Garantizar el buen funcionamiento de sus bases de datos de producción no es una tarea trivial, y hay una serie de herramientas y utilidades para ayudar con el trabajo. Hay herramientas disponibles para monitorear la salud, el rendimiento del servidor, analizar consultas, implementaciones, administrar la conmutación por error, actualizaciones y la lista continúa. ClusterControl como plataforma de administración y monitoreo para su infraestructura de base de datos se destaca por su capacidad para administrar el ciclo de vida completo desde la implementación hasta el monitoreo, la administración continua y el escalado.
Aunque ClusterControl ofrece características importantes como la conmutación por error automática de la base de datos, el cifrado en tránsito/en reposo, la gestión de copias de seguridad, la recuperación de un punto en el tiempo, la integración de Prometheus, el escalado de la base de datos, estas se pueden encontrar en otras herramientas de gestión/supervisión empresarial en el mercado. Sin embargo, hay algunas características que no encontrará tan fácilmente. En esta publicación de blog, presentaremos 9 características que no encontrará en ninguna otra herramienta de administración y monitoreo en el mercado (al momento de escribir este artículo).
Verificación de copia de seguridad
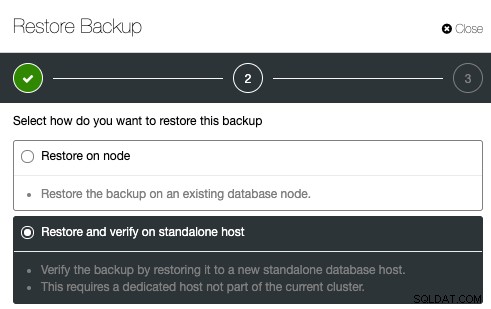
Cualquier copia de seguridad literalmente no es una copia de seguridad hasta que sepa que se puede recuperar, al verificar realmente que se puede recuperar. ClusterControl permite que se verifique una copia de seguridad después de que se haya realizado girando un nuevo servidor y probando la restauración. La verificación de una copia de seguridad es un proceso crítico para asegurarse de cumplir con su política de objetivo de punto de recuperación (RPO) en caso de recuperación ante desastres. El proceso de verificación realizará la restauración en un nuevo host independiente (donde ClusterControl instalará los paquetes de base de datos necesarios antes de la restauración) o en un servidor dedicado para la verificación de copias de seguridad.
Para configurar la verificación de la copia de seguridad, simplemente seleccione una copia de seguridad existente y haga clic en Restaurar. Habrá una opción para Restaurar y Verificar:
Luego, simplemente especifique la dirección IP del servidor que desea restaurar y verificar:
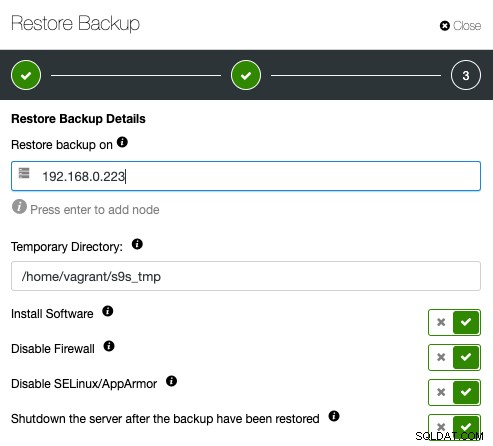
Asegúrese de que se pueda acceder al host especificado a través de SSH sin contraseña de antemano. También tiene un puñado de opciones debajo para el proceso de aprovisionamiento. También puede apagar el servidor de verificación después de la restauración para ahorrar costos y recursos una vez que se haya verificado la copia de seguridad. ClusterControl buscará el código de salida del proceso de restauración y observará el registro de restauración para verificar si la verificación falla o tiene éxito.
Simplificación de la administración de ProxySQL a través de una GUI
Muchos estarían de acuerdo en que tener una interfaz gráfica de usuario es más eficiente y menos propenso a errores humanos al configurar un sistema. ProxySQL es una parte de la capa crítica de la base de datos (aunque se encuentra encima de ella) y debe ser lo suficientemente visible a los ojos del DBA para detectar problemas y problemas comunes. ClusterControl proporciona una interfaz gráfica de usuario integral para ProxySQL.
Las instancias de ProxySQL se pueden implementar en hosts nuevos o las existentes se pueden importar a ClusterControl. ClusterControl puede configurar ProxySQL para que se integre con una dirección IP virtual (proporcionada por Keepalived) para el acceso de punto final único a los servidores de la base de datos. También proporciona información de monitoreo de los componentes clave de ProxySQL, como el backend de consultas, las consultas lentas, las consultas principales, los resultados de consultas y muchas otras estadísticas de monitoreo. La siguiente es una captura de pantalla que muestra cómo agregar una nueva regla de consulta:
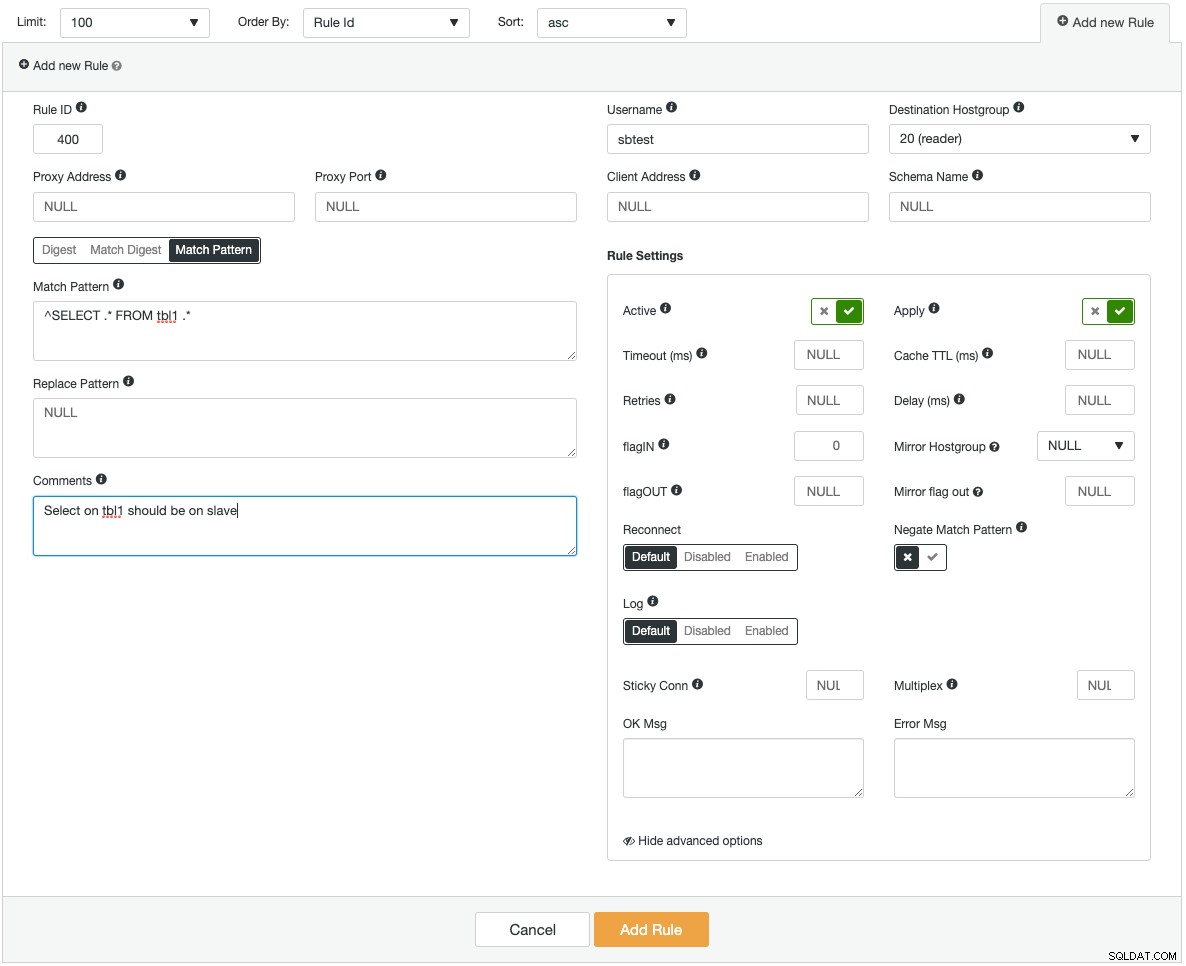
Si estuviera agregando una regla de consulta muy compleja, se sentiría más cómodo haciéndolo a través de la interfaz gráfica de usuario. Cada campo tiene una información sobre herramientas para ayudarlo a completar el formulario de regla de consulta. Al agregar o modificar cualquier configuración de ProxySQL, ClusterControl se asegurará de que los cambios se realicen en tiempo de ejecución y se guarden en el disco para persistencia.
ClusterControl 1.7.4 ahora es compatible con ProxySQL 1.x y ProxySQL 2.x.
Informes operativos
Los informes operativos son un conjunto de informes resumidos de la infraestructura de su base de datos que se pueden generar sobre la marcha o se pueden programar para enviarse a diferentes destinatarios. Estos informes consisten en diferentes controles y abordan varias tareas diarias de DBA. La idea detrás de los informes operativos de ClusterControl es poner todos los datos más relevantes en un solo documento que se pueda analizar rápidamente para obtener una comprensión clara del estado de las bases de datos y sus procesos.
Con ClusterControl puede programar informes de entornos de clústeres cruzados, como el informe diario del sistema, el informe de actualización de paquetes, el informe de cambio de esquema, así como las copias de seguridad y la disponibilidad. Estos informes le ayudarán a mantener su entorno seguro y operativo. También verá recomendaciones sobre cómo corregir las lagunas. Los informes se pueden enviar a SysOps, DevOps o incluso a los administradores que deseen recibir actualizaciones periódicas sobre el estado de un sistema determinado.
El siguiente es un ejemplo del informe operativo diario enviado a su buzón con respecto a la disponibilidad:
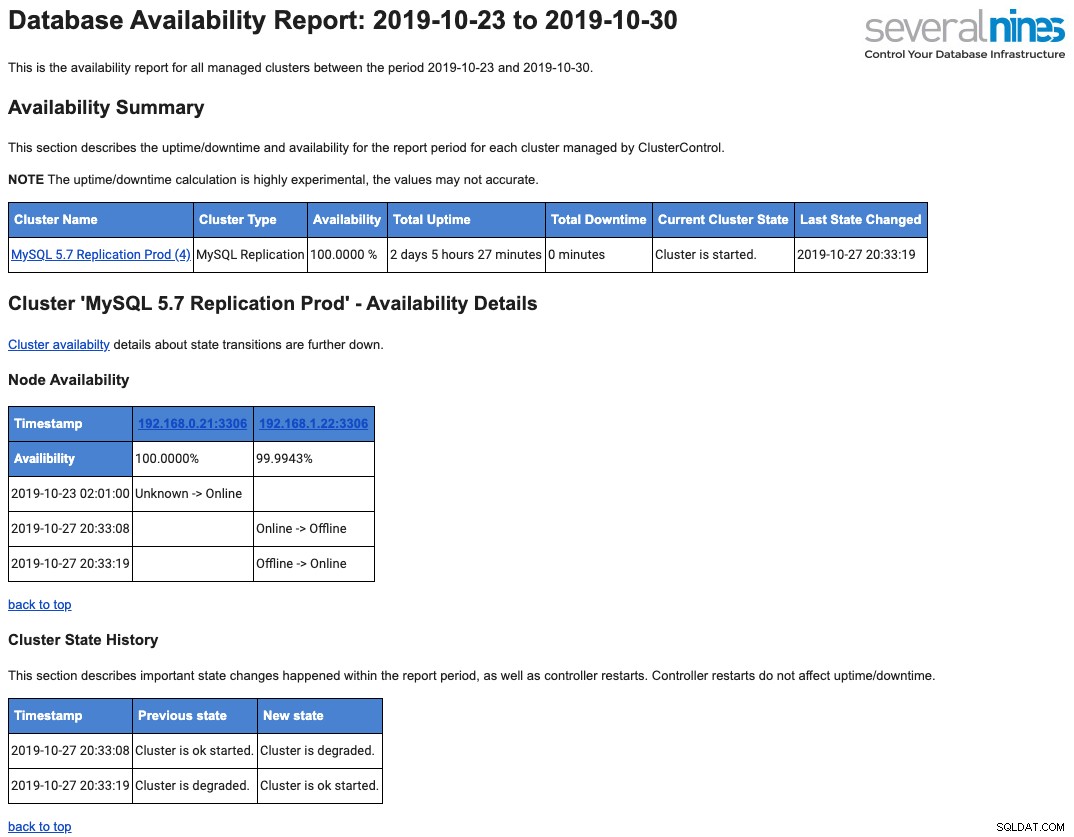
Hemos cubierto esto en detalle en esta publicación de blog, Una descripción general de los informes operativos de la base de datos en ClusterControl.
Resincronizar un esclavo mediante copia de seguridad
ClusterControl permite organizar un esclavo (ya sea un esclavo nuevo o un esclavo roto) a través de la copia de seguridad incremental o completa más reciente. No suena muy emocionante, pero esta característica es enorme si tiene grandes conjuntos de datos de 100 GB o más. La práctica común al resincronizar un esclavo es transmitir una copia de seguridad del maestro actual, lo que llevará algún tiempo dependiendo del tamaño de la base de datos. Esto agregará una carga adicional al maestro, lo que puede poner en peligro el desempeño del maestro.
Para resincronizar un esclavo a través de una copia de seguridad, elija el nodo esclavo en la página Nodos y vaya a Acciones de nodo -> Reconstruir esclavo de replicación -> Reconstruir desde una copia de seguridad. Solo la copia de seguridad compatible con PITR aparecerá en el menú desplegable:
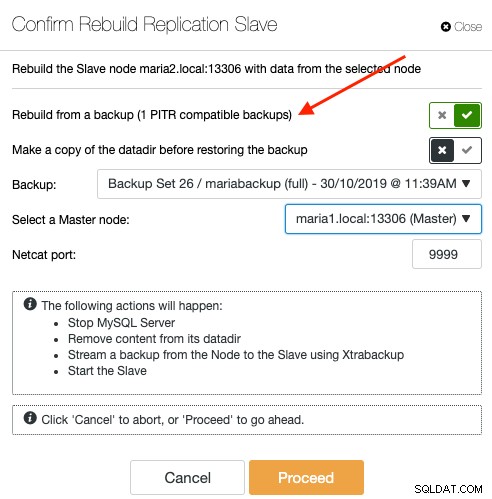
La resincronización de un esclavo desde una copia de seguridad no generará ninguna sobrecarga adicional para el maestro, donde ClusterControl extrae y transmite la copia de seguridad desde la ubicación de almacenamiento de la copia de seguridad al esclavo y, finalmente, configura el enlace de replicación entre el esclavo y el maestro. El esclavo luego se pondrá al día con el maestro una vez que se establezca el enlace de replicación. El maestro no se toca durante todo el proceso, y puede monitorear todo el progreso en Actividad -> Trabajos.
Arrancar un clúster de Galera
Galera Cluster es muy popular cuando se implementa alta disponibilidad para MySQL o MariaDB, pero los comandos de administración incorrectos pueden tener consecuencias desastrosas. Eche un vistazo a esta publicación de blog sobre cómo iniciar un Galera Cluster en diferentes condiciones. Esto ilustra que el arranque de un Galera Cluster tiene muchas variables y debe realizarse con sumo cuidado. De lo contrario, puede perder datos o causar un cerebro dividido. ClusterControl comprende la topología de la base de datos y sabe exactamente qué hacer para iniciar correctamente un clúster de base de datos. Para arrancar un clúster a través de ClusterControl, haga clic en Acciones del clúster -> Clúster de arranque:
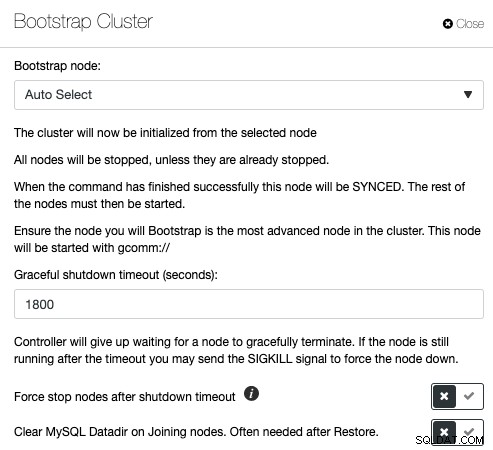
Tendrá la opción de permitir que ClusterControl seleccione el nodo de arranque correcto automáticamente, o realice un arranque inicial en el que elija uno de los nodos de la base de datos de la lista para que se convierta en el nodo de referencia y elimine el directorio de datos MySQL en los nodos de unión para forzar el SST. el nodo de arranque. Si el proceso de arranque falla, ClusterControl extraerá el registro de errores de MySQL.
Si desea realizar un arranque manual, también puede usar la función "Buscar el nodo más avanzado" y realizar la operación de arranque del clúster en el nodo más avanzado informado por ClusterControl.
Configuración y registro centralizados
ClusterControl extrae una serie de archivos de registro y configuración importantes y los muestra en una estructura de árbol dentro de ClusterControl. Una vista centralizada de estos archivos es clave para comprender y solucionar de manera eficiente las configuraciones de bases de datos distribuidas. La forma tradicional de rastrear/agrupar estos archivos hace mucho tiempo que desapareció con ClusterControl. La siguiente captura de pantalla muestra el administrador de archivos de configuración de ClusterControl que enumera todos los archivos de configuración relacionados para este clúster en una sola vista (con resaltado de sintaxis, por supuesto):
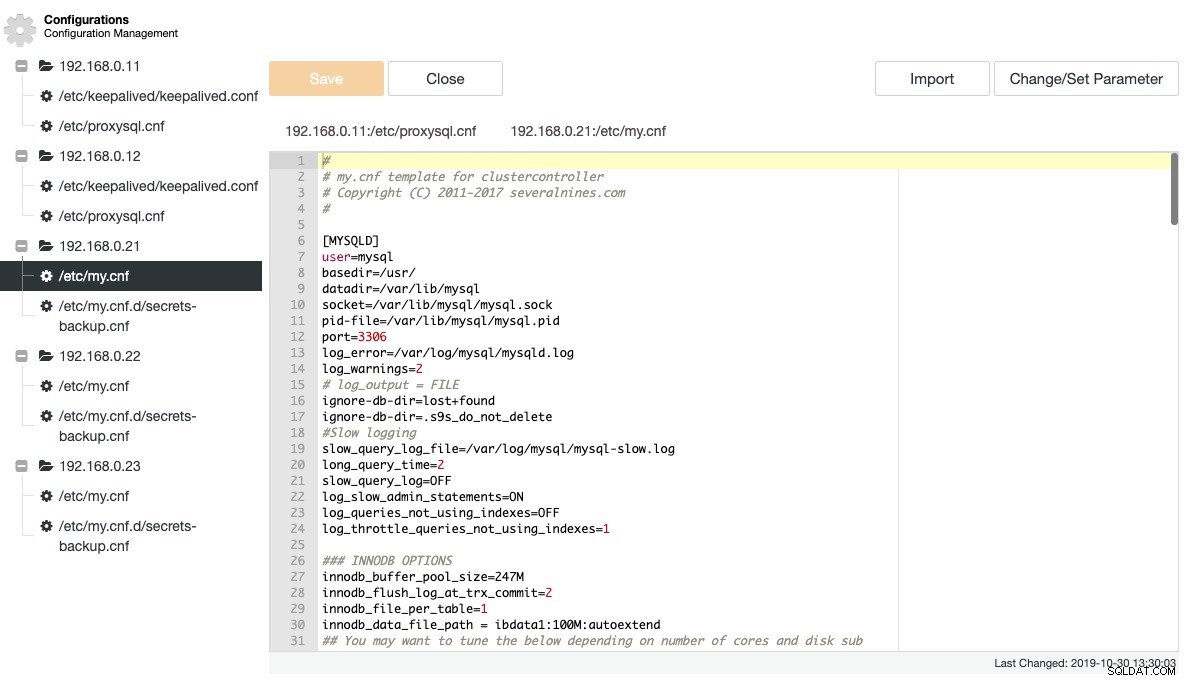
ClusterControl elimina la repetitividad al cambiar una opción de configuración de un clúster de base de datos. El cambio de una opción de configuración en varios nodos se puede realizar a través de una sola interfaz y se aplicará al nodo de la base de datos en consecuencia. Cuando hace clic en "Cambiar/Establecer parámetro", puede seleccionar las instancias de la base de datos que le gustaría cambiar y especificar el grupo de configuración, el parámetro y el valor:
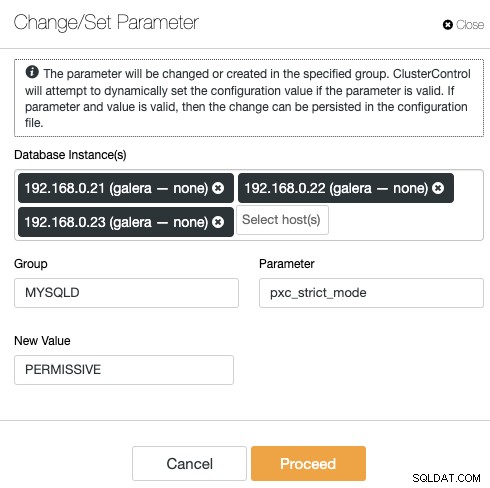
Puede agregar un nuevo parámetro en el archivo de configuración o modificar un parámetro existente . El parámetro se aplicará al tiempo de ejecución de los nodos de la base de datos elegidos y al archivo de configuración si la opción pasa el proceso de validación de variables. Algunas variables pueden requerir un reinicio del servidor, que luego será informado por ClusterControl.
Clonación de clústeres de bases de datos
Con ClusterControl, puede clonar rápidamente un clúster MySQL Galera existente para tener una copia exacta del conjunto de datos en el otro clúster. ClusterControl realiza la operación de clonación en línea, sin bloqueos ni tiempos de inactividad en el clúster existente. Es como una operación de escalamiento horizontal del clúster, excepto que ambos clústeres son independientes entre sí una vez que se completa la sincronización. No es necesario que el clúster clonado tenga el mismo tamaño de clúster que el existente. Podríamos comenzar con un "clúster de un nodo" y ampliarlo con más nodos de base de datos en una etapa posterior.
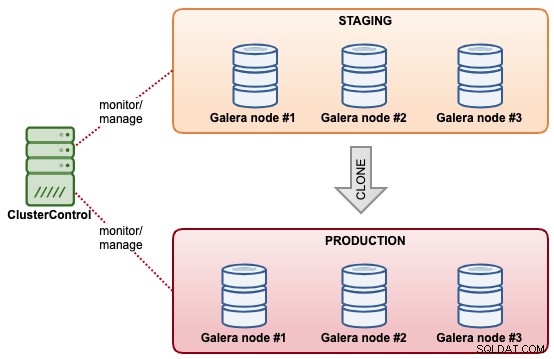
Otra función similar que ofrece ClusterControl es "Crear clúster desde copia de seguridad". Esta función se introdujo en ClusterControl 1.7.1, específicamente para los clústeres Galera Cluster y PostgreSQL, donde se puede crear un nuevo clúster a partir de la copia de seguridad existente. A diferencia de la clonación de clústeres, esta operación no genera una carga adicional para el clúster de origen con la contrapartida de que el clúster clonado no estará en el mismo estado que el clúster de origen.
Hemos tratado este tema en detalle en esta publicación de blog, Cómo crear un clon de su clúster de base de datos MySQL o PostgreSQL.
Restaurar copia de seguridad física
La mayoría de las herramientas de administración de bases de datos permiten realizar una copia de seguridad de una base de datos, y solo unas pocas admiten la restauración de la base de datos únicamente de la copia de seguridad lógica. ClusterControl admite la restauración completa no solo para las copias de seguridad lógicas, sino también para las copias de seguridad físicas, ya sea una copia de seguridad completa o incremental. La restauración de una copia de seguridad física requiere una serie de pasos críticos (especialmente las copias de seguridad incrementales) que básicamente implican preparar una copia de seguridad, copiar los datos preparados en el directorio de datos, asignar el permiso/propiedad correctos e iniciar el nodo en el orden correcto para mantener la coherencia de los datos en todo el proceso. todos los miembros del clúster. ClusterControl realiza todas estas operaciones automáticamente.
También puede restaurar una copia de seguridad física en otro nodo que no sea parte de un clúster. En ClusterControl, la opción para esto se llama "Crear clúster desde la copia de seguridad". Puede comenzar con un "clúster de un nodo" para probar el proceso de restauración en otro servidor o para copiar su clúster de base de datos a otra ubicación.
ClusterControl también admite la restauración de una copia de seguridad externa, una copia de seguridad que no se haya realizado a través de ClusterControl. Solo necesita cargar la copia de seguridad en el servidor de ClusterControl y especificar la ruta física al archivo de copia de seguridad al restaurar. ClusterControl se encargará del resto.
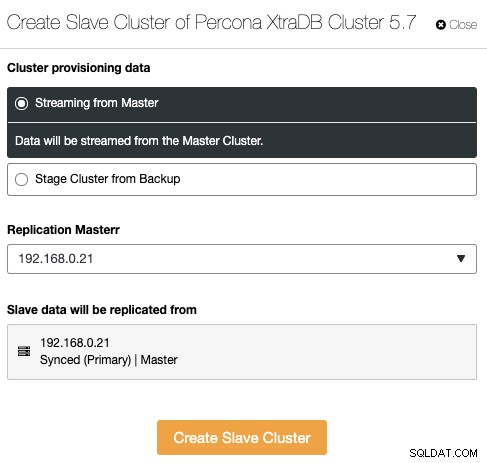
Replicación de clúster a clúster
Esta es una nueva característica introducida en ClusterControl 1.7.4. ClusterControl ahora puede manejar y monitorear la replicación de clúster a clúster, lo que básicamente extiende la replicación asíncrona de la base de datos entre múltiples conjuntos de clústeres en múltiples ubicaciones geográficas. Un clúster se puede configurar como clúster maestro (clúster activo que procesa lecturas/escrituras) y el clúster esclavo se puede configurar como clúster de solo lectura (clúster en espera que también puede procesar lecturas). ClusterControl admite la replicación asíncrona de clúster a clúster para Galera Cluster (el registro binario debe estar habilitado) y también la replicación maestro-esclavo para PostgreSQL Streaming Replication.
Para crear un nuevo clúster, las réplicas de otro clúster, vaya a Acciones del clúster -> Crear clúster esclavo:
El resultado de la implementación anterior se presenta claramente en el panel de la lista de clústeres de la base de datos :
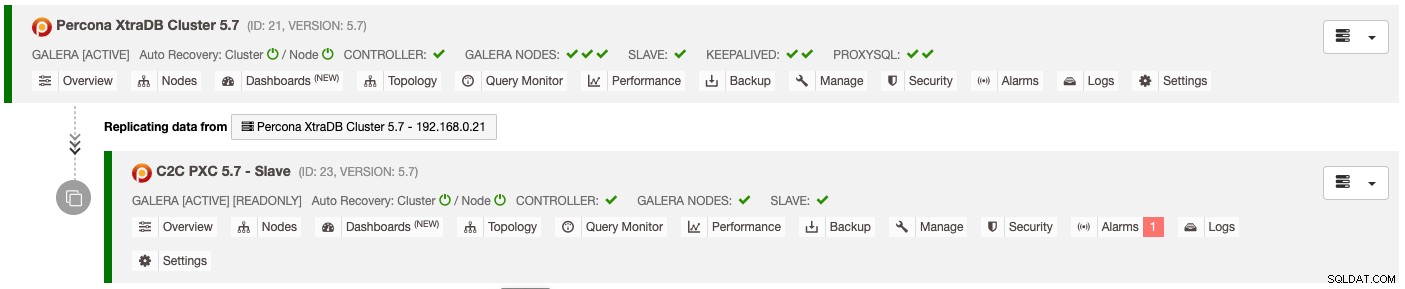
El clúster esclavo se configura automáticamente como de solo lectura, se replica desde el clúster principal y actúa como un clúster en espera. Si ocurre un desastre en el clúster principal y desea activar el sitio secundario, simplemente elija el menú "Deshabilitar solo lectura" disponible en el menú desplegable Nodos -> Acciones de nodo para promoverlo como un clúster activo.



