ClusterControl está programado con varios algoritmos de recuperación para responder automáticamente a diferentes tipos de fallas comunes que afectan sus sistemas de base de datos. Comprende diferentes tipos de topologías de base de datos y gestión de procesos relacionados con la base de datos para ayudarlo a determinar la mejor manera de recuperar el clúster. En cierto modo, ClusterControl mejora la disponibilidad de su base de datos.
Algunos administradores de topología solo cubren la recuperación de clústeres como MHA, Orchestrator y mysqlfailover, pero usted debe manejar la recuperación de nodos usted mismo. ClusterControl admite la recuperación tanto a nivel de clúster como de nodo.
Opciones de configuración
Hay dos componentes de recuperación compatibles con ClusterControl, a saber:
- Clúster:intento de recuperar un clúster a un estado operativo
- Nodo:intento de recuperar un nodo a un estado operativo
Estos dos componentes son los más importantes para garantizar que la disponibilidad del servicio sea lo más alta posible. Si ya tiene un administrador de topología además de ClusterControl, puede deshabilitar la función de recuperación automática y dejar que otro administrador de topología lo maneje por usted. Tienes todas las posibilidades con ClusterControl.
La función de recuperación automática se puede habilitar y deshabilitar con un simple encendido/apagado, y funciona para la recuperación de clústeres o nodos. Los íconos verdes significan habilitados y los íconos rojos significan deshabilitados. La siguiente captura de pantalla muestra dónde puede encontrarlo en la lista de clústeres de la base de datos:
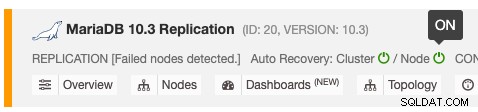
Hay 3 parámetros de ClusterControl que se pueden usar para controlar el comportamiento de recuperación. Todos los parámetros son predeterminados como verdaderos (establecidos con un entero booleano 0 o 1):
- enable_autorecovery:habilita la recuperación de clústeres y nodos. Este parámetro es el superconjunto de enable_cluster_recovery y enable_node_recovery. Si se establece en 0, los parámetros del subconjunto se desactivarán.
- enable_cluster_recovery:ClusterControl realizará la recuperación del clúster si está habilitado.
- enable_node_recovery - ClusterControl realizará la recuperación del nodo si está habilitado.
La recuperación de clúster cubre el intento de recuperación para recuperar la topología de clúster completa. Por ejemplo, una replicación maestro-esclavo debe tener al menos un maestro vivo en un momento dado, independientemente de la cantidad de esclavos disponibles. ClusterControl intenta corregir la topología al menos una vez para los clústeres de replicación, pero infinitamente para la replicación multimaestro como NDB Cluster y Galera Cluster.
La recuperación de nodos cubre el problema de recuperación de nodos, como si un nodo se detuviera sin el conocimiento de ClusterControl, por ejemplo, a través del comando de detención del sistema desde la consola SSH o si el proceso OOM lo elimina.
Recuperación de nodos
ClusterControl puede recuperar un nodo de la base de datos en caso de falla intermitente al monitorear el proceso y la conectividad a los nodos de la base de datos. Para el proceso, funciona de manera similar a systemd, donde se asegurará de que el servicio MySQL se inicie y se ejecute a menos que lo haya detenido intencionalmente a través de la interfaz de usuario de ClusterControl.
Si el nodo vuelve a estar en línea, ClusterControl establecerá una conexión con el nodo de la base de datos y realizará las acciones necesarias. Lo siguiente es lo que haría ClusterControl para recuperar un nodo:
- Esperará a que systemd/chkconfig/init inicie los servicios/procesos monitoreados durante 30 segundos
- Si los servicios/procesos monitoreados aún están inactivos, ClusterControl intentará iniciar el servicio de la base de datos automáticamente.
- Si ClusterControl no puede recuperar los servicios/procesos monitoreados, se generará una alarma.
Tenga en cuenta que si el usuario inicia el cierre de una base de datos, ClusterControl no intentará recuperar el nodo en particular. Espera que el usuario vuelva a iniciarlo a través de la interfaz de usuario de ClusterControl yendo a Nodo -> Acciones de nodo -> Iniciar nodo o use el comando del sistema operativo explícitamente.
La recuperación incluye todos los servicios relacionados con la base de datos como ProxySQL, HAProxy, MaxScale, Keepalived, Prometheus exporters y garbd. Especial atención a los exportadores Prometheus donde ClusterControl utiliza un programa llamado "daemon" para demonizar el proceso exportador. ClusterControl intentará conectarse al puerto de escucha del exportador para verificar y verificar el estado. Por lo tanto, se recomienda abrir los puertos del exportador desde el servidor ClusterControl y Prometheus para asegurarse de que no haya falsas alarmas durante la recuperación.
Recuperación de clúster
ClusterControl comprende la topología de la base de datos y sigue las mejores prácticas para realizar la recuperación. Para un clúster de base de datos que viene con tolerancia a fallas incorporada como Galera Cluster, NDB Cluster y MongoDB Replicaset, el servidor de la base de datos realizará automáticamente el proceso de conmutación por error a través del cálculo del quórum, el latido y el cambio de roles (si corresponde). ClusterControl supervisa el proceso y realiza los ajustes necesarios en la visualización, como reflejar los cambios en la vista de topología y ajustar el componente de supervisión y gestión para la nueva función, por ejemplo, un nuevo nodo principal en un conjunto de réplicas.
Para las tecnologías de bases de datos que no tienen tolerancia a fallas incorporada con recuperación automática como MySQL/MariaDB Replication y PostgreSQL/TimescaleDB Streaming Replication, ClusterControl realizará los procedimientos de recuperación siguiendo las mejores prácticas proporcionadas por el proveedor de base de datos. Si la recuperación falla, se requiere la intervención del usuario y, por supuesto, recibirá una notificación de alarma al respecto.
En una topología mixta/híbrida, por ejemplo, un esclavo asíncrono que está conectado a un clúster Galera o un clúster NDB, ClusterControl recuperará el nodo si la recuperación del clúster está habilitada.
La recuperación de clúster no se aplica al servidor MySQL independiente. Sin embargo, se recomienda activar las recuperaciones de nodos y clústeres para este tipo de clúster en la interfaz de usuario de ClusterControl.
Replicación MySQL/MariaDB
ClusterControl admite la recuperación de la siguiente configuración de replicación de MySQL/MariaDB:
- Maestro-esclavo con MySQL GTID
- Maestro-esclavo con MariaDB GTID
- Maestro-esclavo sin GTID (tanto MySQL como MariaDB)
- Maestro-maestro con MySQL GTID
- Maestro-maestro con MariaDB GTID
- Esclavo asíncrono conectado a un clúster Galera
ClusterControl respetará los siguientes parámetros al realizar la recuperación del clúster:
- habilitar_clúster_recuperación automática
- auto_manage_readonly
- repl_contraseña
- repl_usuario
- replicación_auto_reconstrucción_esclavo
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replicación_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replicación_pre_failover_script
- replicación_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Para obtener más detalles sobre cada uno de los parámetros, consulte la página de documentación.
ClusterControl obedecerá las siguientes reglas al monitorear y administrar una replicación maestro-esclavo:
- Todos los nodos se iniciarán con read_only=ON y super_read_only=ON (independientemente de su rol).
- Solo un maestro (read_only=OFF) puede operar en un momento dado.
- Confíe en la variable de MySQL report_host para mapear la topología.
- Si hay dos o más nodos que tienen read_only=OFF a la vez, ClusterControl configurará automáticamente read_only=ON en ambos maestros, para protegerlos contra escrituras accidentales. Se requiere la intervención del usuario para elegir el maestro real al deshabilitar el modo de solo lectura. Vaya a Nodos -> Acciones de nodo -> Deshabilitar solo lectura.
En caso de que el maestro activo se caiga, ClusterControl intentará realizar la conmutación por error del maestro en el siguiente orden:
- Después de 3 segundos de inaccesibilidad del maestro, ClusterControl activará una alarma.
- Verifique la disponibilidad del esclavo, al menos uno de los esclavos debe ser accesible por ClusterControl.
- Elige al esclavo como candidato a maestro.
- ClusterControl calculará la probabilidad de transacciones erróneas si GTID está habilitado.
- Si no se detecta ninguna transacción errónea, el elegido será promovido como nuevo maestro.
- Crear y otorgar un usuario de replicación para ser utilizado por los esclavos.
- Cambiar maestro para todos los esclavos que apuntaban al maestro antiguo al maestro recién ascendido.
- Iniciar esclavo y habilitar solo lectura.
- Vaciar registros en todos los nodos.
- Si falla la promoción del esclavo, ClusterControl cancelará el trabajo de recuperación. Se requiere la intervención del usuario o un reinicio del servicio cmon para activar el trabajo de recuperación nuevamente.
- Cuando el maestro antiguo vuelva a estar disponible, se iniciará como de solo lectura y no formará parte de la replicación. Se requiere la intervención del usuario.
Al mismo tiempo, se generarán las siguientes alarmas:
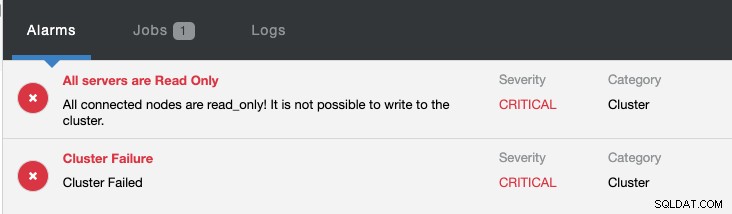
Consulte Introducción a la conmutación por error para la replicación de MySQL:el blog 101 y la conmutación por error automática de la replicación de MySQL:nuevo en ClusterControl 1.4 para obtener más información sobre cómo configurar y administrar la conmutación por error de la replicación de MySQL con ClusterControl.
Replicación de transmisión de PostgreSQL/TimescaleDB
ClusterControl admite la recuperación de la siguiente configuración de replicación de PostgreSQL:
- Replicación de transmisión de PostgreSQL
- Replicación de transmisión de TimescaleDB
ClusterControl respetará los siguientes parámetros al realizar la recuperación del clúster:
- habilitar_clúster_recuperación automática
- repl_contraseña
- repl_usuario
- replicación_auto_reconstrucción_esclavo
- replication_failover_whitelist
- replication_failover_blacklist
Para obtener más detalles sobre cada uno de los parámetros, consulte la página de documentación.
ClusterControl obedecerá las siguientes reglas para administrar y monitorear una configuración de replicación de transmisión de PostgreSQL:
- wal_level se establece en "réplica" (o "hot_standby" según la versión de PostgreSQL).
- La variable archive_mode está activada en el maestro.
- Establezca el archivo recovery.conf en los nodos esclavos, lo que convierte el nodo en un modo de espera activo con solo lectura habilitado.
En caso de que el maestro activo se caiga, ClusterControl intentará realizar la recuperación del clúster en el siguiente orden:
- Después de 10 segundos de inaccesibilidad del maestro, ClusterControl activará una alarma.
- Después de 10 segundos de tiempo de espera correcto, ClusterControl iniciará el trabajo maestro de conmutación por error.
- Muestree la ubicación de reproducción y la ubicación de recepción en todos los nodos disponibles para determinar el nodo más avanzado.
- Promueva el nodo más avanzado como el nuevo maestro.
- Detener esclavos.
- Verifique el estado de sincronización con pg_rewind.
- Reiniciando esclavos con el nuevo maestro.
- Si falla la promoción del esclavo, ClusterControl cancelará el trabajo de recuperación. Se requiere la intervención del usuario o un reinicio del servicio cmon para activar el trabajo de recuperación nuevamente.
- Cuando el maestro antiguo vuelva a estar disponible, se verá obligado a cerrarse y no formará parte de la replicación. Se requiere la intervención del usuario. Ver más abajo.
Cuando el antiguo maestro vuelve a estar en línea, si el servicio PostgreSQL se está ejecutando, ClusterControl forzará el cierre del servicio PostgreSQL. Esto es para proteger el servidor de escrituras accidentales, ya que se iniciaría sin un archivo de recuperación (recovery.conf), lo que significa que se podría escribir. Debe esperar que aparezcan las siguientes líneas en postgresql-{day}.log:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL se inició después de que el servidor volvió a estar en línea alrededor de las 05:06:10, pero ClusterControl realiza un apagado rápido 17 segundos después de eso, alrededor de las 05:06:27. Si esto es algo que no le gustaría que fuera, puede deshabilitar la recuperación de nodos para este clúster momentáneamente.
Consulte Conmutación por error automática de la replicación de Postgres y Conmutación por error para la replicación de PostgreSQL 101 para obtener más información sobre cómo configurar y administrar la conmutación por error de la replicación de PostgreSQL con ClusterControl.
Conclusión
La recuperación automática de ClusterControl comprende la topología del clúster de la base de datos y puede recuperar un clúster inactivo o degradado a un clúster completamente operativo, lo que mejorará enormemente el tiempo de actividad del servicio de la base de datos. Pruebe ClusterControl ahora y logre sus nueves en SLA y disponibilidad de la base de datos. ¿No conoces tus nueves? Echa un vistazo a esta genial calculadora de nueves.



