta publicación de blog requiere que el agente MIB y SNMP de Variousnines esté configurado correctamente, como se muestra en la primera parte de esta serie de blogs.
Instalación del núcleo de Nagios
Nagios Core es la versión gratuita de la suite de monitoreo de Nagios. En primer lugar, tenemos que instalarlo y todos los paquetes necesarios, seguido de los complementos de Nagios, snmptrapd y snmptt. Tenga en cuenta que las instrucciones en esta publicación de blog asumen que todos los nodos se ejecutan en CentOS 7.
Instalar los paquetes necesarios para ejecutar Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlCree un usuario nagios y un grupo nagcmd para permitir que los comandos externos se ejecuten a través de la interfaz web, agregue el usuario nagios y apache para que formen parte del grupo nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheDescargue la última versión de Nagios Core desde aquí, compílelo e instálelo:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstalar la configuración web de Nagios:
$ make install-webconfOpcionalmente, instale el tema de exfoliación de Nagios (o puede ceñirse al tema predeterminado):
$ make install-exfoliationCree una cuenta de usuario (nagiosadmin) para iniciar sesión en la interfaz web de Nagios. Recuerda la contraseña que le asignas a este usuario:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminReinicie el servidor web Apache para que la nueva configuración surta efecto:
$ systemctl restart httpd
$ systemctl enable httpdDescargue los complementos de Nagios desde aquí, compílelos e instálelos:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installVerifique los archivos de configuración predeterminados de Nagios:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosAbra el navegador y vaya a https://{IPaddress}/nagios y debería ver una autenticación básica HTTP donde debe especificar el nombre de usuario como nagiosadmin con la contraseña elegida creada anteriormente.
Añadiendo servidor ClusterControl a Nagios
Cree un archivo de definición de host de Nagios para ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgY agregue las siguientes líneas:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Algunas explicaciones:
-
En la primera sección, definimos nuestro host, con el nombre de host y la dirección del servidor ClusterControl.
-
Las secciones de servicio donde colocamos nuestras definiciones de servicio para que sean monitoreadas por Nagios. Los dos primeros básicamente le dicen al servicio que verifique la salida SNMP para un ID de objeto en particular. El primer servicio es sobre la alarma crítica, por lo tanto agregamos -c0 en el comando check_snmp para indicar que debe ser una alerta crítica en Nagios si el valor va más allá de 0. Mientras que para las alarmas de advertencia, lo indicaremos con una advertencia si el valor es 1 y superior.
-
La última definición de servicio se refiere a las trampas SNMP que esperaríamos que vinieran del servidor ClusterControl si la alarma crítica elevado es mayor que 0. Esta sección utilizará la definición snmp_trap_template, como se muestra en el siguiente paso.
Configure snmp_trap_template agregando las siguientes líneas en /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Incluya el archivo de configuración de ClusterControl en Nagios agregando la siguiente línea dentro
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgEjecute una verificación de configuración previa al vuelo:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgAsegúrese de obtener la siguiente línea al final de la salida:
"Things look okay - No serious problems were detected during the pre-flight check"Reinicie Nagios para cargar el cambio:
$ systemctl restart nagiosAhora, si observamos la página de Nagios en la sección Servicio (menú del lado izquierdo), veríamos algo como esto:
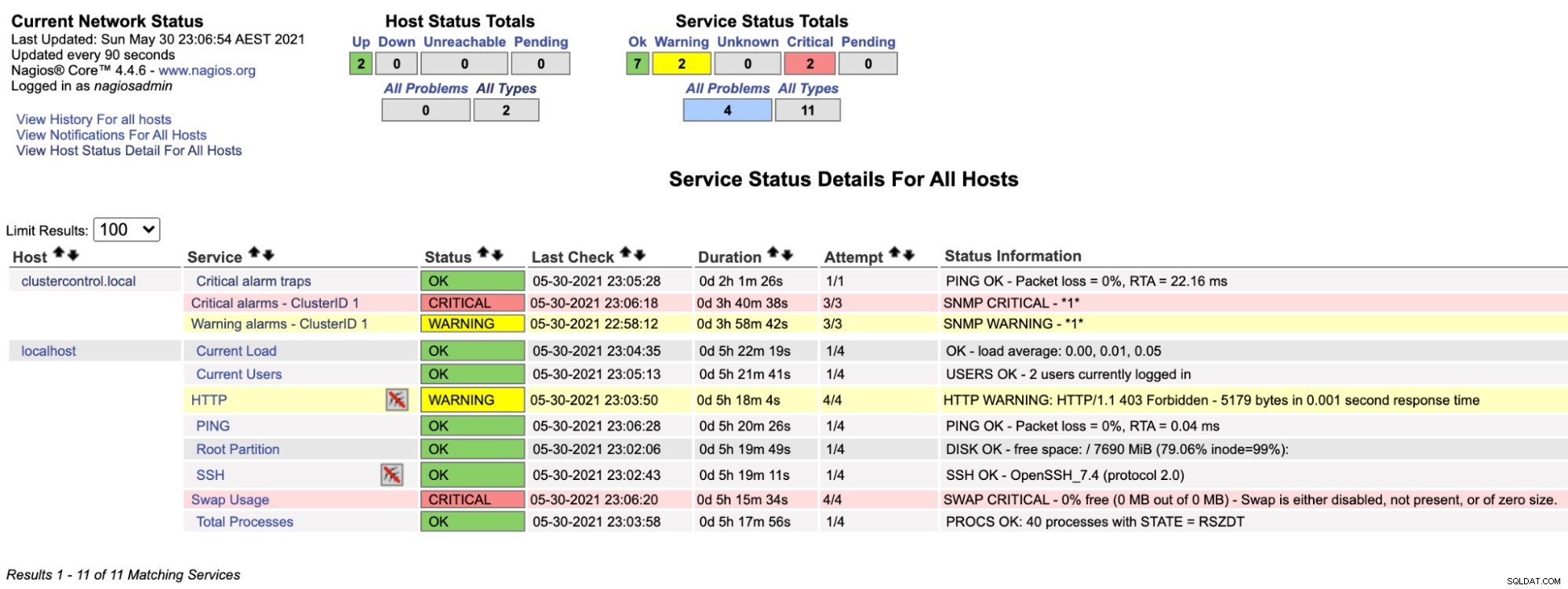
Observe que la fila "Alarmas críticas - ClusterID 1" se vuelve roja si el valor de alarma crítica informado por ClusterControl es mayor que 0, mientras que "Alarmas de advertencia - ClusterID 1" es amarilla, lo que indica que se ha activado una alarma de advertencia. En caso de que no suceda nada interesante, verá que todo está verde para clustercontrol.local.
Configurando Nagios para recibir una trampa
Las trampas se envían mediante dispositivos remotos al servidor de Nagios, esto se denomina control pasivo. Idealmente, no sabemos cuándo se enviará una trampa, ya que depende del dispositivo de envío que decida enviar una trampa. Por ejemplo, con un UPS (batería de respaldo), tan pronto como el dispositivo pierda energía, enviará una trampa para decir "oye, perdí energía". De esta forma se informa inmediatamente a Nagios.
Para recibir trampas SNMP, debemos configurar el servidor Nagios con lo siguiente:
-
snmptrapd (demonio receptor de trampas SNMP)
-
snmptt (Traductor de trampas SNMP, el demonio del manejo de trampas)
Después de que snmptrapd reciba una trampa, la pasará a snmptt donde lo configuraremos para actualizar el sistema Nagios y luego Nagios enviará la alerta de acuerdo con la configuración del grupo de contacto.
Instale el repositorio EPEL, seguido de los paquetes necesarios:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogConfigure el daemon trap SNMP en /etc/snmp/snmptrapd.conf y establezca las siguientes líneas:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerLo anterior simplemente significa que las trampas recibidas por el demonio snmptrapd se pasarán a /usr/sbin/snmptthandler.
Agregue SEVERALNINES-CLUSTERCONTROL-MIB.txt en /usr/share/snmp/mibs creando /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtCree /etc/snmp/snmp.conf (aviso sin la "d") y agregue nuestro MIB personalizado allí:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBIniciar el servicio snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdA continuación, debemos configurar las siguientes líneas de configuración dentro de /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDTenga en cuenta que habilitamos el módulo net_snmp_perl y agregamos otra ruta de configuración, /etc/snmp/snmptt-cc.conf dentro de snmptt.ini. Necesitamos definir los eventos snmptt de ClusterControl aquí para que puedan pasarse a Nagios. Cree un nuevo archivo en /etc/snmp/snmptt-cc.conf y agregue las siguientes líneas:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCAlgunas explicaciones:
-
Tenemos dos trampas definidas:CriticalAlarmNotification y CriticalAlarmNotificationEnded.
-
criticalAlarmNotification simplemente genera una alerta crítica y la pasa al servicio de "trampas de alarma crítica" definido en Nagios. El $aA significa devolver la dirección IP del agente trap. El valor 2 es el valor del resultado de la comprobación, que en este caso es crítico (0=OK, 1=ADVERTENCIA, 2=CRÍTICO, 3=DESCONOCIDO).
-
criticalAlarmNotificationEnded simplemente genera una alerta OK y la pasa al servicio "Critical alarm traps", para cancelar la trampa anterior después de que todo vuelva a la normalidad. El $aA significa devolver la dirección IP del agente trap. El valor 0 es el valor del resultado de la verificación, que en este caso es correcto. Para obtener más detalles sobre las sustituciones de cadenas reconocidas por snmptt, consulte este artículo en la sección "FORMATO".
-
Puede usar snmpttconvertmib para generar un archivo de controlador de eventos snmptt para una MIB en particular.
Tenga en cuenta que, de forma predeterminada, Nagios Core no proporciona la ruta de los controladores de eventos. Por lo tanto, tenemos que copiar ese directorio de manejadores de eventos de la fuente de Nagios en el directorio contrib, como se muestra a continuación:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersTambién necesitamos asignar el grupo snmptt como parte del grupo nagcmd, para que pueda ejecutar nagios.cmd dentro del script de submit_check_result:
$ usermod -a -G nagcmd snmpttInicie el servicio snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttEl administrador de SNMP (servidor Nagios) ahora está listo para aceptar y procesar nuestras trampas SNMP entrantes.
Enviando una trampa desde el servidor ClusterControl
Suponga que desea enviar una trampa SNMP al administrador SNMP, 192.168.10.11 (servidor Nagios) porque el número total de alarmas críticas ha llegado a 2 para el ID de clúster 1, se ejecutaría el siguiente comando en el servidor ClusterControl (lado del cliente), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1O, en formato OID (recomendado):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Donde, .1.3.6.1.4.1.57397.1.1.3.1 es igual al evento de captura CriticalAlarmNotification, y los OID subsiguientes son representaciones del número total de alarmas críticas actuales y el ID del clúster, respectivamente .
En el servidor de Nagios, debería notar que el servicio de captura se ha vuelto rojo:
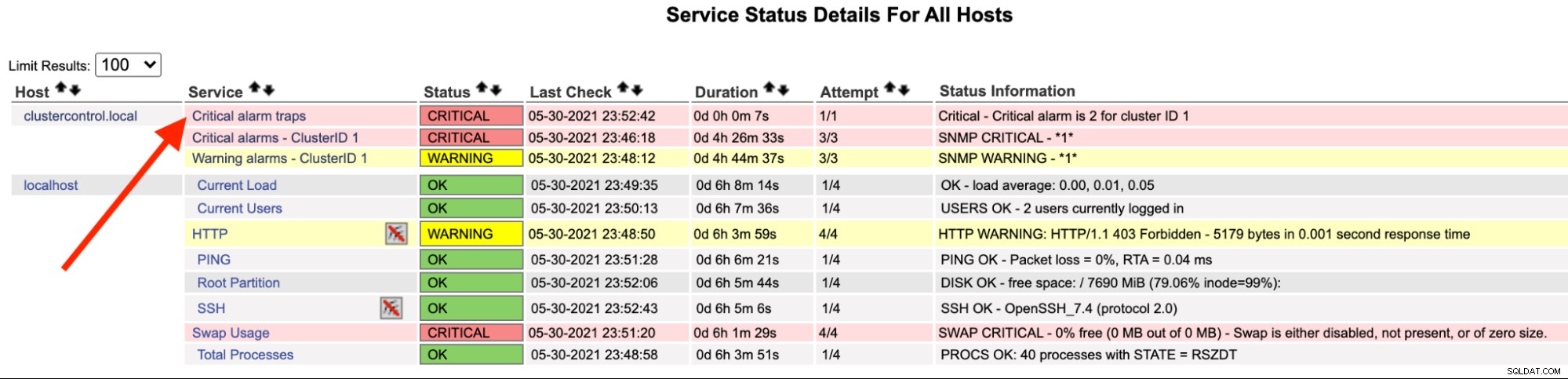
También puedes verlo en el /var/log/messages de la siguiente línea:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Una vez resuelta la alarma, para enviar una trampa normal, podemos ejecutar el siguiente comando:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Donde, .1.3.6.1.4.1.57397.1.1.3.2 es igual al evento CriticalAlarmNotificationEnded, y los OID subsiguientes son representaciones del número total de alarmas críticas actuales (debe ser 0 para este caso ) y el ID del clúster, respectivamente.
En el servidor de Nagios, debería notar que el servicio de trampas vuelve a estar en verde:
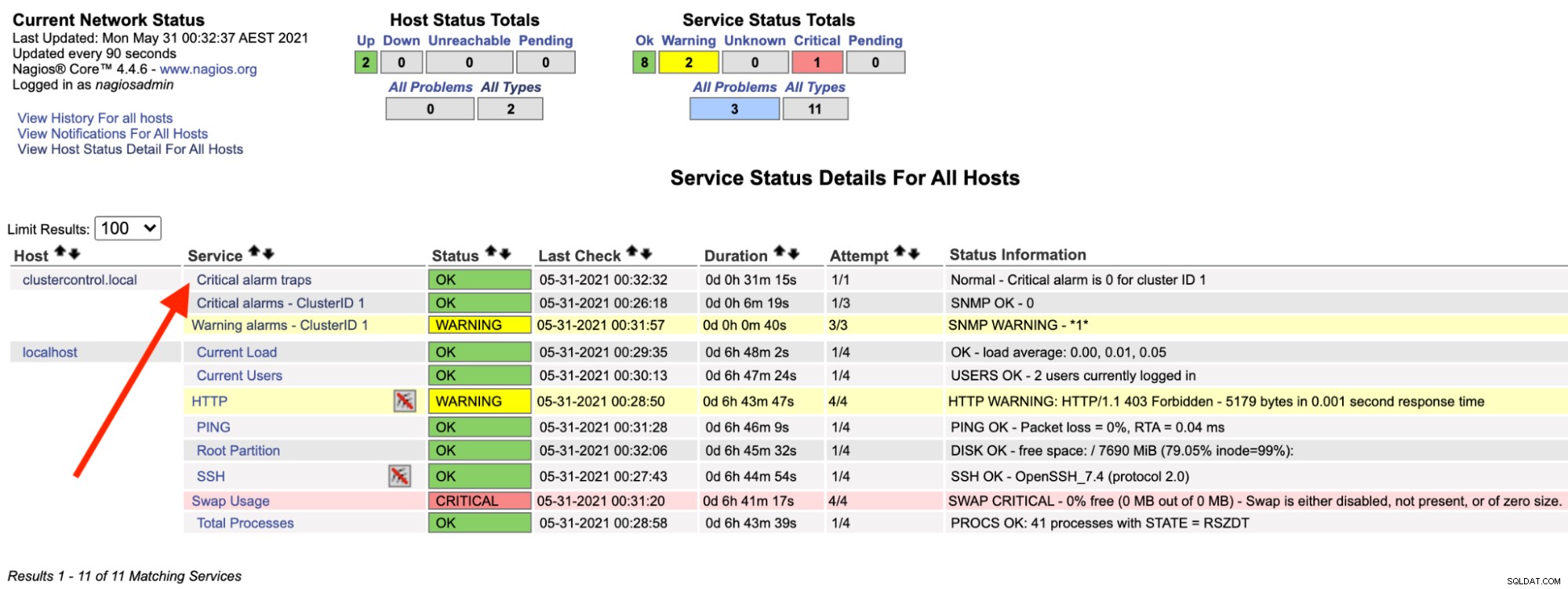
Lo anterior se puede automatizar con un simple script bash:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
donePara ejecutar el script en segundo plano, simplemente haga lo siguiente:
$ bash alarmtrapper.bash &En este punto, deberíamos poder ver el servicio de "Trampas de alarma crítica" de Nagios en acción si hay una falla en nuestro clúster automáticamente.
Reflexiones finales
En esta serie de blogs, mostramos una prueba de concepto sobre cómo se puede configurar ClusterControl para monitorear, generar/procesar trampas y alertar mediante el protocolo SNMP. Esto también marca el comienzo de nuestro viaje para incorporar SNMP en nuestros futuros lanzamientos. Estén atentos, ya que traeremos más actualizaciones sobre esta interesante función.



