Casi se garantiza que en algún momento se producirán cortes de producción. Aceptar este hecho y analizar la línea de tiempo y el escenario de falla de la interrupción de su base de datos puede ayudarlo a prepararse, diagnosticar y recuperarse mejor de la siguiente. Para mitigar el impacto del tiempo de inactividad, las organizaciones necesitan un plan adecuado de recuperación ante desastres (DR). La planificación de DR es una tarea crítica para muchos SysOps/DevOps, pero aunque está prevista; a menudo no existe.
En esta publicación de blog, analizaremos diferentes escenarios de respaldo y fallas en los sistemas de base de datos MongoDB. También lo guiaremos a través de los procedimientos de recuperación y conmutación por error para cada escenario respectivo. Estos casos de uso variarán desde la restauración de un solo nodo, la restauración de un nodo en un conjunto de réplicas existente y la inicialización de un nuevo nodo en un conjunto de réplicas. Con suerte, esto le dará una buena comprensión de los riesgos que podría enfrentar y qué considerar al diseñar su infraestructura.
Antes de comenzar a discutir posibles escenarios de falla, echemos un vistazo a cómo MongoDB almacena datos y qué tipos de respaldo están disponibles.
Cómo MongoDB almacena datos
MongoDB es una base de datos orientada a documentos. En lugar de almacenar sus datos en tablas hechas de filas individuales (como lo hace una base de datos relacional), almacena datos en colecciones hechas de documentos individuales. En MongoDB, un documento es un gran blob JSON sin un formato o esquema particular. Además, los datos pueden distribuirse entre diferentes nodos de clúster con el uso compartido o replicarse en servidores esclavos con replicaSet.
MongoDB permite escrituras y actualizaciones muy rápidas de forma predeterminada. La contrapartida es que a menudo no se le notifican explícitamente las fallas. De forma predeterminada, la mayoría de los controladores realizan escrituras asíncronas e inseguras. Esto significa que el controlador no devuelve un error directamente, similar a INSERT DELAYED con MySQL. Si desea saber si algo tuvo éxito, debe verificar manualmente los errores usando getLastError.
Para un rendimiento óptimo, es preferible usar SSD en lugar de HDD para el almacenamiento. Es necesario cuidar si su almacenamiento es local o remoto y tomar las medidas correspondientes. Es mejor usar RAID para la protección de defectos de hardware y esquemas de recuperación, pero no confíe completamente en él, ya que no ofrece protección contra fallas adversas. El hardware adecuado es la piedra angular de su aplicación para optimizar el rendimiento y evitar una gran debacle.
La corrupción de datos a nivel de disco o la falta de archivos de datos pueden impedir que se inicien las instancias de mongod, y los archivos de diario pueden ser insuficientes para recuperarse automáticamente.
Si está ejecutando con el diario habilitado, casi nunca hay necesidad de ejecutar la reparación ya que el servidor puede usar los archivos de diario para restaurar los archivos de datos a un estado limpio automáticamente. Sin embargo, es posible que aún deba ejecutar la reparación en los casos en que necesite recuperarse de la corrupción de datos a nivel de disco.
Si el diario no está habilitado, su única opción puede ser ejecutar el comando de reparación. mongod --repair debe usarse solo si no tiene otras opciones, ya que la operación elimina (y no guarda) los datos corruptos durante el proceso de reparación. Este tipo de operación siempre debe ir precedida de una copia de seguridad.
Escenario de recuperación ante desastres de MongoDB
En un plan de recuperación de fallas, su objetivo de punto de recuperación (RPO) es un parámetro de recuperación clave que determina la cantidad de datos que puede permitirse perder. RPO se enumera en el tiempo, desde milisegundos hasta días, y depende directamente de su sistema de respaldo. Considera la antigüedad de sus datos de copia de seguridad que debe recuperar para reanudar las operaciones normales.
Para estimar el RPO, debe hacerse algunas preguntas. ¿Cuándo se realiza una copia de seguridad de mis datos? ¿Cuál es el SLA asociado con la recuperación de los datos? ¿Es aceptable restaurar una copia de seguridad de los datos o es necesario que los datos estén en línea y listos para ser consultados en cualquier momento?
Las respuestas a estas preguntas ayudarán a decidir qué tipo de solución de copia de seguridad necesita.
Soluciones de copia de seguridad de MongoDB
Las técnicas de respaldo tienen diversos impactos en el rendimiento de la base de datos en ejecución. Algunas soluciones de copia de seguridad degradan el rendimiento de la base de datos lo suficiente como para que necesite programar copias de seguridad para evitar el uso máximo o las ventanas de mantenimiento. Puede decidir implementar nuevos servidores secundarios solo para admitir copias de seguridad.
Las tres soluciones más comunes para respaldar su servidor/clúster MongoDB son...
- Mongodump/Mongorestore:copia de seguridad lógica.
- Mongo Management System (Cloud):las bases de datos de producción se pueden respaldar con MongoDB Ops Manager o, si usa el servicio MongoDB Atlas, puede usar una solución de respaldo completamente administrada.
- Instantáneas de la base de datos (copia de seguridad a nivel de disco)
Mongodump/Mongorestore
Al realizar un mongodump, todas las colecciones dentro de las bases de datos designadas se volcarán como salida BSON. Si no se especifica ninguna base de datos, MongoDB volcará todas las bases de datos excepto las bases de datos locales, de prueba y de administración, ya que están reservadas para uso interno.
Por defecto, mongodump creará un directorio llamado dump, con un directorio para cada base de datos que contenga un archivo BSON por colección en esa base de datos. Alternativamente, puede decirle a mongodump que almacene la copia de seguridad en un solo archivo. El parámetro de archivo concatenará la salida de todas las bases de datos y colecciones en un solo flujo de datos binarios. Además, el parámetro gzip puede comprimir naturalmente este archivo usando gzip. En ClusterControl transmitimos todas nuestras copias de seguridad, por lo que habilitamos los parámetros de archivo y gzip.
Al igual que mysqldump con MySQL, si crea una copia de seguridad en MongoDB, congelará las colecciones mientras descarga el contenido en el archivo de copia de seguridad. Como MongoDB no admite transacciones (modificado en 4.2), no puede realizar una copia de seguridad totalmente coherente al 100 % a menos que cree la copia de seguridad con el parámetro oplog. Habilitar esto en la copia de seguridad incluye las transacciones del registro de operaciones que se estaban ejecutando mientras se realizaba la copia de seguridad.
Para una mejor automatización, puede ejecutar MongoDB desde la línea de comandos o usar herramientas externas como ClusterControl. ClusterControl es la opción recomendada para la gestión y automatización de copias de seguridad, ya que permite crear estrategias de copia de seguridad avanzadas para varios sistemas de bases de datos de código abierto.
ClusterControl le permite cargar su copia de seguridad en la nube. Admite copias de seguridad completas y restaura el cifrado de mongodump. Si quieres ver cómo funciona, hay una demostración en nuestro sitio web.
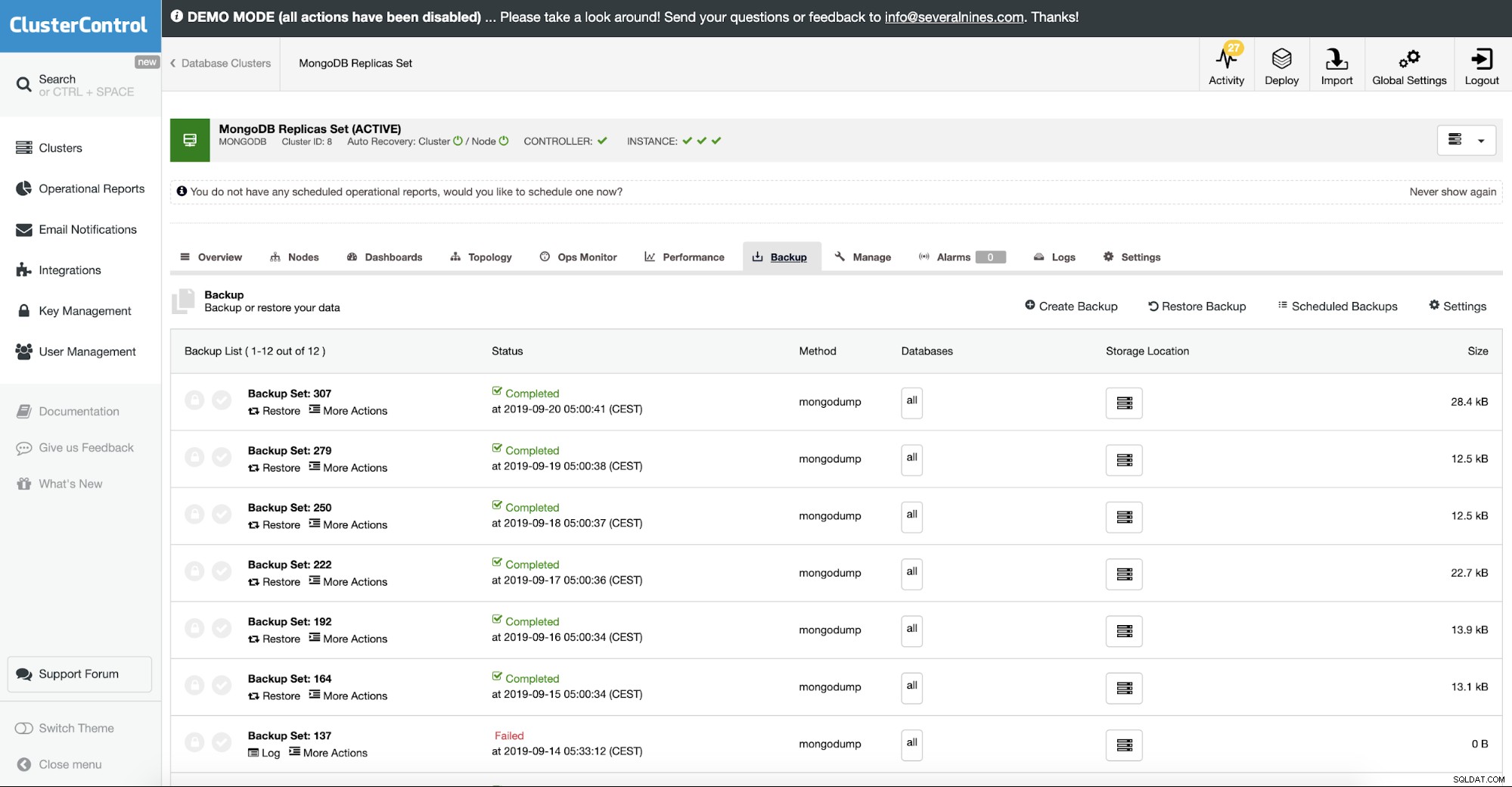
Restauración de MongoDB desde una copia de seguridad
Básicamente, hay dos formas de utilizar un volcado de formato BSON:
- Ejecute mongod directamente desde el directorio de copia de seguridad
- Ejecute mongorestore y restaure la copia de seguridad
Ejecute mongod directamente desde una copia de seguridad
Un requisito previo para ejecutar mongod directamente desde la copia de seguridad es que el destino de la copia de seguridad sea un volcado estándar y no esté comprimido con gzip.
El daemon de MongoDB verificará la integridad del directorio de datos, agregará la base de datos de administración, revistas, catálogos de colección e índice y algunos otros archivos necesarios para ejecutar MongoDB. Si antes ejecutó WiredTiger como motor de almacenamiento, ahora ejecutará las colecciones existentes como MMAP. Para volcados de datos simples o comprobaciones de integridad, esto funciona bien.
Ejecutando mongorestore
Obviamente, una mejor manera de restaurar sería restaurar el nodo mediante mongorestore.
mongorestore dump/Esto restaurará la copia de seguridad a la configuración predeterminada del servidor (localhost, puerto 27017) y sobrescribirá cualquier base de datos en la copia de seguridad que resida en este servidor. Ahora hay toneladas de parámetros para manipular el proceso de restauración y cubriremos algunos de los más importantes.
En ClusterControl esto se hace en la opción de restauración de copia de seguridad. Puede elegir la máquina en la que se restaurará la copia de seguridad y el proceso se encargará del resto. Esto incluye una copia de seguridad cifrada donde normalmente también necesitaría descifrar su copia de seguridad.
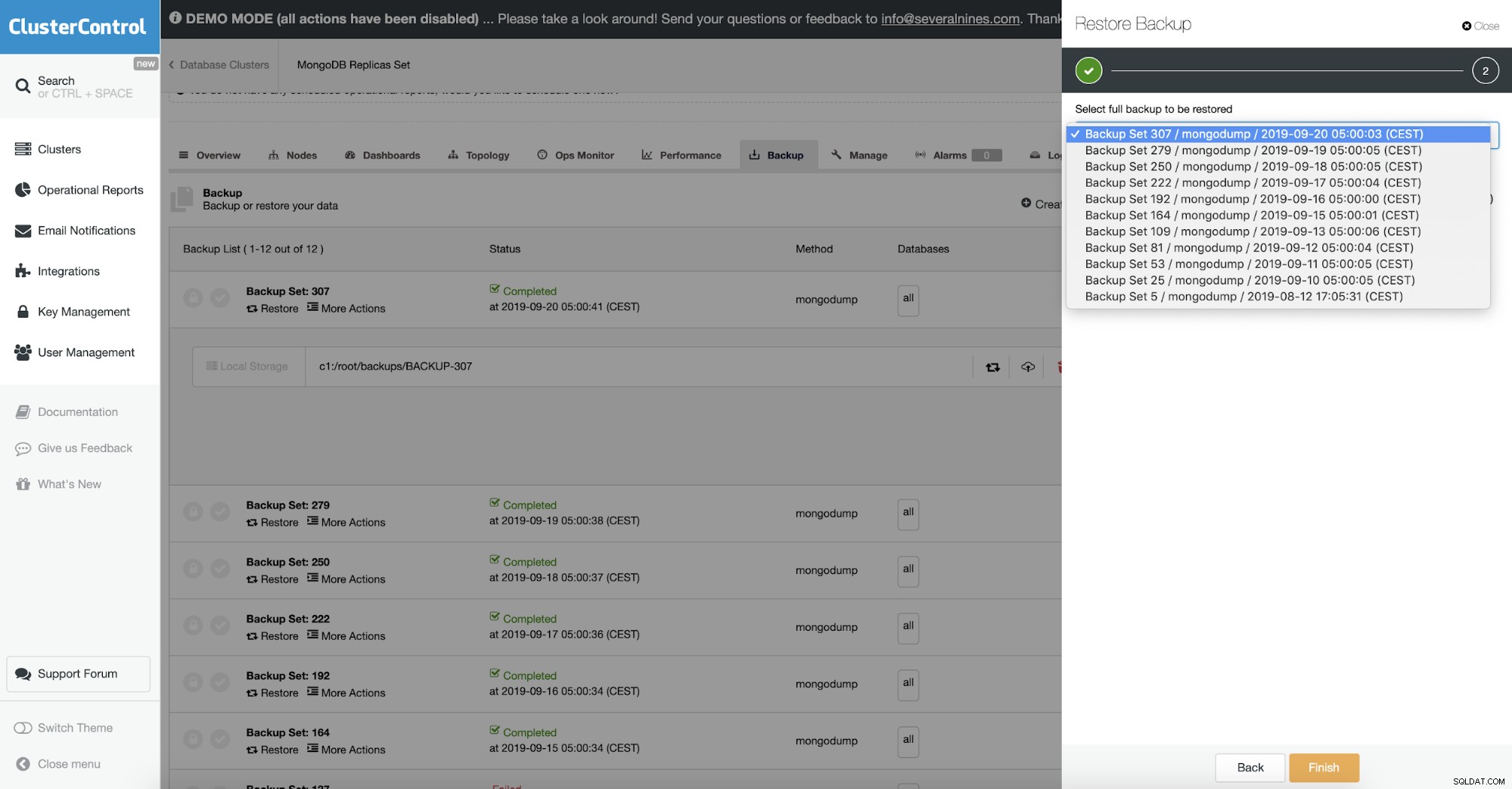
Validación de objetos
Como la copia de seguridad contiene datos BSON, esperaría que el contenido de la copia de seguridad sea correcto. Sin embargo, podría haber sido el caso de que el documento que se descartó estuviera mal formado, para empezar. Mongodump no comprueba la integridad de los datos que descarga.
Para abordar ese uso, objcheck que obliga a mongorestore a validar todas las solicitudes de los clientes al recibirlas para garantizar que los clientes nunca inserten documentos no válidos en la base de datos. Puede tener un pequeño impacto en el rendimiento.
Reproducción de Oplog
Oplog a su copia de seguridad le permitirá realizar una copia de seguridad consistente y hacer una recuperación puntual. Habilite el parámetro oplogReplay para aplicar el registro de operaciones durante el proceso de restauración. Para controlar hasta dónde reproducir el registro de operaciones, puede definir una marca de tiempo en el parámetro oplogLimit. Solo se aplicarán las transacciones hasta la marca de tiempo.
Restauración de un conjunto de réplicas completo a partir de una copia de seguridad
Restaurar un conjunto de réplicas no es muy diferente a restaurar un solo nodo. Primero debe configurar el replicaSet y restaurarlo directamente en el replicaSet. O restaura primero un solo nodo y luego usa este nodo restaurado para crear un conjunto de réplicas.
Restaurar nodo primero, luego crear replicaSet
Ahora el segundo y tercer nodo sincronizarán sus datos desde el primer nodo. Una vez finalizada la sincronización, nuestro conjunto de réplicas se ha restaurado.
Cree un ReplicaSet primero, luego restaure
A diferencia del proceso anterior, puede crear primero el replicaSet. Primero configure los tres hosts con replicaSet habilitado, inicie los tres demonios e inicie replicaSet en el primer nodo:
Ahora que hemos creado el conjunto de réplicas, podemos restaurar directamente nuestra copia de seguridad en él:
En nuestra opinión, restaurar una réplica de esta manera es mucho más elegante. Se parece más a la forma en que normalmente configuraría un nuevo conjunto de réplicas desde cero y luego lo llenaría con datos (de producción).
Inicio de un nuevo nodo en un conjunto de réplicas
Al escalar horizontalmente un clúster mediante la adición de un nuevo nodo en MongoDB, debe realizarse la sincronización inicial del conjunto de datos. Con la replicación de MySQL y Galera, estamos tan acostumbrados a usar una copia de seguridad para generar la sincronización inicial. Con MongoDB esto es posible, pero solo haciendo una copia binaria del directorio de datos. Si no tiene los medios para hacer una instantánea del sistema de archivos, tendrá que enfrentar el tiempo de inactividad en uno de los nodos existentes. El proceso, con tiempo de inactividad, se describe a continuación.
Sembrar con una copia de seguridad
Entonces, ¿qué sucedería si restaura el nuevo nodo desde una copia de seguridad mongodump y luego hace que se una a un replicaSet? La restauración desde una copia de seguridad debería, en teoría, proporcionar el mismo conjunto de datos. Como este nuevo nodo se ha restaurado a partir de una copia de seguridad, le faltará el replicaSetId y MongoDB lo notará. Como MongoDB no ve este nodo como parte del replicaSet, el comando rs.add() siempre activará la sincronización inicial de MongoDB. La sincronización inicial siempre activará la eliminación de cualquier dato existente en el nodo MongoDB.
El replicaSetId se genera cuando se inicia un replicaSet y, lamentablemente, no se puede configurar manualmente. Es una pena, ya que la recuperación de una copia de seguridad (incluida la reproducción del registro de operaciones) teóricamente nos daría un conjunto de datos 100% idéntico. Sería bueno si la sincronización inicial fuera opcional en MongoDB para satisfacer este caso de uso.



