Mejorar el rendimiento del sistema, especialmente para las estructuras informáticas, requiere un proceso para obtener una buena visión general del rendimiento. Este proceso generalmente se llama monitoreo. El monitoreo es una parte esencial de la administración de la base de datos y la información detallada sobre el rendimiento de su MongoDB no solo lo ayudará a medir su estado funcional; pero también dan una pista sobre las anomalías, lo que es útil cuando se realiza el mantenimiento. Es esencial identificar comportamientos inusuales y corregirlos antes de que se conviertan en fallas más graves.
Algunos de los tipos de fallas que podrían surgir son...
- Retraso o desaceleración
- Insuficiencia de recursos
- Problemas del sistema
El monitoreo a menudo se centra en el análisis de métricas. Algunas de las métricas clave que querrá monitorear incluyen...
- Rendimiento de la base de datos
- Uso de recursos (uso de CPU, memoria disponible y uso de red)
- Retrocesos emergentes
- Saturación y limitación de los recursos
- Operaciones de rendimiento
En este blog, discutiremos en detalle estas métricas y veremos las herramientas disponibles de MongoDB (como utilidades y comandos). También veremos otras herramientas de software como Pandora, FMS Open Source y Robo 3T. En aras de la simplicidad, vamos a utilizar el software Robo 3T en este artículo para demostrar las métricas.
Rendimiento de la Base de Datos
Lo primero y más importante que debe verificar en una base de datos es su rendimiento general, por ejemplo, si el servidor está activo o no. Si ejecuta este comando db.serverStatus() en una base de datos en Robo 3T, se le presentará esta información que muestra el estado de su servidor.
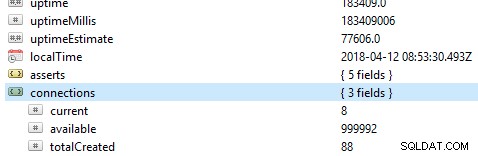

Conjuntos de réplicas
El conjunto de réplicas es un grupo de procesos mongod que mantienen el mismo conjunto de datos. Si utiliza conjuntos de réplicas, especialmente en el modo de producción, los registros de operaciones proporcionarán una base para el proceso de réplica. Todas las operaciones de escritura se rastrean mediante nodos, es decir, un nodo principal y un nodo secundario, que almacenan una colección de tamaño limitado. En el nodo principal, las operaciones de escritura se aplican y procesan. Sin embargo, si el nodo principal falla antes de que se copien en los registros de operación, entonces se realiza la escritura secundaria, pero en este caso es posible que los datos no se repliquen.
Métricas clave a tener en cuenta...
Retraso de replicación
Esto define qué tan lejos está el nodo secundario detrás del nodo principal. Un estado óptimo requiere que la brecha sea lo más pequeña posible. En un sistema operativo normal, se estima que este retraso es 0. Si la brecha es demasiado amplia, la integridad de los datos se verá comprometida una vez que el nodo secundario se promocione a principal. En este caso, puede establecer un umbral, por ejemplo, 1 minuto, y si se supera, se establece una alerta. Las causas comunes de un amplio retraso en la replicación incluyen...
- Fragmentos que pueden tener una capacidad de escritura insuficiente que a menudo se asocia con la saturación de recursos.
- El nodo secundario proporciona datos a un ritmo más lento que el nodo principal.
- También es posible que los nodos no puedan comunicarse de alguna manera, posiblemente debido a una red deficiente.
- Las operaciones en el nodo principal también podrían ser más lentas, lo que bloquearía la replicación. Si esto sucede, puede ejecutar los siguientes comandos:
- db.getProfilingLevel():si obtiene un valor de 0, entonces sus operaciones de base de datos son óptimas.
Si el valor es 1, entonces corresponde a operaciones lentas que, en consecuencia, pueden deberse a consultas lentas. - db.getProfilingStatus():en este caso comprobamos el valor de slowms, por defecto es 100ms. Si el valor es mayor que esto, es posible que tenga operaciones de escritura intensas en los recursos primarios o inadecuados en el secundario. Para resolver esto, puede escalar el secundario para que tenga tantos recursos como el principal.
- db.getProfilingLevel():si obtiene un valor de 0, entonces sus operaciones de base de datos son óptimas.
Cursores
Si realiza una solicitud de lectura, por ejemplo, buscar, se le proporcionará un cursor que es un puntero al conjunto de datos del resultado. Si ejecuta este comando db.serverStatus() y navega hasta el objeto de métricas y luego el cursor, verá esto...

En este caso, la propiedad cursor.timeOut se actualizó de forma incremental a 9 porque hubo 9 conexiones que fallaron sin cerrar el cursor. La consecuencia es que permanecerá abierto en el servidor y, por lo tanto, consumirá memoria, a menos que la configuración predeterminada de MongoDB lo coseche. Una alerta para usted debería ser identificar cursores no activos y cosecharlos para guardarlos en la memoria. También puede evitar los cursores sin tiempo de espera porque a menudo retienen recursos, lo que ralentiza el rendimiento del sistema interno. Esto se puede lograr estableciendo el valor de la propiedad cursor.open.noTimeout en un valor de 0.
Diario
Teniendo en cuenta el motor de almacenamiento WiredTiger, antes de que se registren los datos, primero se escriben en los archivos del disco. Esto se conoce como diario. El registro en diario garantiza la disponibilidad y durabilidad de los datos en caso de falla a partir de la cual se puede realizar una recuperación.
A los efectos de la recuperación, a menudo usamos puntos de control (especialmente para el sistema de almacenamiento WiredTiger) para recuperarse desde el último punto de control. Sin embargo, si MongoDB se cierra inesperadamente, usamos la técnica de registro en diario para recuperar los datos que se procesaron o proporcionaron después del último punto de control.
El registro en diario no debe desactivarse en el primer caso, ya que solo se necesitan unos 60 segundos para crear un nuevo punto de control. Por lo tanto, si ocurre una falla, MongoDB puede reproducir el diario para recuperar los datos perdidos en estos segundos.
El registro en diario generalmente reduce el intervalo de tiempo desde que los datos se aplican a la memoria hasta que son duraderos en el disco. El objeto storage.journal tiene una propiedad que describe la frecuencia de confirmación, es decir, commitIntervalMs, que a menudo se establece en un valor de 100 ms para WiredTiger. Ajustarlo a un valor más bajo mejorará la grabación frecuente de escrituras y, por lo tanto, reducirá los casos de pérdida de datos.
Rendimiento de bloqueo
Esto puede deberse a múltiples solicitudes de lectura y escritura de muchos clientes. Cuando esto sucede, es necesario mantener la coherencia y evitar conflictos de escritura. Para lograr esto, MongoDB utiliza un bloqueo de granularidad múltiple que permite que las operaciones de bloqueo ocurran en diferentes niveles, como el nivel global, de base de datos o de colección.
Si tiene patrones de diseño de esquema deficientes, será vulnerable a que los bloqueos se mantengan durante mucho tiempo. Esto se experimenta a menudo cuando se realizan dos o más operaciones de escritura diferentes en un solo documento en la misma colección, con la consecuencia de bloquearse entre sí. Para el motor de almacenamiento WiredTiger, podemos usar el sistema de tickets donde las solicitudes de lectura o escritura provienen de algo como una cola o hilo.
De forma predeterminada, el número simultáneo de operaciones de lectura y escritura está definido por los parámetros wiredTigerConcurrentWriteTransactions y wiredTigerConcurrentReadTransactions, ambos establecidos en un valor de 128.
Si escala este valor demasiado alto, terminará limitado por los recursos de la CPU. Para aumentar el rendimiento de las operaciones, sería recomendable escalar horizontalmente proporcionando más fragmentos.
Varios nueves Conviértase en un administrador de bases de datos de MongoDB - Llevando MongoDB a la producción Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar MongoDBDescargar gratisUso de recursos
Esto generalmente describe el uso de los recursos disponibles, como la capacidad de la CPU/velocidad de procesamiento y RAM. El rendimiento, especialmente para la CPU, puede cambiar drásticamente de acuerdo con las cargas de tráfico inusuales. Las cosas que debe comprobar incluyen...
- Número de conexiones
- Almacenamiento
- caché
Número de conexiones
Si el número de conexiones es superior al que puede manejar el sistema de base de datos, habrá muchas colas. En consecuencia, esto abrumará el rendimiento de la base de datos y hará que su configuración se ejecute lentamente. Este número puede ocasionar problemas con el controlador o incluso complicaciones con su solicitud.
Si supervisa una cierta cantidad de conexiones durante un período y luego nota que ese valor ha alcanzado su punto máximo, siempre es una buena práctica configurar una alerta si la conexión excede este número.
Si el número es demasiado alto, puede escalar para atender este aumento. Para hacer esto, debe conocer la cantidad de conexiones disponibles dentro de un período determinado; de lo contrario, si las conexiones disponibles no son suficientes, las solicitudes no se manejarán de manera oportuna.
De manera predeterminada, MongoDB brinda soporte para hasta 1 millón de conexiones. Con su monitoreo, siempre asegúrese de que las conexiones actuales nunca se acerquen demasiado a este valor. Puede verificar el valor en el objeto de conexiones.

Almacenamiento
Cada fila y registro de datos en MongoDB se denomina documento. Los datos del documento están en formato BSON. En una base de datos determinada, si ejecuta el comando db.stats(), se le presentarán estos datos.
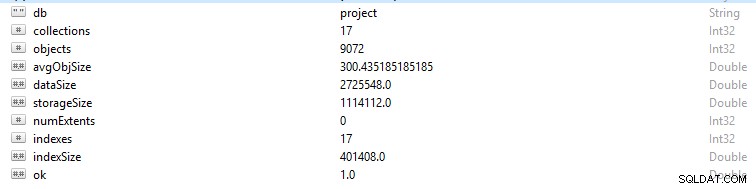
- StorageSize define el tamaño de todas las extensiones de datos en la base de datos.
- IndexSize describe el tamaño de todos los índices creados dentro de esa base de datos.
- dataSize es una medida del espacio total ocupado por los documentos en la base de datos.
A veces puede ver un cambio en la memoria, especialmente si se han eliminado muchos datos. En este caso, debe configurar una alerta para asegurarse de que no se deba a una actividad maliciosa.
A veces, el tamaño total del almacenamiento puede dispararse mientras el gráfico de tráfico de la base de datos es constante y, en este caso, debe verificar la estructura de su aplicación o base de datos para evitar tener duplicados si no son necesarios.
Al igual que la memoria general de una computadora, MongoDB también tiene cachés en las que se almacenan temporalmente los datos activos. Sin embargo, una operación puede solicitar datos que no están en esta memoria activa, por lo tanto, realizar una solicitud desde el almacenamiento del disco principal. Esta solicitud o situación se conoce como fallo de página. Las solicitudes de fallas de página vienen con la limitación de tomar más tiempo para ejecutarse y pueden ser perjudiciales cuando ocurren con frecuencia. Para evitar este escenario, asegúrese de que el tamaño de su RAM siempre sea suficiente para atender los conjuntos de datos con los que está trabajando. También debe asegurarse de no tener redundancia de esquema o índices innecesarios.
Caché
La memoria caché es un elemento de almacenamiento de datos temporal para los datos de acceso frecuente. En WiredTiger, a menudo se emplean la memoria caché del sistema de archivos y la memoria caché del motor de almacenamiento. Siempre asegúrese de que su conjunto de trabajo no sobresalga más allá del caché disponible, de lo contrario, las fallas de página aumentarán y causarán algunos problemas de rendimiento.
En algún momento, puede decidir modificar sus operaciones frecuentes, pero los cambios a veces no se reflejan en el caché. Estos datos no modificados se conocen como "datos sucios". Existe porque aún no se ha vaciado en el disco. Se producirán cuellos de botella si la cantidad de "Datos sucios" crece hasta un valor promedio definido por la escritura lenta en el disco. Agregar más fragmentos ayudará a reducir este número.
Utilización de la CPU
La indexación incorrecta, la estructura de esquema deficiente y las consultas diseñadas poco amigables requerirán más atención de la CPU, por lo que obviamente aumentará su utilización.
Operaciones de rendimiento
En gran medida, obtener suficiente información sobre estas operaciones puede permitir evitar contratiempos consecuentes, como errores, saturación de recursos y complicaciones funcionales.
Siempre debe tomar nota de la cantidad de operaciones de lectura y escritura en la base de datos, es decir, una vista de alto nivel de las actividades del clúster. Conocer la cantidad de operaciones generadas para las solicitudes le permitirá calcular la carga que se espera que maneje la base de datos. Luego, la carga se puede manejar ampliando su base de datos o escalando; dependiendo del tipo de recursos que tengas. Esto le permite medir fácilmente la relación de cociente en la que se acumulan las solicitudes a la velocidad a la que se procesan. Además, puede optimizar sus consultas adecuadamente para mejorar el rendimiento.
Para verificar la cantidad de operaciones de lectura y escritura, ejecute este comando db.serverStatus(), luego navegue hasta el objeto locks.global, el valor de la propiedad r representa la cantidad de solicitudes de lectura y w la cantidad de escrituras.
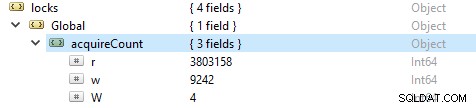
Más a menudo, las operaciones de lectura son más que las operaciones de escritura. Las métricas de clientes activos se informan bajo globalLock.
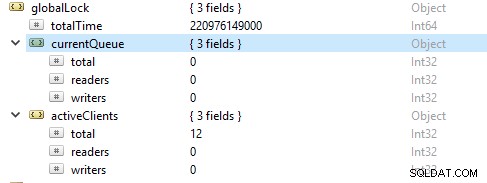
Saturación y Limitación de Recursos
A veces, la base de datos puede no mantener el ritmo de escritura y lectura, como lo demuestra un número creciente de solicitudes en cola. En este caso, debe escalar su base de datos proporcionando más fragmentos para permitir que MongoDB atienda las solicitudes lo suficientemente rápido.
Retrocesos emergentes
Los archivos de registro de MongoDB siempre brindan una descripción general de las excepciones de aserción devueltas. Este resultado le dará una pista sobre las posibles causas de los errores. Si ejecuta el comando db.serverStatus(), algunas de las alertas de error que notará incluyen:

- Afirmaciones regulares:son como resultado de una falla en la operación. Por ejemplo, en un esquema, si se proporciona un valor de cadena a un campo entero, lo que resulta en un error al leer el documento BSON.
- Afirmaciones de advertencia:a menudo son alertas sobre algún problema, pero no tienen mucho impacto en su funcionamiento. Por ejemplo, cuando actualice su MongoDB, es posible que reciba una alerta utilizando funciones obsoletas.
- Msg afirma:son el resultado de excepciones internas del servidor, como una red lenta o si el servidor no está activo.
- Afirmaciones del usuario:al igual que las afirmaciones normales, estos errores surgen cuando se ejecuta un comando, pero a menudo se devuelven al cliente. Por ejemplo, si hay claves duplicadas, espacio en disco inadecuado o ningún acceso para escribir en la base de datos. Optarás por revisar tu aplicación para corregir estos errores.



