La conmutación por error automática para la replicación de MySQL ha sido objeto de debate durante muchos años.
¿Es algo bueno o malo?
Aquellos con mucha memoria en el mundo de MySQL, quizás recuerden la interrupción de GitHub en 2012, que se debió principalmente a que el software tomó decisiones equivocadas.
GitHub acababa de migrar a una combinación de MySQL Replication, Corosync, Pacemaker y Percona Replication Manager. PRM decidió realizar una conmutación por error después de fallar las comprobaciones de estado en el maestro, que se sobrecargó durante una migración de esquema. Se seleccionó un nuevo maestro, pero tuvo un desempeño deficiente debido a los cachés fríos. La alta carga de consultas del sitio ocupado hizo que los latidos del corazón de PRM fallaran nuevamente en el maestro frío, y luego PRM desencadenó otra conmutación por error al maestro original. Y los problemas continuaron, como se resume a continuación.
 Fuente:Henrik Ingo y Massimo Brignoli en Percona Live 2013
Fuente:Henrik Ingo y Massimo Brignoli en Percona Live 2013 Avance rápido un par de años y GitHub está de regreso con un marco bastante sofisticado para administrar la replicación de MySQL y la conmutación por error automatizada. Como dice Shlomi Noach:
“A tal efecto, empleamos conmutación por error maestra automatizada. El tiempo que le tomaría a un humano despertar y reparar un maestro fallido está más allá de nuestra expectativa de disponibilidad, y operar una conmutación por error de este tipo a veces no es trivial. Esperamos que las fallas maestras se detecten y recuperen automáticamente en 30 segundos o menos, y esperamos que la conmutación por error resulte en una pérdida mínima de hosts disponibles”.
La mayoría de las empresas no son GitHub, pero se podría argumentar que a ninguna empresa le gustan las interrupciones. Las interrupciones son perjudiciales para cualquier negocio y también cuestan dinero. Mi conjetura es que la mayoría de las empresas probablemente desearían tener algún tipo de conmutación por error automatizada, y las razones para no implementarla son probablemente la complejidad de las soluciones existentes, la falta de competencia para implementar tales soluciones o la falta de confianza en el software para tomar una decisión tan importante.
Existen varias soluciones de conmutación por error automatizadas, incluidas (entre otras) MHA, MMM, MRM, mysqlfailover, Orchestrator y ClusterControl. Algunos de ellos llevan varios años en el mercado, otros son más recientes. Esa es una buena señal, múltiples soluciones significan que el mercado está ahí y las personas están tratando de abordar el problema.
Cuando diseñamos la conmutación por error automática dentro de ClusterControl, usamos algunos principios rectores:
-
Asegúrese de que el maestro esté realmente inactivo antes de realizar la conmutación por error
En el caso de una partición de red, donde el software de conmutación por error pierde contacto con el maestro, dejará de verlo. Pero el maestro podría estar funcionando bien y el resto de la topología de replicación puede verlo.
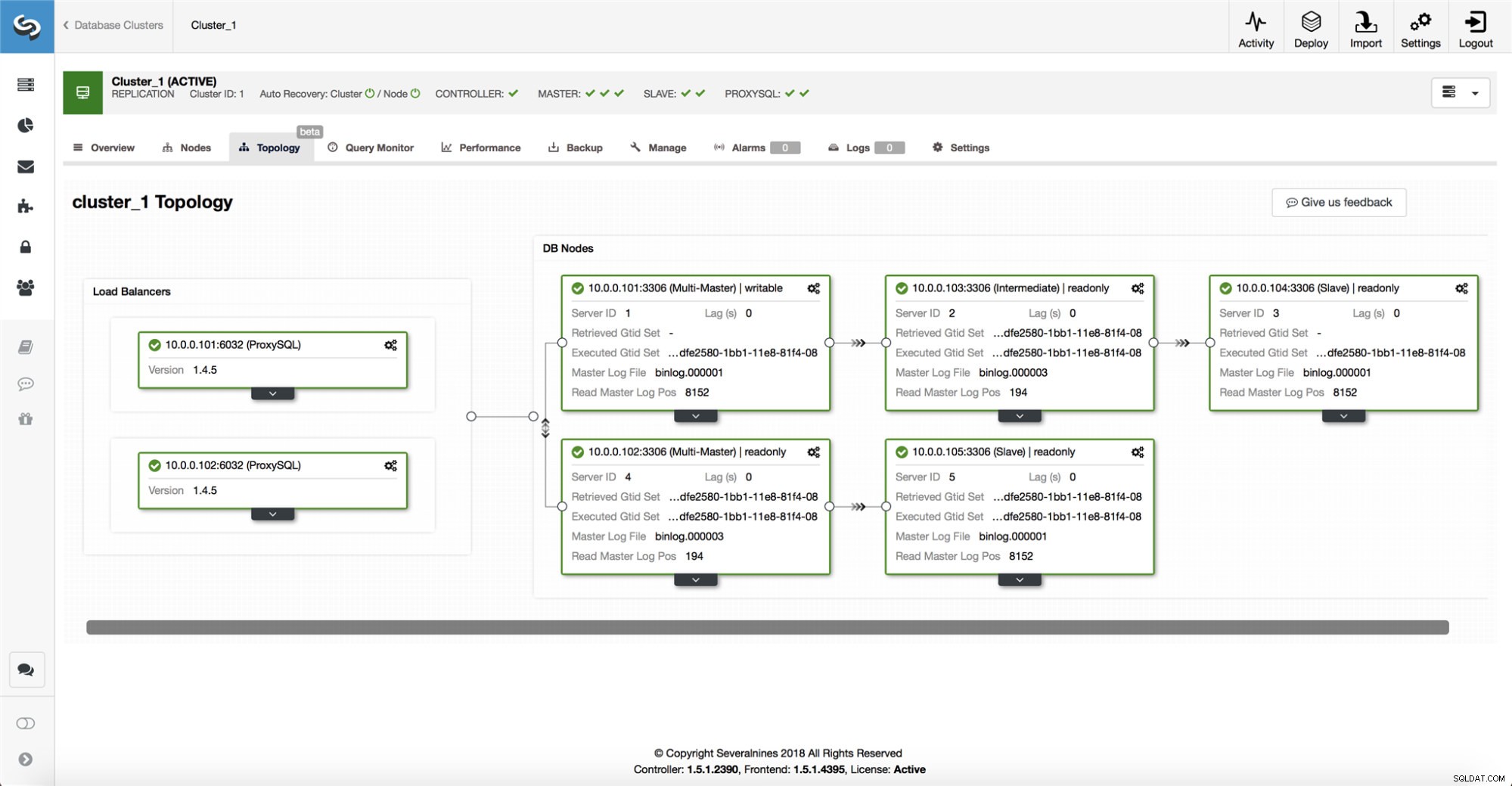
ClusterControl recopila información de todos los nodos de la base de datos, así como de los proxies de la base de datos/equilibradores de carga utilizados, y luego crea una representación de la topología. No intentará una conmutación por error si los esclavos pueden ver al maestro, ni si ClusterControl no está 100% seguro sobre el estado del maestro.
ClusterControl también facilita la visualización de la topología de la configuración, así como el estado de los diferentes nodos (esta es la comprensión de ClusterControl del estado del sistema, en función de la información que recopila).
-
Conmutación por error solo una vez
Mucho se ha escrito sobre el aleteo. Puede complicarse mucho si la herramienta de disponibilidad decide realizar varias conmutaciones por error. Esa es una situación peligrosa. Cada maestro elegido, por breve que haya sido el período en que ocupó el rol de maestro, podría tener sus propios conjuntos de cambios que nunca se replicaron en ningún servidor. Por lo tanto, puede terminar con inconsistencias entre todos los maestros elegidos.
-
No realice la conmutación por error a un esclavo inconsistente
Al seleccionar un esclavo para promocionarlo como maestro, nos aseguramos de que el esclavo no tenga inconsistencias, p. transacciones errantes, ya que esto puede interrumpir la replicación.
-
Solo escribe al maestro
La replicación va del maestro al esclavo(s). Escribir directamente a un esclavo crearía un conjunto de datos divergente, y eso puede ser una fuente potencial de problemas. Configuramos los esclavos en read_only y super_read_only en versiones más recientes de MySQL o MariaDB. También recomendamos el uso de un equilibrador de carga, por ejemplo, ProxySQL o MaxScale, para proteger la capa de la aplicación de la topología de la base de datos subyacente y cualquier cambio en ella. El equilibrador de carga también impone escrituras en el maestro actual.
-
No recuperar automáticamente el maestro fallido
Si el maestro ha fallado y se ha elegido un nuevo maestro, ClusterControl no intentará recuperar el maestro fallido. ¿Por qué? Ese servidor podría tener datos que aún no se han replicado, y el administrador tendría que investigar un poco la falla. De acuerdo, aún puede configurar ClusterControl para borrar los datos en el maestro fallido y hacer que se una como esclavo al nuevo maestro, si está de acuerdo con perder algunos datos. Pero, de forma predeterminada, ClusterControl permitirá que el maestro fallido sea, hasta que alguien lo mire y decida volver a introducirlo en la topología.
Entonces, ¿debería automatizar la conmutación por error? Depende de cómo haya configurado la replicación. Las configuraciones de replicación circular con varios maestros con capacidad de escritura o topologías complejas probablemente no sean buenas candidatas para la conmutación por error automática. Nos ceñiríamos a los principios anteriores al diseñar una solución de replicación.
En PostgreSQL
Cuando se trata de la replicación de transmisión de PostgreSQL, ClusterControl utiliza principios similares para automatizar la conmutación por error. Para PostgreSQL, ClusterControl admite modelos de replicación asíncronos y síncronos entre el maestro y los esclavos. En ambos casos y en caso de fallo, se elige como nuevo maestro al esclavo con los datos más actualizados. Los maestros fallidos no se recuperan/reparan automáticamente para volver a unirse a la configuración de replicación.
Se toman algunas medidas de protección para asegurarse de que el maestro fallido esté inactivo y permanezca inactivo, p. se elimina del conjunto de equilibrio de carga en el proxy y se elimina si, p. el usuario lo reiniciaría manualmente. Allí es un poco más desafiante detectar divisiones de red entre ClusterControl y el maestro, ya que los esclavos no brindan ninguna información sobre el estado del maestro desde el que se están replicando. Por lo tanto, es importante un proxy frente a la configuración de la base de datos, ya que puede proporcionar otra ruta al maestro.
En MongoDB
La replicación de MongoDB dentro de un conjunto de réplicas a través de oplog es muy similar a la replicación de binlog, entonces, ¿cómo es que MongoDB recupera automáticamente un maestro fallido? El problema sigue ahí, y MongoDB lo soluciona revirtiendo los cambios que no se replicaron en los esclavos en el momento de la falla. Esos datos se eliminan y se colocan en una carpeta de "reversión", por lo que depende del administrador restaurarlos.
Para obtener más información, consulte ClusterControl; y no dude en comentar o hacer preguntas a continuación.



