Las organizaciones utilizan la infraestructura en la nube porque ofrece velocidad, flexibilidad y escalabilidad. Puede imaginar si podemos activar una nueva instancia de base de datos con solo un clic, y toma un par de minutos hasta que esté lista, también podemos implementar la aplicación más rápido que en comparación con el entorno local.
A menos que esté utilizando el propio servicio en la nube de MongoDB, los principales proveedores de la nube no ofrecen un servicio administrado de MongoDB, por lo que no es realmente una operación de un solo clic para implementar una sola instancia o clúster. La forma común es hacer girar las máquinas virtuales y luego implementarlas en ellas. La implementación debe realizarse de la A a la Z:debemos preparar la instancia, instalar el software de la base de datos, ajustar algunas configuraciones y asegurar la instancia. Estas tareas son esenciales, aunque no siempre se cumplen correctamente, con consecuencias potencialmente desastrosas.
La automatización juega un papel importante para garantizar que todas las tareas comiencen desde la instalación, la configuración, el fortalecimiento y hasta que el servicio de la base de datos esté listo. En este blog, hablaremos sobre la automatización de la implementación para MongoDB.
Orquestador de software
Hay muchas herramientas de software nuevas para ayudar a los ingenieros a implementar y administrar su infraestructura. La gestión de la configuración ayuda a los ingenieros a realizar una implementación más rápida y eficaz, lo que reduce el tiempo de implementación de nuevos servicios. Las opciones populares incluyen Ansible, Saltstack, Chef y Puppet. Cada producto tiene ventajas y desventajas, pero todos funcionan muy bien y son muy populares. La implementación de un servicio con estado como MongoDB ReplicaSet o Sharded Cluster puede ser un poco más desafiante, ya que se trata de configuraciones de varios servidores y las herramientas no admiten la coordinación incremental y entre nodos. Los procedimientos de implementación generalmente requieren orquestación entre nodos, con tareas realizadas en un orden específico.
Tareas de implementación de MongoDB para automatizar
La implementación de un servidor MongoDB implica varias cosas; agregue el repositorio MongoDB en local, instale el paquete MongoDB, configure el puerto, el nombre de usuario e inicie el servicio.
Tarea:instalar MongoDB
- name: install mongoDB
apt:
name: mongodb
state: present
update_cache: yes
Tarea:copiar mongod.conf del archivo de configuración.
- name: copy config file
copy:
src: mongodb.conf
dest: /etc/mongodb.conf
owner: root
group: root
mode: 0644
notify:
- restart mongodbTarea:crear configuración de límite de MongoDB:
- name: create /etc/security/limits.d/mongodb.conf
copy:
src: security-mongodb.conf
dest: /etc/security/limits.d/mongodb.conf
owner: root
group: root
mode: 0644
notify:
- restart mongodbTarea:configurar el intercambio
- name: config vm.swappiness
sysctl:
name: vm.swappiness
value: '10'
state: presentTarea:configurar tiempo TCP Keepalive
- name: config net.ipv4.tcp_keepalive_time
sysctl:
name: net.ipv4.tcp_keepalive_time
value: '120'
state: presentTarea:asegurarse de que MongoDB se inicie automáticamente
- name: Ensure mongodb is running and and start automatically on reboots
systemd:
name: mongodb
enabled: yes
state: startedPodemos combinar todas estas tareas en un solo libro de jugadas y ejecutar el libro de jugadas para automatizar la implementación. Si ejecutamos un playbook de Ansible desde la consola:
$ ansible-playbook -b mongoInstall.ymlVeremos el progreso de la implementación desde nuestro script de Ansible, el resultado debería ser similar al siguiente:
PLAY [ansible-mongo] **********************************************************
GATHERING FACTS ***************************************************************
ok: [10.10.10.11]
TASK: [install mongoDB] *******************************************************
ok: [10.10.10.11]
TASK: [copy config file] ******************************************************
ok: [10.10.10.11]
TASK: [create /etc/security/limits.d/mongodb.conf]*****************************
ok: [10.10.10.11]
TASK: [config vm.swappiness] **************************************************
ok: [10.10.10.11]
TASK: [config net.ipv4.tcp_keepalive_time]*************************************
ok: [10.10.10.11]
TASK: [config vm.swappiness] **********************************************
ok: [10.10.10.11]
PLAY RECAP ********************************************************************
[10.10.10.11] : ok=6 changed=1 unreachable=0 failed=0Después de la implementación, podemos verificar el servicio MongoDB en el servidor de destino.
Automatización de la implementación de MongoDB utilizando la GUI de ClusterControl
Hay dos formas de implementar MongoDB usando ClusterControl. Podemos usarlo desde el panel de control de ClusterControl, está basado en GUI y solo necesita 2 diálogos hasta que active un nuevo trabajo para una nueva implementación de MongoDB.
Primero necesitamos completar el usuario SSH y la contraseña, complete el nombre del clúster como se muestra a continuación:
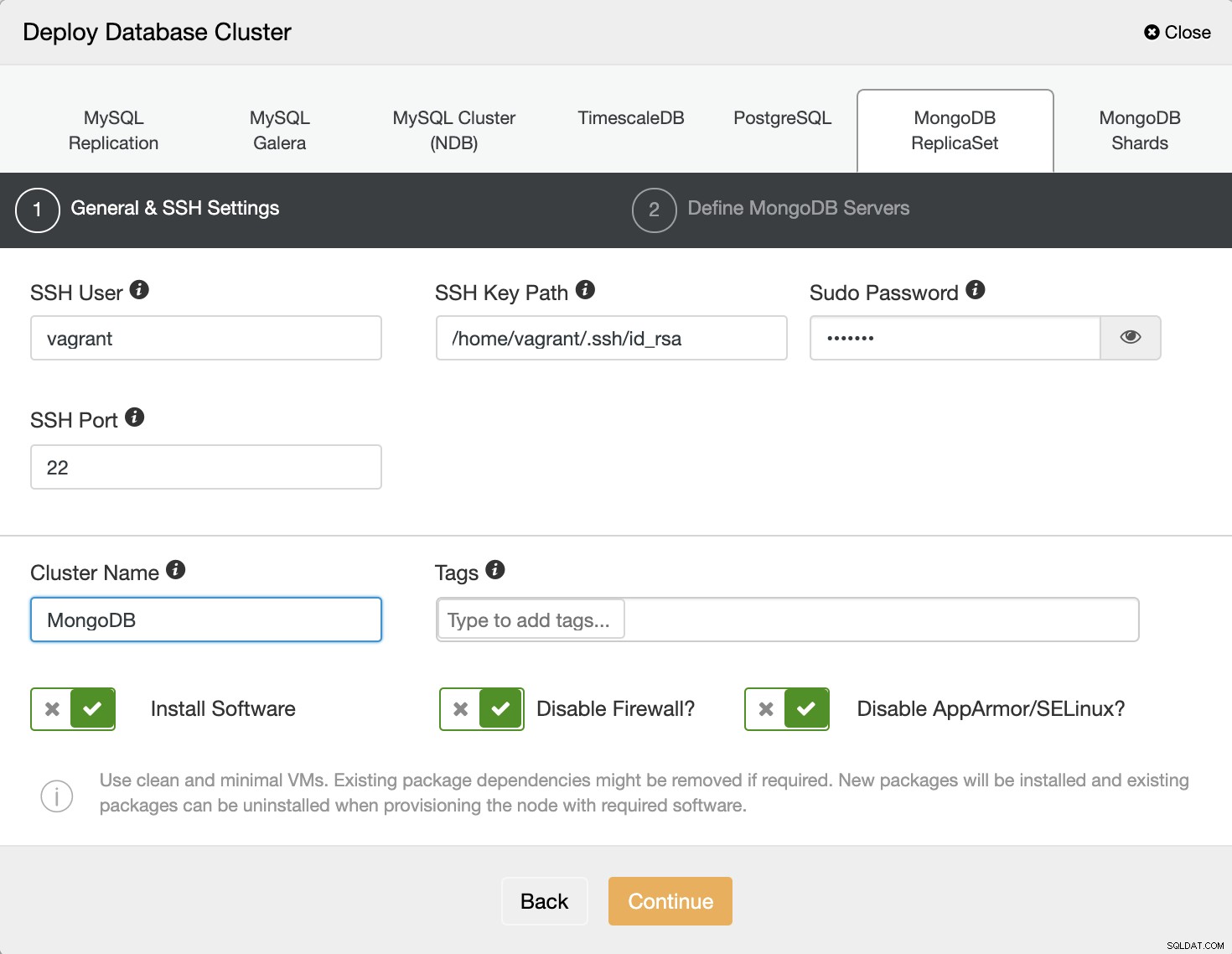
Y luego, elija el proveedor y la versión de MongoDB, defina el usuario y contraseña, y el último es completar la dirección IP de destino
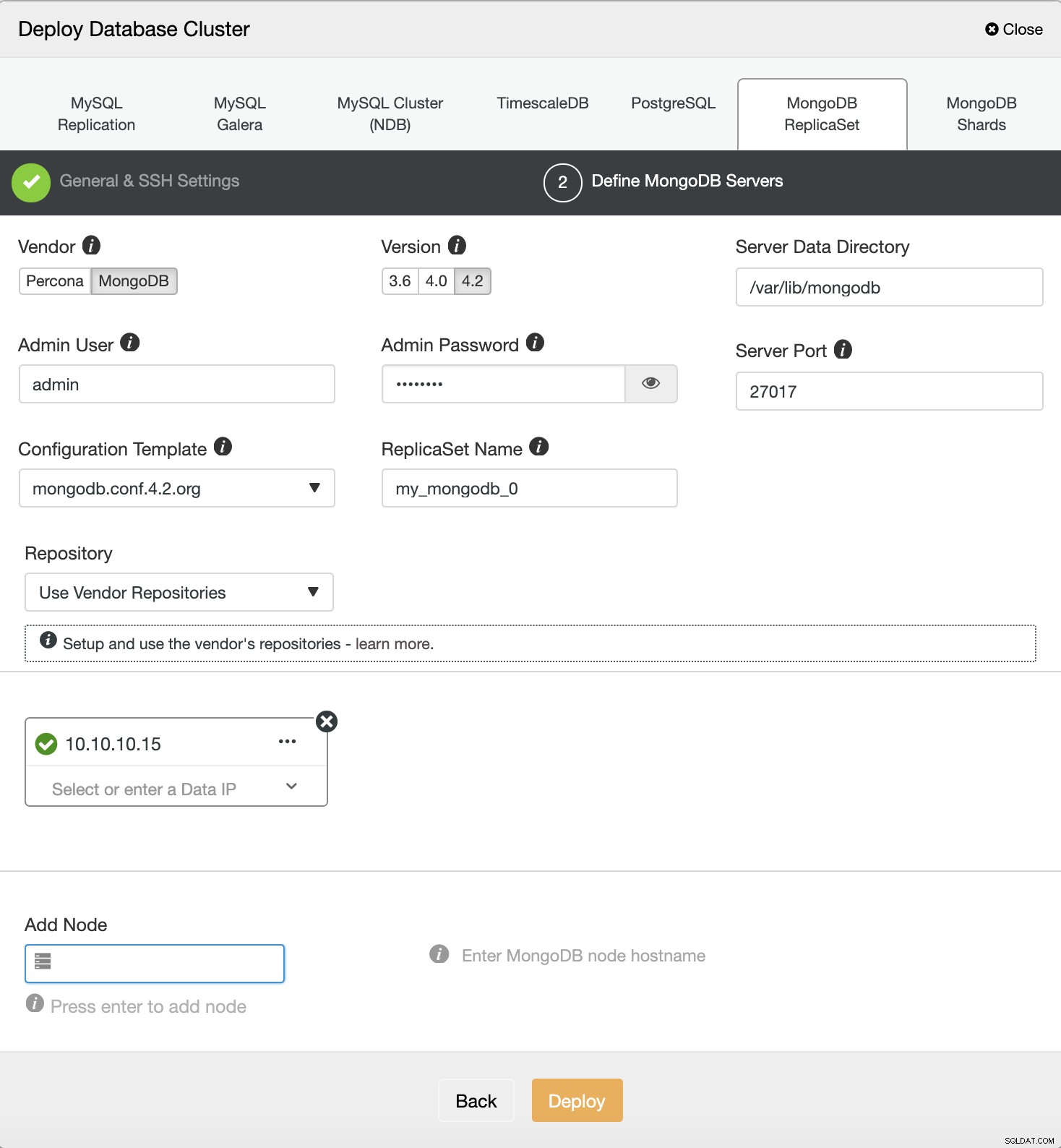
Automatización de la implementación de MongoDB usando s9s CLI
Desde la interfaz de línea de comandos, se pueden utilizar las herramientas s9s. La implementación de MongoDB usando s9s es solo un comando de una línea como se muestra a continuación:
$ s9s cluster --create --cluster-type=mongodb --nodes="10.10.10.15" --vendor=percona --provider-version=4.2 --db-admin-passwd="12qwaszx" --os-user=vagrant --cluster-name="MongoDB" --wait
Create Mongo Cluster
/ Job 183 FINISHED [██████████] 100% Job finished.
Por lo tanto, implementar MongoDB, ya sea un ReplicaSet o un Sharded Cluster, es muy fácil y ClusterControl lo automatiza completamente.



