El mantenimiento es algo que un equipo de operación no puede evitar. Los servidores deben mantenerse al día con el software, el hardware y la tecnología más recientes para garantizar que los sistemas sean estables y se ejecuten con el menor riesgo posible, al tiempo que utilizan funciones más nuevas para mejorar el rendimiento general.
Sin duda, existe una larga lista de tareas de mantenimiento que deben realizar los administradores de sistemas, especialmente cuando se trata de sistemas críticos. Algunas de las tareas deben realizarse a intervalos regulares, como diariamente, semanalmente, mensualmente y anualmente. Algunas tienen que hacerse de inmediato, con urgencia. Sin embargo, cualquier operación de mantenimiento no debería conducir a otro problema mayor, y cualquier mantenimiento debe manejarse con especial cuidado para evitar cualquier interrupción del negocio.
Obtener estados cuestionables y falsas alarmas es común mientras el mantenimiento está en curso. Esto es de esperar porque durante el período de mantenimiento, el servidor no funcionará como debería hasta que se complete la tarea de mantenimiento. ClusterControl, la plataforma integral de administración y monitoreo para sus bases de datos de código abierto, se puede configurar para comprender estas circunstancias y simplificar sus rutinas de mantenimiento, sin sacrificar las funciones de monitoreo y automatización que ofrece.
Modo de mantenimiento
ClusterControl introdujo el modo de mantenimiento en la versión 1.4.0, donde puede poner un nodo individual en mantenimiento, lo que evita que ClusterControl emita alarmas y envíe notificaciones durante la duración especificada. El modo de mantenimiento se puede configurar desde la interfaz de usuario de ClusterControl y también mediante la herramienta CLI de ClusterControl llamada "s9s". Desde la interfaz de usuario, simplemente vaya a Nodos -> elija un nodo -> Acciones de nodo -> Programar modo de mantenimiento :
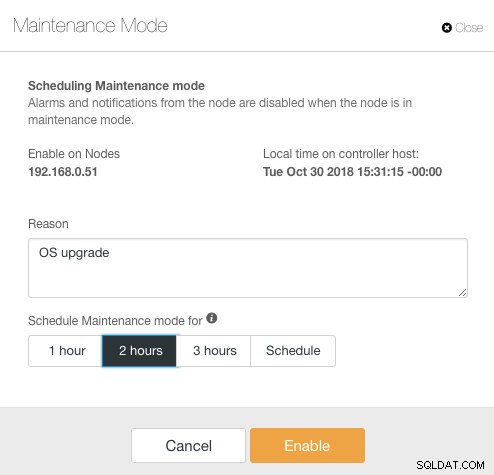
Aquí, uno puede establecer el período de mantenimiento para un tiempo predefinido o programarlo en consecuencia. También puede anotar el motivo de la programación de la actualización, útil para fines de auditoría. Debería ver la siguiente notificación cuando el modo de mantenimiento está activo:
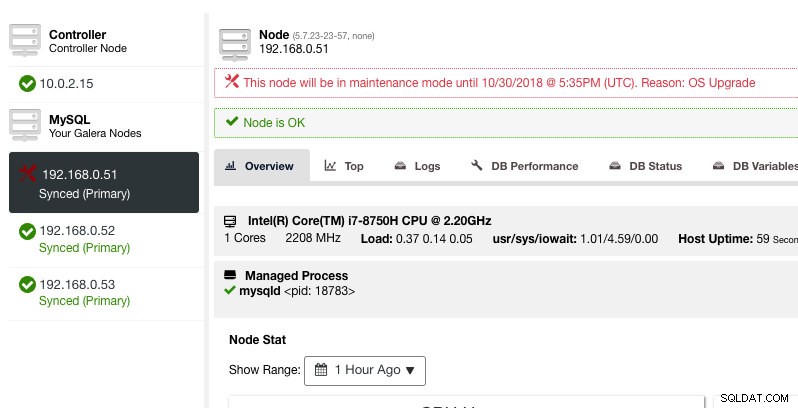
ClusterControl no degradará el nodo, por lo tanto, el estado del nodo permanece como está a menos que realice alguna acción que cambie el estado. Las alarmas y notificaciones para este nodo se reactivarán una vez que finalice el período de mantenimiento, o el operador lo deshabilite explícitamente yendo a Acciones del nodo -> Deshabilitar modo de mantenimiento .
Tenga en cuenta que si la recuperación automática de nodos está habilitada, ClusterControl siempre recuperará un nodo independientemente del estado del modo de mantenimiento. No olvide deshabilitar la recuperación de nodos para evitar que ClusterControl interfiera en sus tareas de mantenimiento, esto se puede hacer desde la barra de resumen superior.
El modo de mantenimiento también se puede configurar a través de ClusterControl CLI o "s9s". Puede usar el comando "mantenimiento s9s" para enumerar y manipular los períodos de mantenimiento. La siguiente línea de comando programa una ventana de mantenimiento de una hora para el nodo 192.168.1.121 mañana:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Para obtener más detalles y ejemplos, consulte la documentación de mantenimiento de s9s.
Modo de mantenimiento en todo el clúster
Al momento de escribir este artículo, la configuración del modo de mantenimiento debe configurarse por nodo administrado. Para el mantenimiento de todo el clúster, se debe repetir el proceso de programación para cada nodo administrado del clúster. Esto puede ser poco práctico si tiene una gran cantidad de nodos en su clúster o si el intervalo de mantenimiento es muy corto entre dos tareas.
Afortunadamente, la CLI de ClusterControl (también conocida como s9s) se puede utilizar como una solución alternativa para superar esta limitación. Puede usar "nodos s9s" para enumerar y manipular los nodos administrados en un clúster. Esta lista se puede repetir para programar un modo de mantenimiento de todo el clúster en un momento determinado mediante el comando "mantenimiento s9s".
Veamos un ejemplo para entender esto mejor. Considere el siguiente clúster Percona XtraDB de tres nodos que tenemos:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4El clúster tiene un total de 4 nodos:3 nodos de base de datos con un nodo ClusterControl. La primera columna, STAT, muestra el rol y el estado del nodo. El primer carácter es el rol del nodo:"c" significa controlador y "g" significa nodo de base de datos de Galera. Supongamos que queremos programar solo los nodos de la base de datos para el mantenimiento, podemos filtrar la salida para obtener el nombre de host o la dirección IP donde el STAT informado tiene "g" al principio:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Con una iteración simple, podemos programar una ventana de mantenimiento de todo el clúster para cada nodo del clúster. El siguiente comando itera la creación de mantenimiento en función de todas las direcciones IP encontradas en el clúster mediante un bucle for, donde planeamos comenzar la operación de mantenimiento a la misma hora mañana y finalizar una hora más tarde:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bDebería ver una copia impresa de 3 UUID, la cadena única que identifica cada período de mantenimiento. Entonces podemos verificar con el siguiente comando:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Del resultado anterior, obtuvimos una lista de tiempos de mantenimiento programados para cada nodo de la base de datos. Durante el tiempo programado, ClusterControl no activará alarmas ni enviará notificaciones si encuentra irregularidades en el clúster.
Iteración del modo de mantenimiento
Algunas rutinas de mantenimiento deben realizarse a intervalos regulares, por ejemplo, copias de seguridad, mantenimiento y tareas de limpieza. Durante el tiempo de mantenimiento, esperaríamos que el servidor se comportara de manera diferente. Sin embargo, cualquier falla en el servicio, inaccesibilidad temporal o alta carga seguramente causaría estragos en nuestro sistema de monitoreo. Para los intervalos de mantenimiento frecuentes y de intervalos cortos, esto podría resultar muy molesto y omitir las falsas alarmas activadas podría permitirle dormir mejor durante la noche.
Sin embargo, habilitar el modo de mantenimiento también puede exponer el servidor a un riesgo mayor, ya que se ignora la supervisión estricta durante el período de tiempo. Por lo tanto, probablemente sea una buena idea comprender la naturaleza de la operación de mantenimiento que nos gustaría realizar antes de habilitar el modo de mantenimiento. La siguiente lista de verificación debería ayudarnos a determinar nuestra política de modo de mantenimiento:
- Nodos afectados:¿qué nodos están involucrados en el mantenimiento?
- Consecuencias:¿qué sucede con el nodo cuando la operación de mantenimiento está en curso? ¿Será inaccesible, con mucha carga o reiniciado?
- Duración:¿cuánto tiempo tarda en completarse la operación de mantenimiento?
- Frecuencia:¿Con qué frecuencia debe ejecutarse la operación de mantenimiento?
Pongámoslo en un caso de uso. Considere que tenemos un clúster Percona XtraDB de tres nodos con un nodo ClusterControl. Supongamos que todos nuestros servidores se ejecutan en máquinas virtuales y la política de copia de seguridad de VM requiere que se realice una copia de seguridad de todas las VM todos los días a partir de la 1:00 a. m., un nodo a la vez. Durante esta operación de respaldo, el nodo se congelará durante aproximadamente 10 minutos como máximo y el nodo que está siendo administrado y monitoreado por ClusterControl será inaccesible hasta que finalice el respaldo. Desde la perspectiva de Galera Cluster, esta operación no detiene todo el clúster ya que el clúster permanece en quórum y el componente principal no se ve afectado.
Según la naturaleza de la tarea de mantenimiento, podemos resumirla de la siguiente manera:
- Nodos afectados:todos los nodos para el ID de clúster 1 (3 nodos de base de datos y 1 nodo de ClusterControl).
- Consecuencia:no se podrá acceder a la máquina virtual de la que se está realizando la copia de seguridad hasta que finalice.
- Duración:cada operación de copia de seguridad de máquina virtual tarda entre 5 y 10 minutos en completarse.
- Frecuencia:la copia de seguridad de la máquina virtual está programada para ejecutarse diariamente, a partir de la 1:00 a. m. en el primer nodo.
Entonces podemos salir con un plan de ejecución para programar nuestro modo de mantenimiento:
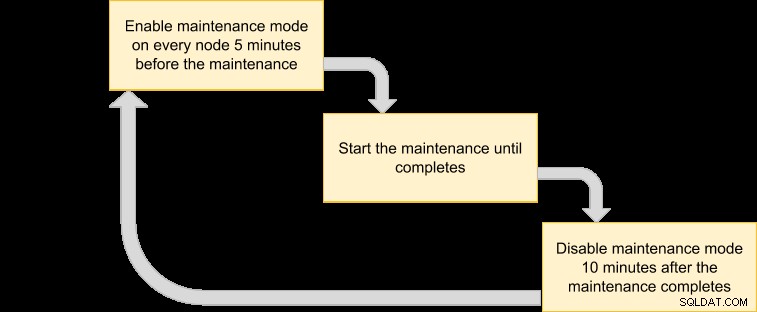
Dado que queremos que el administrador de VM haga una copia de seguridad de todos los nodos en el clúster, simplemente enumere los nodos para el ID de clúster correspondiente:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53El resultado anterior se puede utilizar para programar el mantenimiento en todo el clúster. Por ejemplo, si ejecuta el siguiente comando, ClusterControl activará el modo de mantenimiento para todos los nodos bajo el ID de clúster 1 desde ahora hasta los próximos 50 minutos:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneUsando el comando anterior, podemos convertirlo en un archivo de ejecución poniéndolo en un script. Crear un archivo:
$ vim /usr/local/bin/enable_maintenance_modeY agregue las siguientes líneas:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneGuárdelo y asegúrese de que el permiso del archivo sea ejecutable:
$ chmod 755 /usr/local/bin/enable_maintenance_modeLuego use cron para programar el script para que se ejecute de 5 minutos a la 1:00 a. m. todos los días, justo antes de que comience la operación de copia de seguridad de la máquina virtual a la 1:00 a. m.:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeVuelva a cargar el demonio cron para asegurarse de que nuestro script esté en cola:
$ systemctl reload crond # or service crond reloadEso es todo. Ahora podemos realizar nuestra operación de mantenimiento diario sin ser molestados por falsas alarmas y notificaciones por correo hasta que se complete el mantenimiento.
Característica de mantenimiento adicional:omitir la recuperación de nodos
Con la recuperación automática habilitada, ClusterControl es lo suficientemente inteligente como para detectar una falla de nodo e intentará recuperar un nodo fallido después de un período de gracia de 30 segundos, independientemente del estado del modo de mantenimiento. ¿Sabía que ClusterControl se puede configurar para omitir deliberadamente la recuperación de un nodo en particular? Esto podría ser muy útil cuando tenga que realizar un mantenimiento urgente sin conocer el período de tiempo y el resultado del mantenimiento.
Por ejemplo, imagine que se dañó un sistema de archivos y se requiere una verificación y reparación del sistema de archivos después de un reinicio completo. Es difícil determinar de antemano cuánto tiempo se necesitaría para completar esta operación. Por lo tanto, podemos simplemente usar un archivo de marca para señalar a ClusterControl que omita la recuperación del nodo.
En primer lugar, agregue la siguiente línea dentro de /etc/cmon.d/cmon_X.cnf (donde X es el ID del clúster) en el nodo ClusterControl:
node_recovery_lock_file=/root/do_not_recoverLuego, reinicie el servicio cmon para cargar el cambio:
$ systemctl restart cmon # service cmon restartFinalmente, asegúrese de que el archivo especificado esté presente en el nodo que queremos omitir para la recuperación de ClusterControl:
$ touch /root/do_not_recoverIndependientemente del estado del modo de mantenimiento y recuperación automática, ClusterControl solo recuperará el nodo cuando este archivo de marca no exista. Luego, el administrador es responsable de crear y eliminar el archivo en el nodo de la base de datos.
Eso es todo, amigos. ¡Feliz mantenimiento!



